
This content originally appeared on DEV Community and was authored by DEV Community
“Challenges faced to find the solution of how to create a redshift cluster, copy s3 data to redshift and query on the redshift console using a query editor”. I have checked various documents on how to do the configuration of the redshift cluster. I have found a way to copy the s3 bucket data to redshift using the command line interface. Also checked the redshift cluster console to run and monitor the queries using the query editor. In terms of cost and security perspective, pricing is based on compute nodes and also can be secured using the redshift encryption feature.
Amazon Redshift is a data warehouse product which forms part of the larger cloud-computing platform Amazon Web Services. It is built on top of technology from the massive parallel processing data warehouse company ParAccel, to handle large scale data sets and database migrations. Redshift differs from Amazon’s other hosted database offering, Amazon RDS, in its ability to handle analytic workloads on big data data sets stored by a column-oriented DBMS principle. Redshift allows up to 16 petabytes of data on a cluster compared to Amazon RDS’s maximum database size of 16TB.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and machine learning to deliver the best price performance at any scale.
In this post, you will get to know how to create a redshift cluster, copy s3 data to redshift and query on the redshift console using a query editor. Here I have used an ec2 server, a s3 bucket and IAM role with required permissions policy.
Prerequisites
You’ll need an Amazon EC2 Server for this post. Getting started with amazon EC2 provides instructions on how to launch an EC2 Server.
You’ll need an Amazon Simple Storage Service for this post. Getting started with Amazon Simple Storage Service provides instructions on how to create a bucket in simple storage service. For this blog, I assume that I have created a s3 bucket and a ec2 server.
Architecture Overview

The architecture diagram shows the overall deployment architecture with data flow, amazon redshift, ec2 server and s3 bucket.
Solution overview
The blog post consists of the following phases:
- Create Amazon Redshift Cluster with required IAM permissions of S3
- Attach required permissions policy in IAM role and copy of S3 data to Redshift Cluster
- Run Query in Redshift Cluster Console and Verify the Output with Monitoring parameters
- Resize of Redshift Cluster using Resize option
I have one ec2 server and a s3 bucket created as below →


