
This content originally appeared on Level Up Coding - Medium and was authored by Erdem Emekligil
Learn to utilize Tensorflow Serving to create a web service to serve your Tensorflow model
This is the second part of a blog series that will cover Tensorflow model training, Tensorflow Serving, and its performance. In the previous post, we took an object oriented approach to train an image classifier model and exported it as SavedModel. I recommend going over it before this post since we are going to use the same model. You can find the complete application codes for the blog series here:
What is Tensorflow Serving?
There are many alternative ways to use Tensorflow models in applications. One of the simplest is using Tensorflow along with Flask, Django, Fastapi, etc. frameworks to create a python based web application. Frameworks like ML.NET or deeplearning4j can be used if it needed to develop in other languages. Tensorflow Lite, Pytorch Live, and CoreML are the frameworks to use for mobile applications. However, in layered architectures and microservices, it is a good practice to make the machine learning models standalone applications. This concept is called model serving and serving a model as a service has many advantages. For example, models can be updated in production without downtime or can be used by many different client applications. To achieve model serving, applications like Tensorflow Serving, TorchServe, Triton, KFServing can be used.
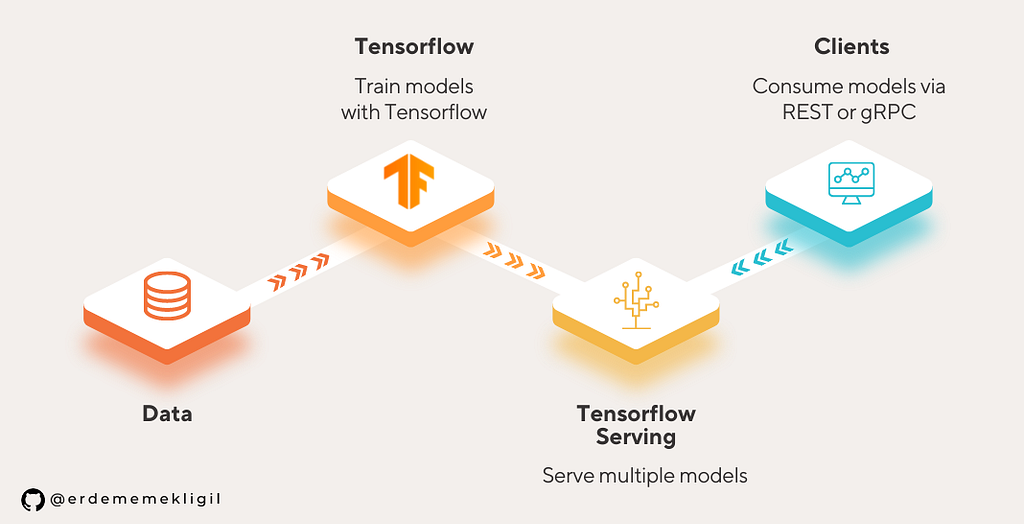
Tensorflow Serving allows us to serve Tensorflow models as web services without the need for an additional application. It supports serving multiple versions of multiple models via gRPC and REST protocols. However, it requires the models to be in Tensorflow’s SavedModel format. SavedModels are open to finetuning and some modifications after the training especially if they are built using Keras. Extra functions and signatures can be added to SavedModels, then served using TFServing.
Examine the SavedModel
We had trained a ResNet50 model in the previous medium post and saved it in SaveModel format. We can use this command to show the model signatures that will be served by Tensorflow Serving: saved_model_cli show --all --dir model_path
signature_def['serving_bytes']:
The given SavedModel SignatureDef contains the following input(s):
inputs['image_bytes_string'] tensor_info:
dtype: DT_STRING
shape: unknown_rank
name: serving_bytes_image_bytes_string:0
The given SavedModel SignatureDef contains the following output(s):
outputs['output_0'] tensor_info:
dtype: DT_FLOAT
shape: (1, 10)
name: StatefulPartitionedCall:0
Method name is: tensorflow/serving/predict
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['input_tensor'] tensor_info:
dtype: DT_FLOAT
shape: (-1, -1, -1, 3)
name: serving_default_input_tensor:0
The given SavedModel SignatureDef contains the following output(s):
outputs['output_0'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 10)
name: StatefulPartitionedCall_1:0
Method name is: tensorflow/serving/predict
We can see from the output that the signatureserving_defaulttakes 4d array input whereas serving_bytes takes base64 encoded array (as string) input. Both signatures output an array with 10 numbers (probabilities) since the model is trained on MNIST and has 10 classes.
