
This content originally appeared on DEV Community and was authored by Arkadeep Nag
Creating a search engine from scratch
The basic function of a search engine is to search . But that basic function includes a lot of work in the background .
That include :
- Crawling websites / Creating a software that goes through websites and get their data
- More importantly get the legal permission of the website owner to allow us crawl their website
- Creating a database
- Creating ranking algorithms
- Creating ML models for various purposes which includes understanding speech , understanding images , language and many more
Now no useful search engines in the world is open source so we cannot just use any code from someone else .
We had to begin from strach
Creating a Search engine from my experience
Steps for beginning the creation
- Identify which form of database you want to use Either you can use a graph database , SQL database , NO SQL databas or just create a database with customisations yourself
Since no database system was totally free to use I created my own Database system which is partially based of Graph SQL and NoSQL .
-
Identify the programming language you will use for the crawling process
You have Python as one of the best option byut C or C++ is required for MapReduce algorithms in some cases
You can use simple modules already existing in python family or go around with Cython which I for myself used -
Identify which language you are going to use for your frontend development
you can use C , C++ or Python as they would be compatible with all your frameworks and then use SWIG or Webassembly to convert it to JavaScript or
use JavaScript frameworks in which you may get problems to include your ML and AI models.I personally used the first option to include my ML models with ease -
Defy algorithms and their respective flowcharts that you need to generate better search results. You may require atleast ten of them
1st for crawling the webpages
2nd for crawling the webpages through backlinks
3rd update the webpages frequently
4th Continuously run the crawlers
5th Identify elements from websites and classify them
6th How will your DB work
7th Connecting DB from many servers together
8th Responding to queries
Then your ML models
Your AI Models
How will you rank your search results
Query management
And many more
I personally wrote many . This part gives a bit of an headache
Begin with Frontend
The frontend will attract your users and force them to invite many . But your website is going to pull a lot of information and can slow down if it is made with high graphics . So make it minimalistic but beautiful
Creating the frontend first would also give you some relief from the headache of creating long algorithms
Create the crawler
Though I have used Cython ( C and Python )I would rather prefer others using python with third party frameworks - > Selenium and Beautiful Soup or Scrapy
Choose a Database
I created my own Database with some help of opensource GraphQl and NoSQl database .
I made it scalable so that it can handle many data and queries . It is also scalable . I used Ruby , Python and C for creating it . I am using 7 Server computers to host the db
It would be easy to query from NOSQl DB and Graph db ( from my experience )
But you can choose other DB . For free option you can use Firestore from Firebase it's simple and easy .
Building your server
If you are not using any cloud database and want to have your own server and DB use a Linux device and old PCs or if you have money buy some low end servers
Handling Pentabytes of data
My crawler uptill now has crawled 3M+ webpages and it has cached more than 156GB data . Every second 30+ webpages are added to the index . Google has stored 136Trillion + webpages and so you got the idea in no time you will have billions and billions of data to handle . So our database needs to be scalable . I have AI models to manage them and it has been made scalable so you have to make an idea to handle them
Algorithms for ranking your search results
The data you will get perquery will be huge if you have many pages indexed . So ranking them would be a factor . I didn't use the "PageRank" algorithm but devised my own . I have made the algorithm not to look after how many backlinks point to the page but I have used 8 parameters
You can break down a query for e.g.
This is a search results
In this search query which words have more emphasis it's the fourth and the last because the first three don't really matter much in a sentence while searching.
If any page has this two word they would be ranked based on how many times they are repeated .
For example we have 5 pages having search and results
1.A 2.B 3.C 4.D 5.C
And we have 2 pages each with only one of them so they will be ranked down
- E 7. F
The first check will end here
The second parameter is in which pages the words are given more emphasis
For example if a word is in title of a webpage it will be given more emphasis than the webpage having it in its body
Suppose "A" has the words in body and "B" has the word in title
So now the ranking will change to
- B 2. A
The third parameter will now intervene it will check how does the whole webpage relates to the user's query . Like location , mood ( mood detection algorithm ) , tone ( tone of the words ) and many other things
. Suppose the query is more related to the webpage on "C " more than "A" and "B"
New rankings ->
- C 2. B 3. A
Fourth parameter will check the clicking ratio of that website on similar queries. For example if someone clicks "B" more than "C" when searching for related queries then the ranking of "B" will automatically increased
Being personal
The rest four and other topics are not possible to cover in single blog .
I have worked ver hard for the last 3 years for creating the search engine I hope you will like it when it launches this year. Now it's on the verge of being completed.
