
This content originally appeared on Level Up Coding - Medium and was authored by Kyle Ziegler

Introduction to Hyperparameter Tuning & Bayesian Methods
If we break out machine learning into three components: representation, evaluation, and optimization, hyperparameter tuning would adjust the parameters on the model representation to better fit the data on the test set according to your evaluation criteria. As we create and evaluate new models, we’ll also want to make sure that we are not overfitting or underfitting the model to the data. Automated methods range from brute force, to using another model that observes the behavior of y = f(x) and decides which path to go in with unexplored parameters, only choosing the set that are likely to reduce loss.
When you get to the training stage of model development, you may know a range of parameters that you want to try — various C, alpha, learning rates, tree depths — but you most likely do not know which combination of these values yields the best results on your evaluation criteria. In this tutorial, I’ll be speaking to traditional supervised machine learning model representations such as OLS linear and logistic regression, decision trees, SVMs, K-nearest-neighbors, tree ensembles, and Naive Bayes.
Prerequisites and General Best Practices
- Have a clear idea of your evaluation criteria. Examples of this include precision and recall, squared error, information gain, posterior probability, and likelihood. What are your goals for this model?
- Know your algorithm and parameters well, what each one controls and how that changes its ability to generalize in production. You’ll notice that some parameters have a very large impact whereas others do not make as large of an impact.
- Remember to double check for data leakage — are your test set results too good to be true? Are you using data that you will not have at inference time?
Before we get into the methods to hyperparameter tuning, I’ll touch on a few objectives for this process. Tuning parameters on models, retraining, and scoring, is a very compute intensive process. With basic methods of parameter tuning, we have an exponential function; k lists of n length O(n^k ), where k is a constant. Our goal is to spend the least amount of human labor (data scientists time) and compute power while achieving optimal results according to our evaluation criteria. Iterating quickly can be beneficial, as you’ll notice different types of behaviors with parameters for different algorithms, and specifically with respect to the data you are fitting on. For example, we may be working with a gradient boosted decision tree ensemble and a random forest, but we’d like to quickly decide between the two and make a decision on whether we need to go back to feature engineering or move forward to evaluating the model on new data, and rolling out to production. We should not settle on exhaustive approaches, as for the reasons mentioned before, so I would encourage you to push for more efficient options available today.
Automated Hyperparameter Tuning Options
- Grid search and random search
- Bayesian
- Hyperband
- Black box methods including Google Cloud’s Vizier and SigOpt
Testing Methodologies
My setup includes a 64 core, 240GB of RAM, 100GB SSD, Python 3 N1 notebook in Google Cloud Vertex AI. I used the the same parameters on all methods where possible, and locked in the random state, including on the train/test split. You have access to the same data, and can replicate the results yourself on your local machine or in the cloud. I used the python magic %timeit to record the runtime for each of my functions. I included a simple pyplot function where I plot the mean score over each iteration.
Grid Search & Random Search
This is an exhaustive approach where we essentially try every possible combination of values and return the set of parameters and trained model with the highest evaluation results on your test set. We know that we will find the optimal set of parameters, at a high compute cost. I would recommend this option when you do not have many parameters to test, and training your model is only taking a few seconds for a given set of parameters; ie your dataset is not large you are fitting the model to. Check out the documentation for SKLearn’s GridSearchCV if you are interested in using this method. In addition, take a look at the scoring methods you can pass to GridSearch. This will allow you to set an objective such as F1, ROC AUC, R2, and explained variance. I’ve included an example below where I used GridSearchCV to optimize a classification model.
Dataprep & plotting function ~
Grid search example
Here we are training a gradient boosting classifier, and I have specified a parameter grid with the range that the model will test and score. A new model is fit on each iteration of a new hyperparameter combination, on the entire training set- which as defined above is an 80/20 split. We have 5 cross validation folds set, and are using R2 to calculate loss.
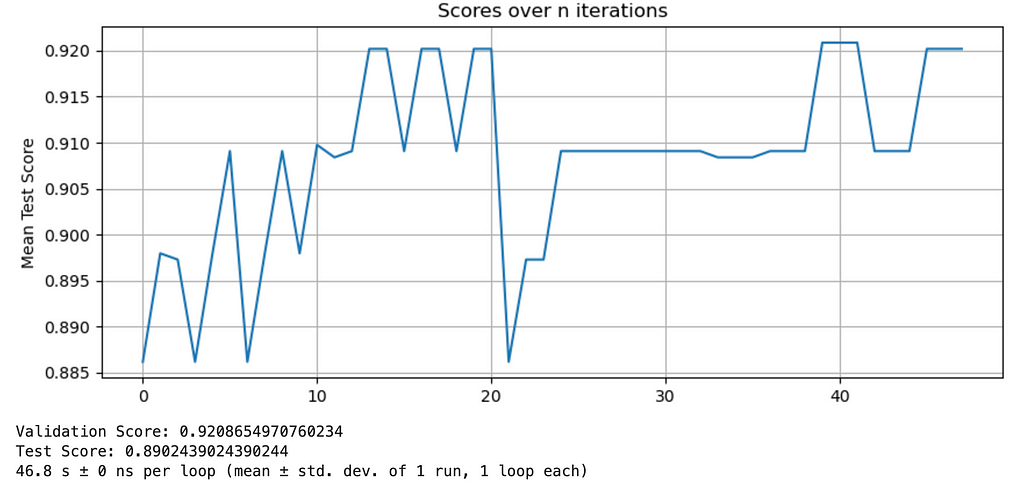
Bayesian Optimization
Bayesian approaches offer a significant speedup in finding the optimal parameters over a given domain. We are interested in minimizing this function:
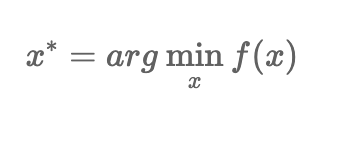
Given these constraints:
- F is a black box and there is no closed form solution [4]
- F is expensive to evaluate
- Evaluations of y = f(x) are expensive
Now that we’ve reviewed what we are trying to solve, what is the process for choosing parameters and iterating? There are a number of acquisition functions for this, including expected improvement, lower confidence bound, and probability of improvement. These functions have a number of parameters that you can adjust to make tradeoffs between exploitation and exploration .