Phase 1: Create Amazon Redshift Cluster with required IAM permissions of S3
- Open the amazon redshift console, click on create cluster. Give cluster name, choose production and size as dc2.large with 1 number of nodes. Give admin username, password and required IAM role. In the database configuration setting, enter the database name and port with the required parameter group. Create a subnet group with custom vpc. And leave other settings as default. Also can encrypt using encryption features and create a redshift cluster. Once gets redshift cluster is in an available state, we can check the properties and other settings.

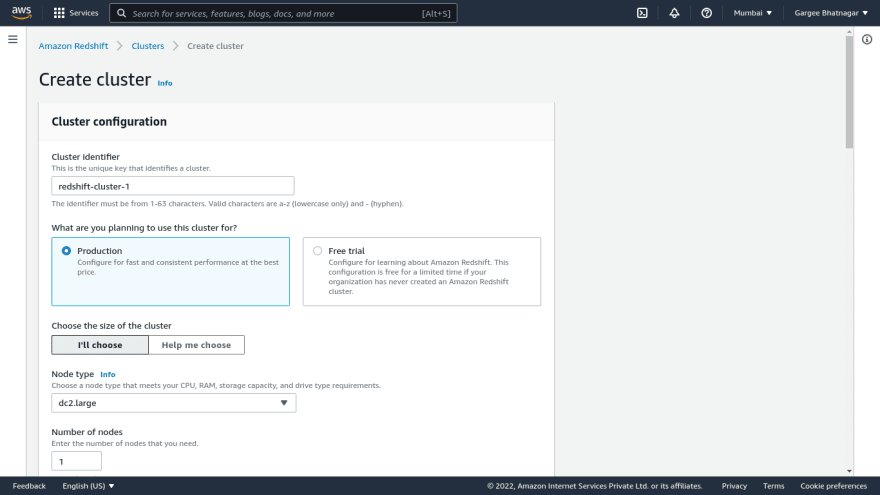
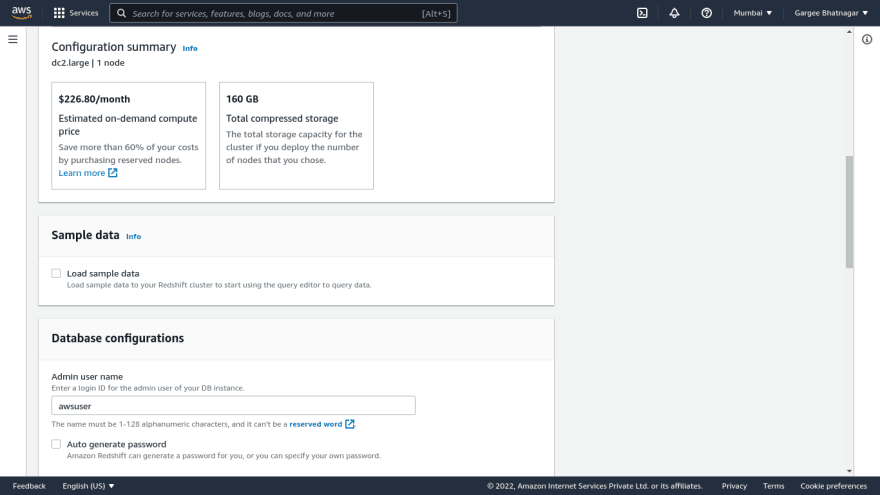
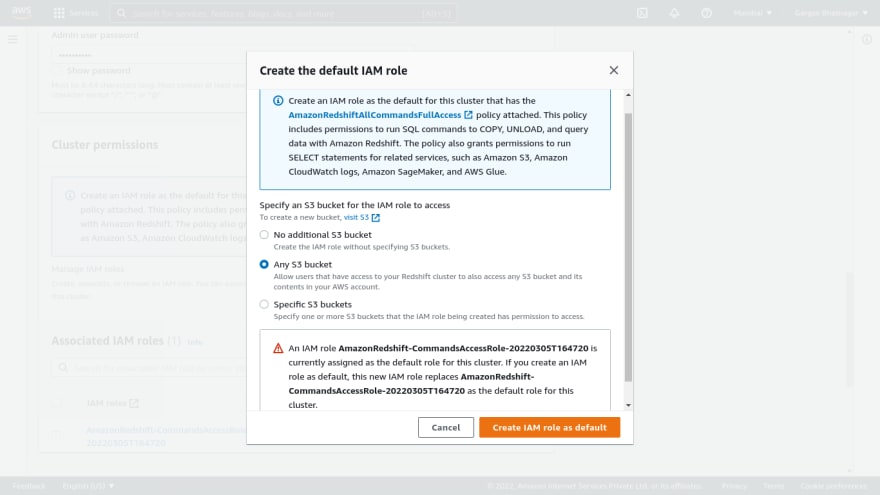
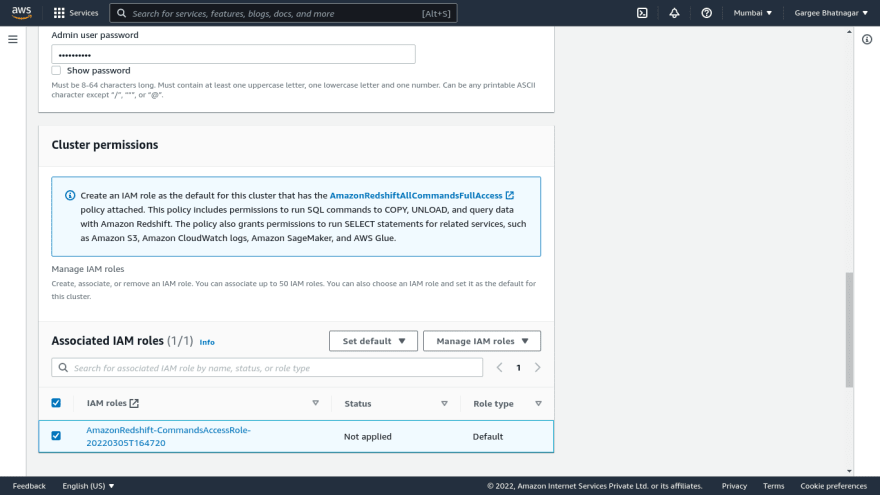



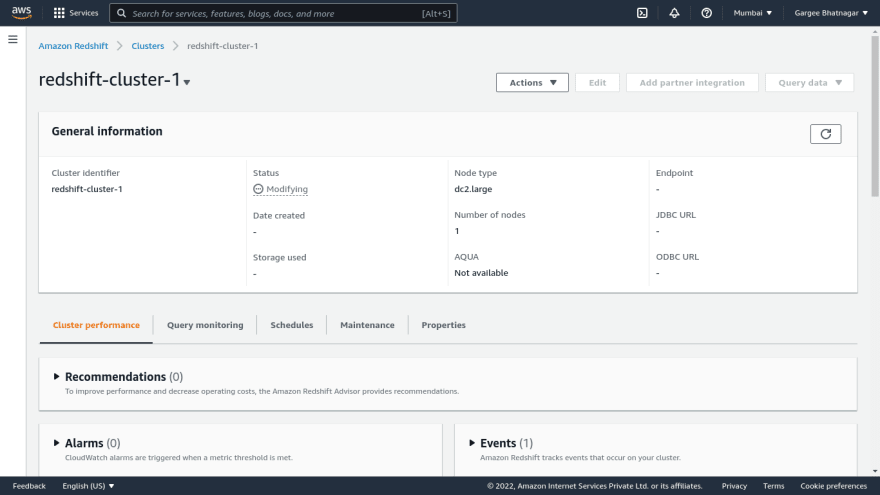

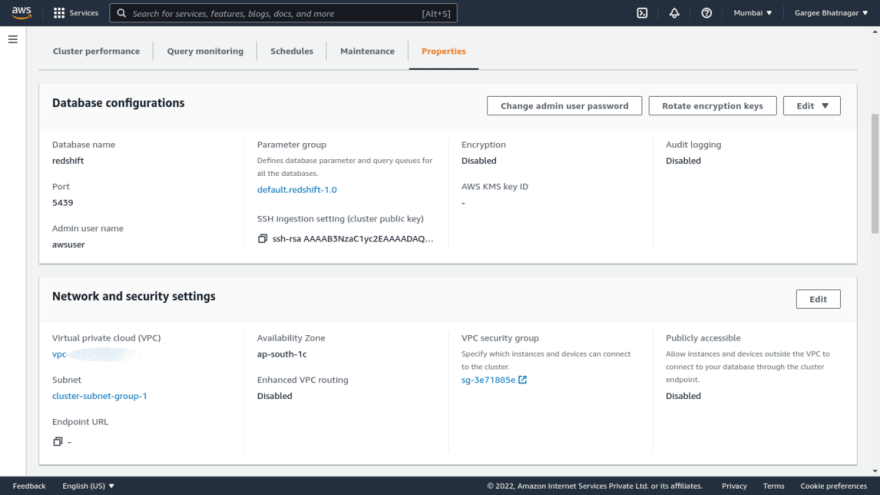
Phase 2: Attach required permissions policy in IAM role and copy of S3 data to Redshift Cluster
- Open the IAM role and attach required permissions policy. Login to ec2 server in terminal and install postgresql-12. Connect the redshift cluster using psql command with hostname, username, database name and port. Then create a table in a cluster using create table command. Also copy data from s3 to redshift with required IAM role arn and region.