Running the Tensorflow Serving
Tensorflow recommends using Docker image for Tensorflow Serving since it is the easiest way to use Tensorflow Serving with GPU support. Follow the instructions in this link if you don’t have docker and want to install Tensorflow Serving manually.
The below script creates and runs a Tensorflow Serving container with the given model. Port 8500 is used for the gRPC API and 8501 is used for the REST API. This script binds the model directory in the host to the container and reads the model from there. However, it is a better practice to put the models in Docker images instead of using binds when using Tensorflow Serving in production environments.
docker run -p 8500:8500 -p 8501:8501 -d --name resnet_serving \
-v /directory/on/host/models:/models \
-e MODEL_NAME=ResnetModel tensorflow/serving:2.8.0-gpu
To check if it’s up and running correctly go to this address in a web browser: http://hostname:8501/v1/models/ResnetModel. It returns a json like below if it is working correctly:
{
"model_version_status": [
{
"version": "1",
"state": "AVAILABLE",
"status": {
"error_code": "OK",
"error_message": ""
}
}
]
}Consuming the REST service
Both REST and gRPC protocols have their advantages and disadvantages. Probably the most important one is that the REST protocol is more common.
To call the model using the REST API send a POST request to http://hostname:8501/v1/models/ResnetModel:predict with a request body like this:
{
"signature_name": "serving_bytes",
"instances": [{"b64": "fill_with_base64_encoded_image_bytes"}]
}Since the model is trained on the MNIST dataset containing handwritten digits from 0 to 9, the service returns activations with no softmax applied for 10 classes. In the example below, the model’s prediction will be the class with the highest activation value, the 3rd index (belonging to number 2):
{"predictions": [[-14.9772987, -6.99252939, 13.5781298, -8.89471, -6.88773823, -4.63609457, 0.168618962, -9.86182785, -2.09211802, -1.32305372]]}The same result can be obtained by calling the serving_defaultsignature with the RGB pixel values. This signature supports multiple images to be processed at once since it has 4d input (batch, height, width, channel):
{
"signature_name": "serving_default",
"instances": [[[[0, 0, 0], [0, 0, 0], [255, 255, 255], ...]
}For the REST API, this signature is slower than the serving_bytes when sending images with high resolutions since integer arrays consume much more memory when converted to strings.
Consuming the gRPC service
Consuming a gRPC Tensorflow Serving API is only officially supported for Python. There are some open source clients for other languages, but they may not be available for recent versions of Tensorflow Serving. For python, tensorflow-serving-api must be installed: pip install tensorflow-serving-api. A service stub with an insecure connection (check here for secure connection) is created below:
Predictions to the serving_defaultsignature can be made using the stub defined above:
The tf.make_tensor_proto and tf.make_ndarray methods are used for numpy array to/from tensor conversions. Multiple images can be sent in the same serving_default request to achieve faster results. For relatively larger images (e.g. 600x600px) the serving_bytessignature can be used to have faster results:
Conclusion
We used Tensorflow Serving to create REST and gRPC APIs for the two signatures of our image classification model. The REST API is easy to use and is faster when used with base64 byte arrays instead of integer arrays. External frameworks must be used to consume gRPC API. However, it is faster when sending multiple images as numpy arrays.
Please check the GitHub repository for the complete code. Feel free to ask any questions in the comments. In the next post, we will measure the performance of Tensorflow Serving and discuss how to increase its performance.
Serving an Image Classification Model with Tensorflow Serving was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Erdem Emekligil
Erdem Emekligil | Sciencx (2022-03-18T12:03:31+00:00) Serving an Image Classification Model with Tensorflow Serving. Retrieved from https://www.scien.cx/2022/03/18/serving-an-image-classification-model-with-tensorflow-serving/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.