I’ll demonstrate two Bayesian examples, the first using BayesSearchCV and another using a custom loop. With BayesSearchCV, you can fine tune the search process through the number of parameters that are sampled which trades off runtime and model quality. Getting started with the sk-optimize api is simple — you’ll need a model and an evaluation objective (recall, precision, MSE, R2, etc ) at minimum. Note that you can also take advantage of the n_jobs parameter to accelerate your computation, leveraging multithreading on your CPU, here I leverage all the cores available with -1.
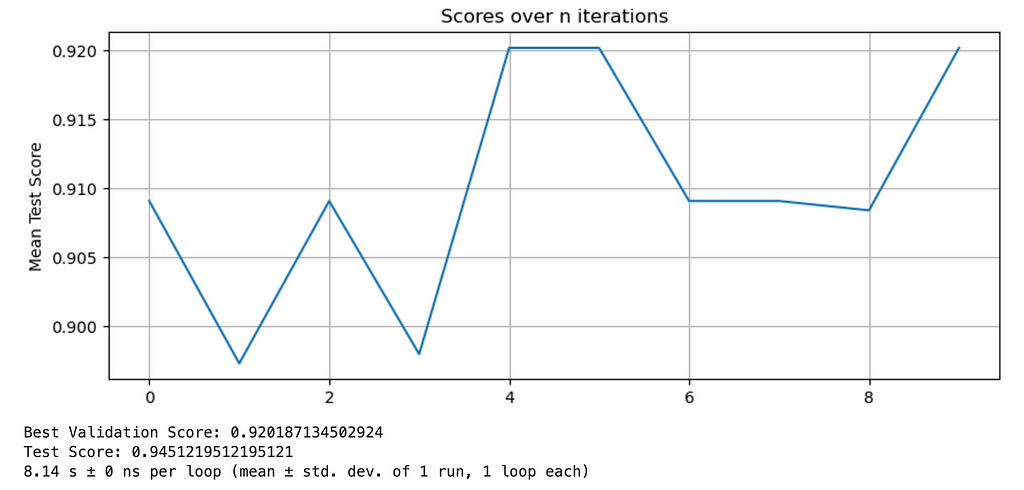
Here is my last example, using a custom loop to calculate and minimize loss at each iteration:
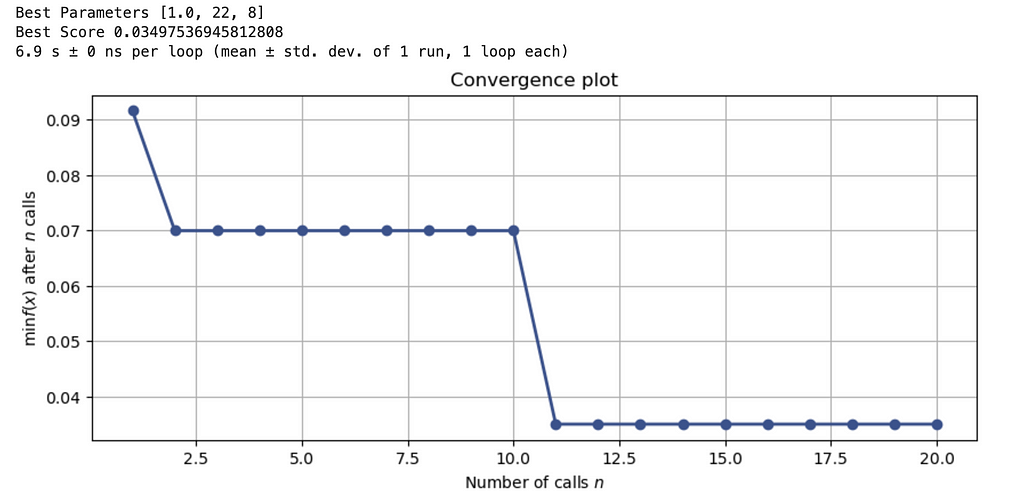
Conclusion
There was more than a 500% increase in runtime performance by using the bayesian techniques, and this can grow as you scale the number of parameters you are testing out as we noted earlier with the grid search runtime of O(n^k). Bayesian methods prove to be an effective method of optimizing black box functions, and managed services such as Google’s Vizier further increase the performance. At the hyperparameter tuning stage in larger models, creating a search space and using the optimal methods is a way to save time and compute power, and can allow the data scientist to focus on the model code and business objective.
References & Notes
- A Few Useful Things to Know About Machine Learning, Domingos 2012
- Practical Bayesian Optimization of Machine Learning Algorithms,
- Bayesian optimization with skopt
- Closed form solutions are ones that can be expressed with a finite number of well-known expressions. Linear regression through partial least squares does have a closed form expression, but in gradient boosting where we have an ensemble of weak learners, often do not have a closed form solution since they fundamentally rely on iterative optimization methods.
Introduction to Hyperparameter Tuning & Automated Methods was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Kyle Ziegler
Kyle Ziegler | Sciencx (2022-03-20T23:34:57+00:00) Introduction to Hyperparameter Tuning & Automated Methods. Retrieved from https://www.scien.cx/2022/03/20/introduction-to-hyperparameter-tuning-automated-methods/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.