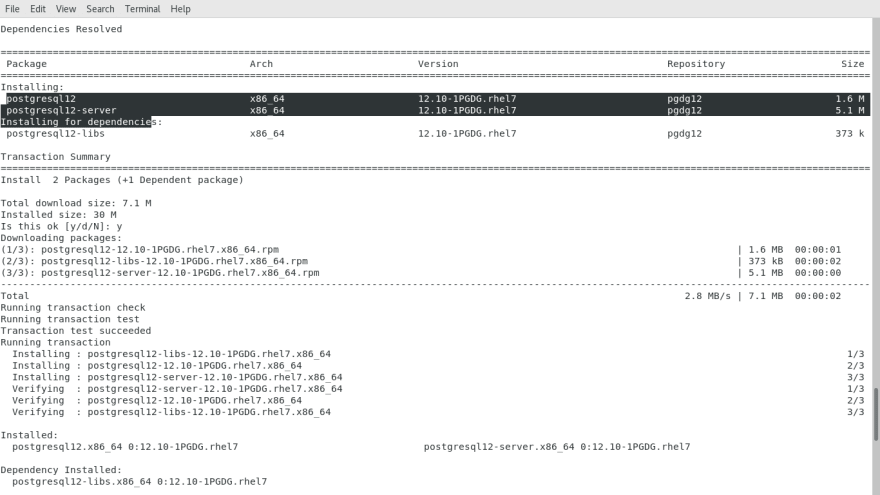


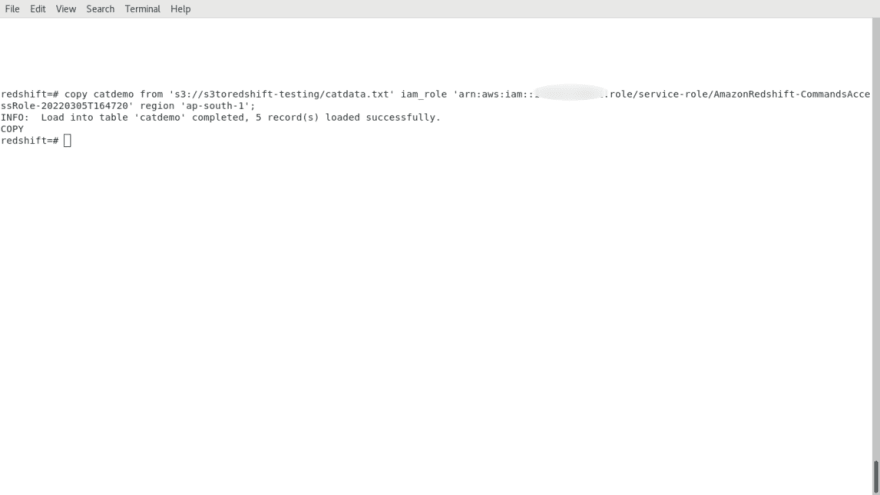
Phase 3: Run Query in Redshift Cluster Console and Verify the Output with Monitoring parameters
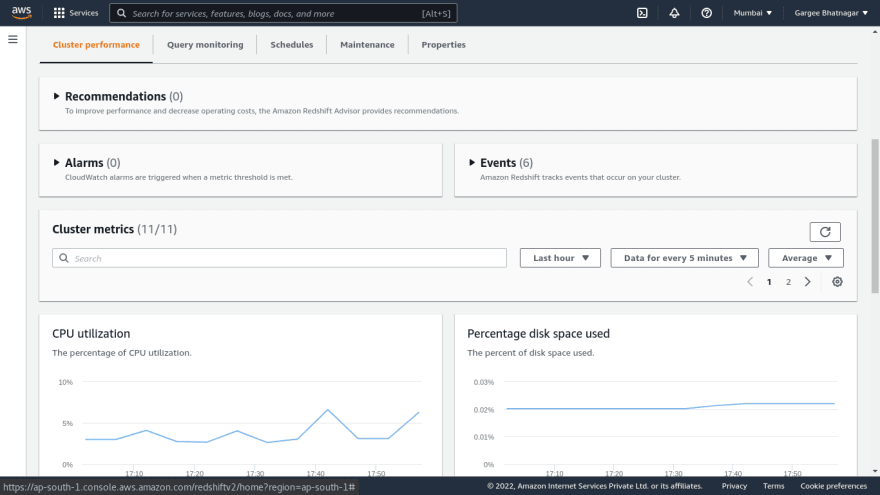
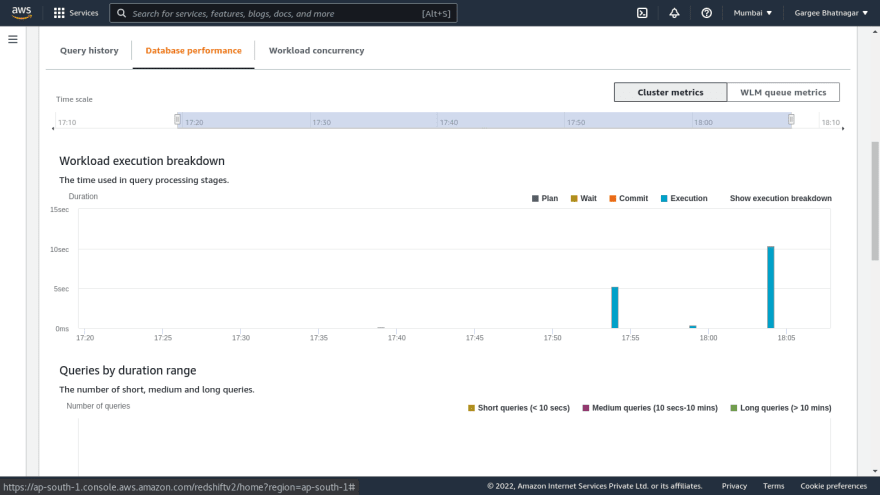
- Open the redshift cluster console and do a query in the redshift database using the query editor. Give the database details to connect it as database name and username.. Once connected to the database, run a query to select all from the table. Output result of the query shows the rows returned. We can also check the output of execution and visualize. Also can check other parameters of monitoring from the redshift console.