If you wanna see or experience an old build of the similar search engine with no algorithms and firebase database then go to https://dravel.herokuapp.com
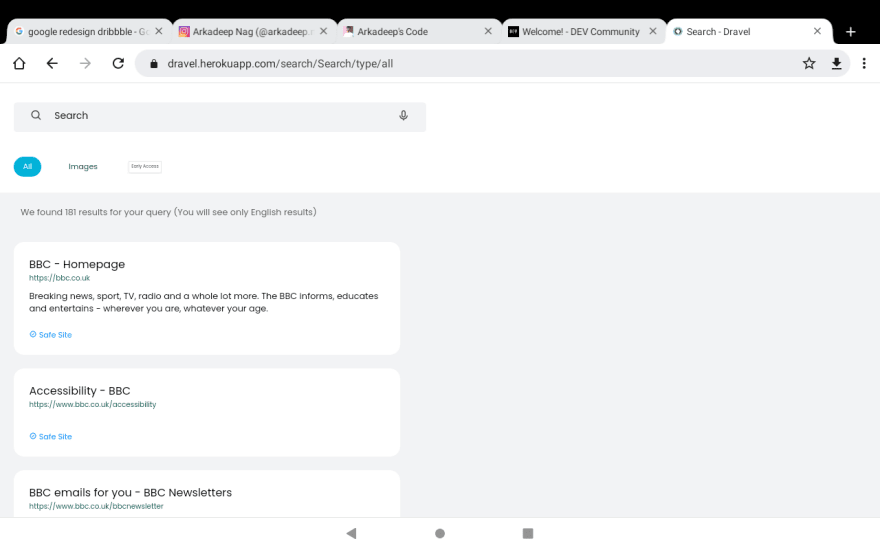
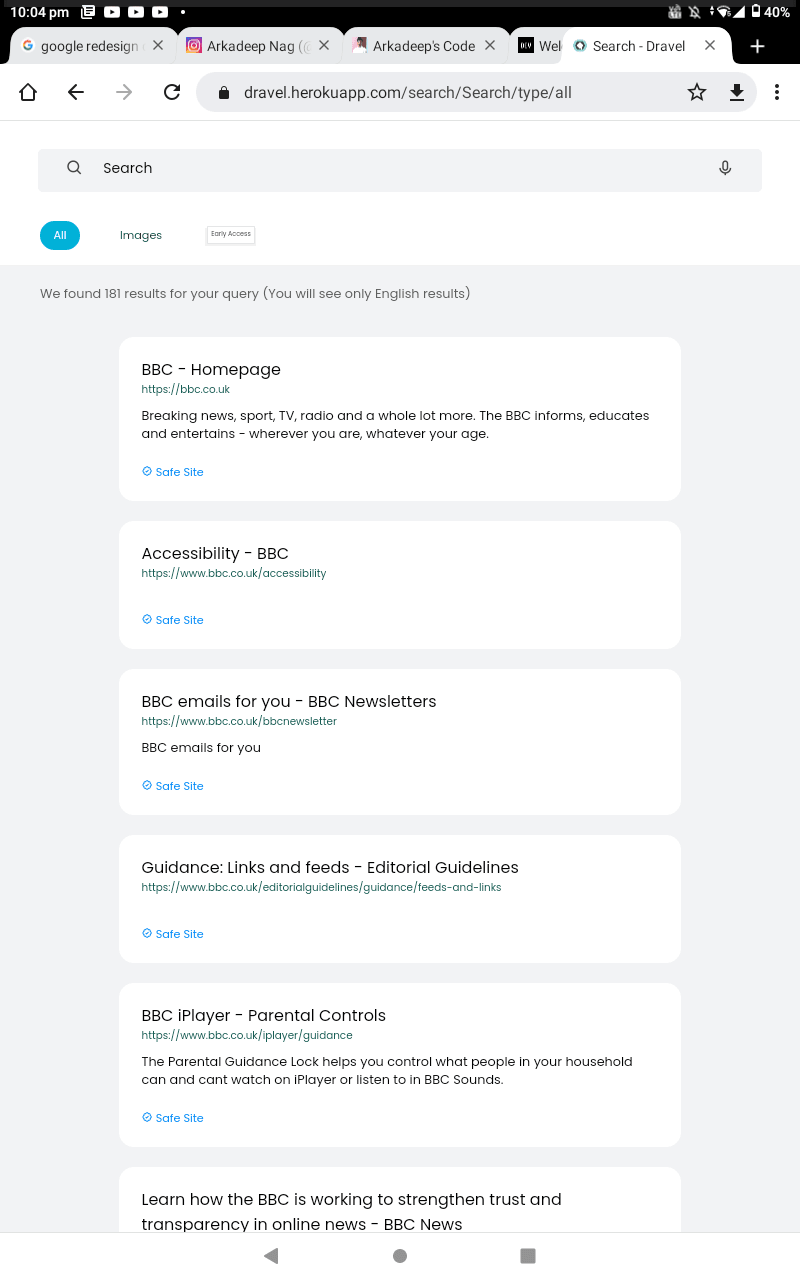
Thank you very much for reading till last
This content originally appeared on DEV Community and was authored by Arkadeep Nag
Arkadeep Nag | Sciencx (2022-03-25T17:45:19+00:00) How I am creating my own search engine. Retrieved from https://www.scien.cx/2022/03/25/how-i-am-creating-my-own-search-engine/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.