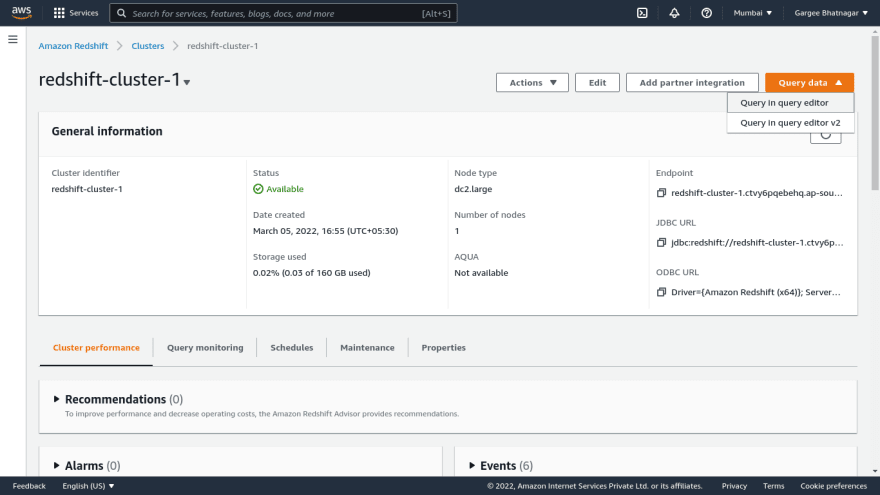
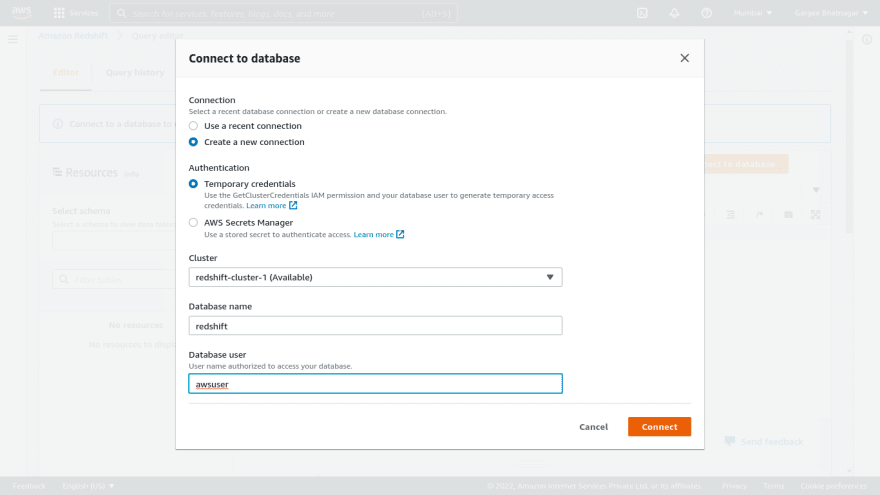
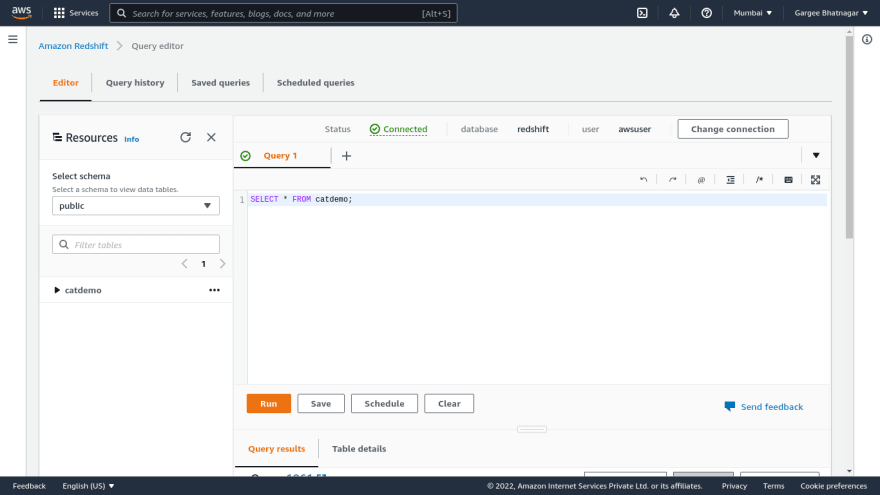

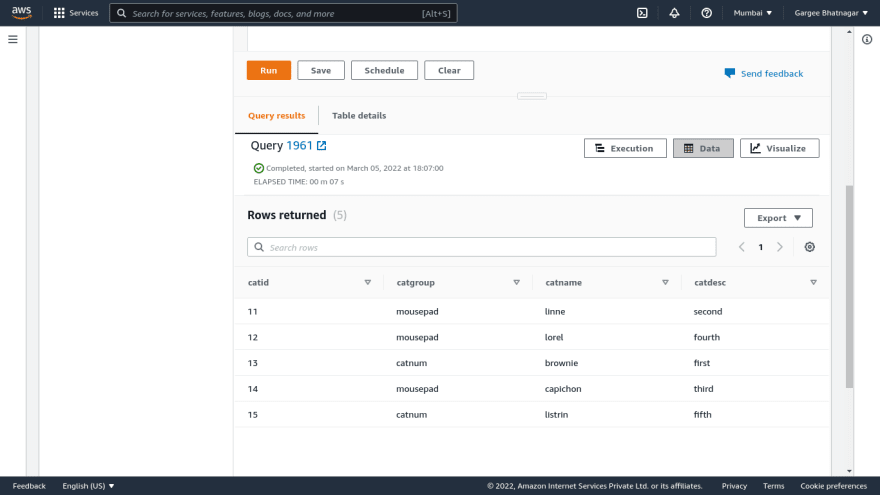
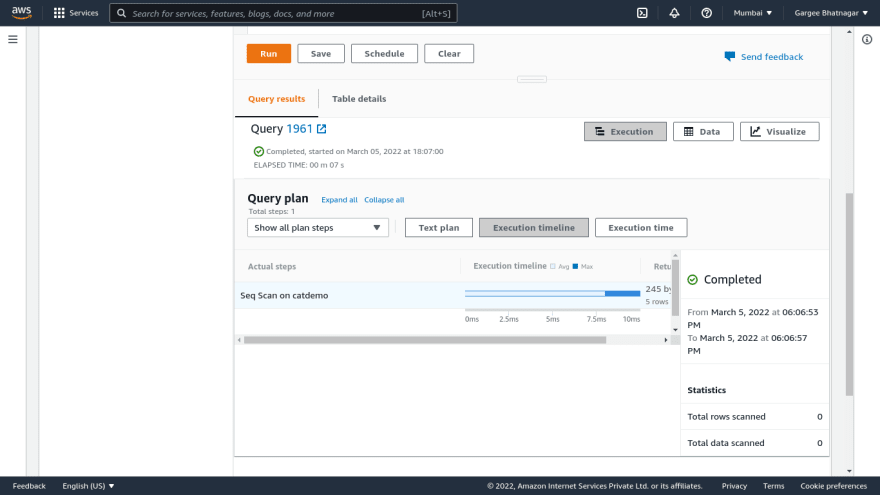
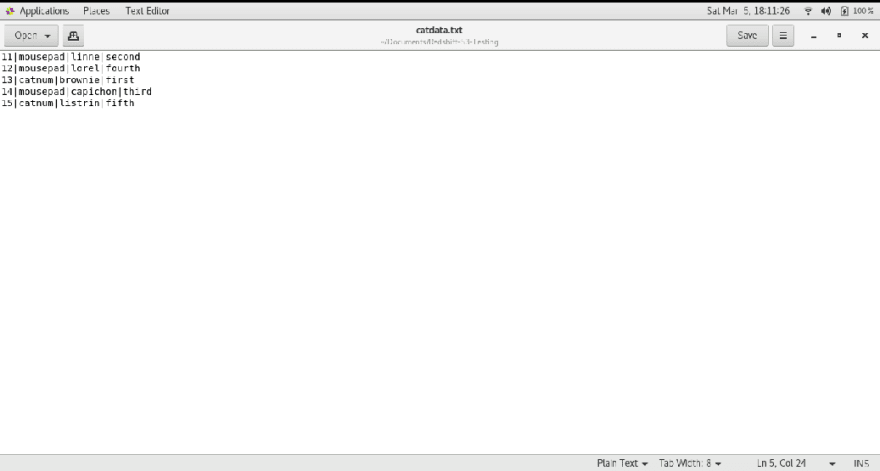

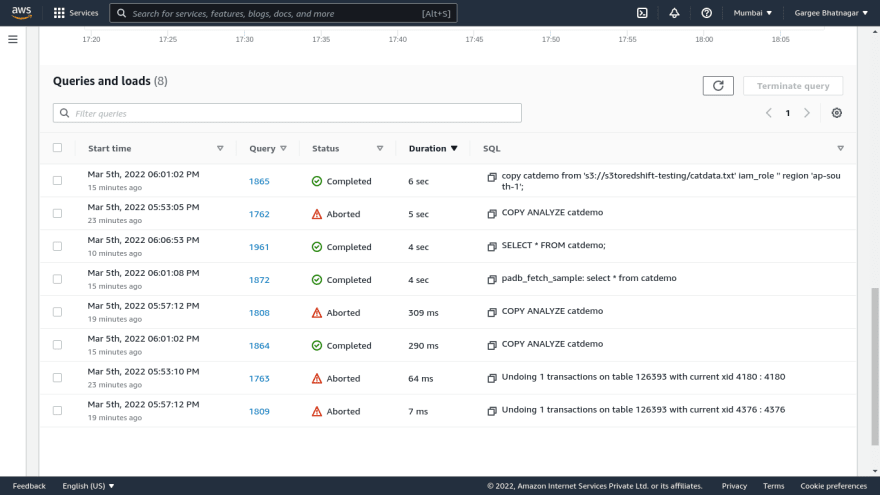

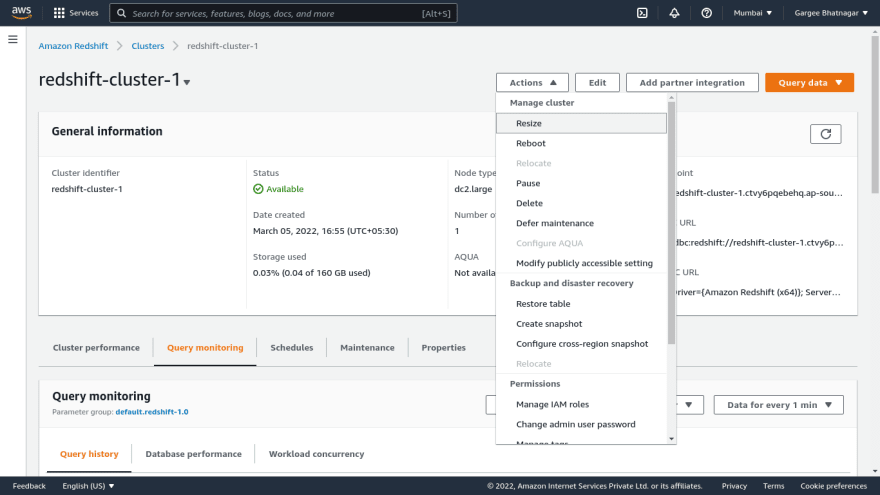
Phase 4: Resize of Redshift Cluster using Resize option
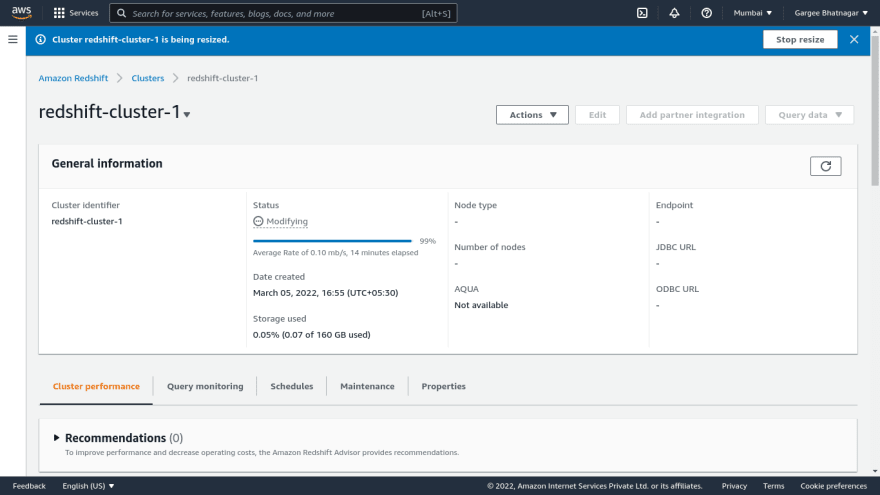
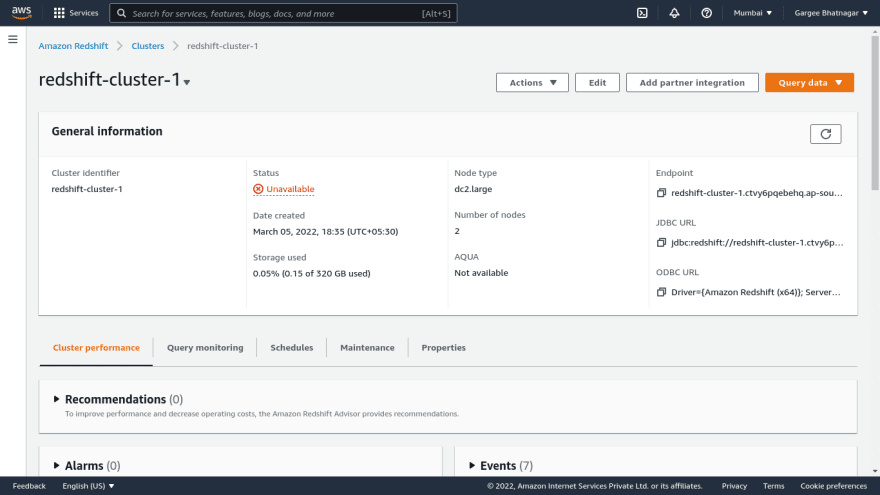
- Open the redshift cluster console and goto actions drop down. Select the resize option and add the number of nodes as required. Click on resize cluster option and then cluster goes to modifying state then unavailable and then available.



Clean-up
Delete EC2 server, IAM, S3 bucket, Redshift cluster.
Pricing
I review the pricing and estimated cost of this example.
Cost of EC2 = $0.0124 per On Demand Linux t2.micro Instance Hour = 2.013 Hrs = $0.02
Cost of Key Management Service = $0.0
Cost of Redshift = $0.000 per Redshift Dense Compute Large (DC2.L) Compute Node = 1.957 Hrs = $0.0
Cost of Simple Storage Service = $1.0
Total Cost = $(0.02+0.0+0.0+1.0) = $1.02
Summary
In this post, I showed “how to create a redshift cluster, copy s3 data to redshift and query on the redshift console using a query editor”.
For more details on Amazon Redshift, Checkout Get started Amazon Redshift, open the Amazon Redshift console. To learn more, read the Amazon Redshift documentation.
Thanks for reading!
Connect with me: Linkedin

This content originally appeared on DEV Community and was authored by DEV Community
DEV Community | Sciencx (2022-03-12T18:55:55+00:00) Amazon Redshift : How to Create Redshift Cluster, Copy S3 Data to Redshift and Query on the Redshift Console Using Query Editor. Retrieved from https://www.scien.cx/2022/03/12/amazon-redshift-how-to-create-redshift-cluster-copy-s3-data-to-redshift-and-query-on-the-redshift-console-using-query-editor/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.