
This content originally appeared on Level Up Coding - Medium and was authored by Siddharth Kshirsagar
I will be demonstrating an end to end machine learning project which starts from the extraction of data from a SQL database and ends with deployment as a Web App or a web Dashboard

How the app will look finally
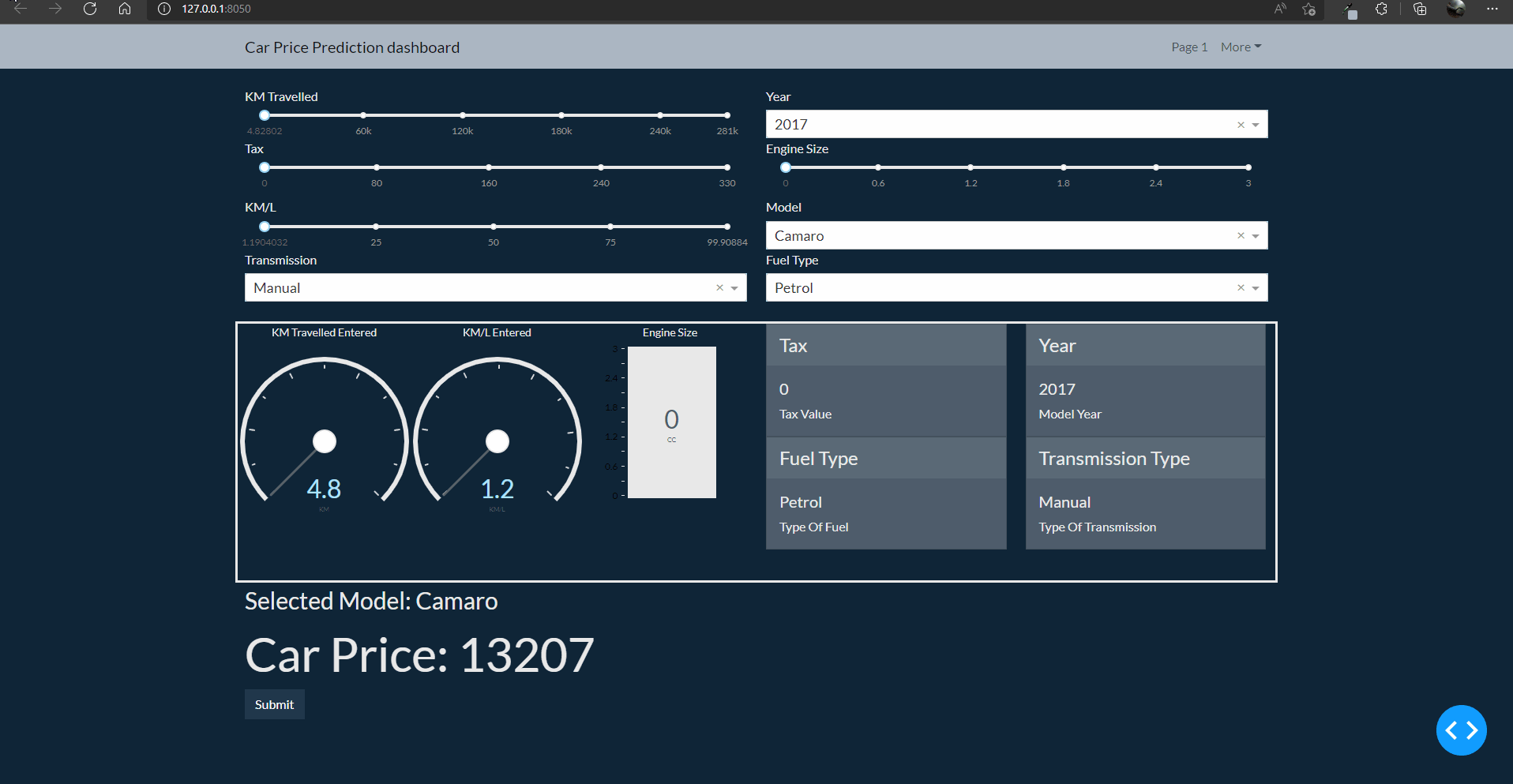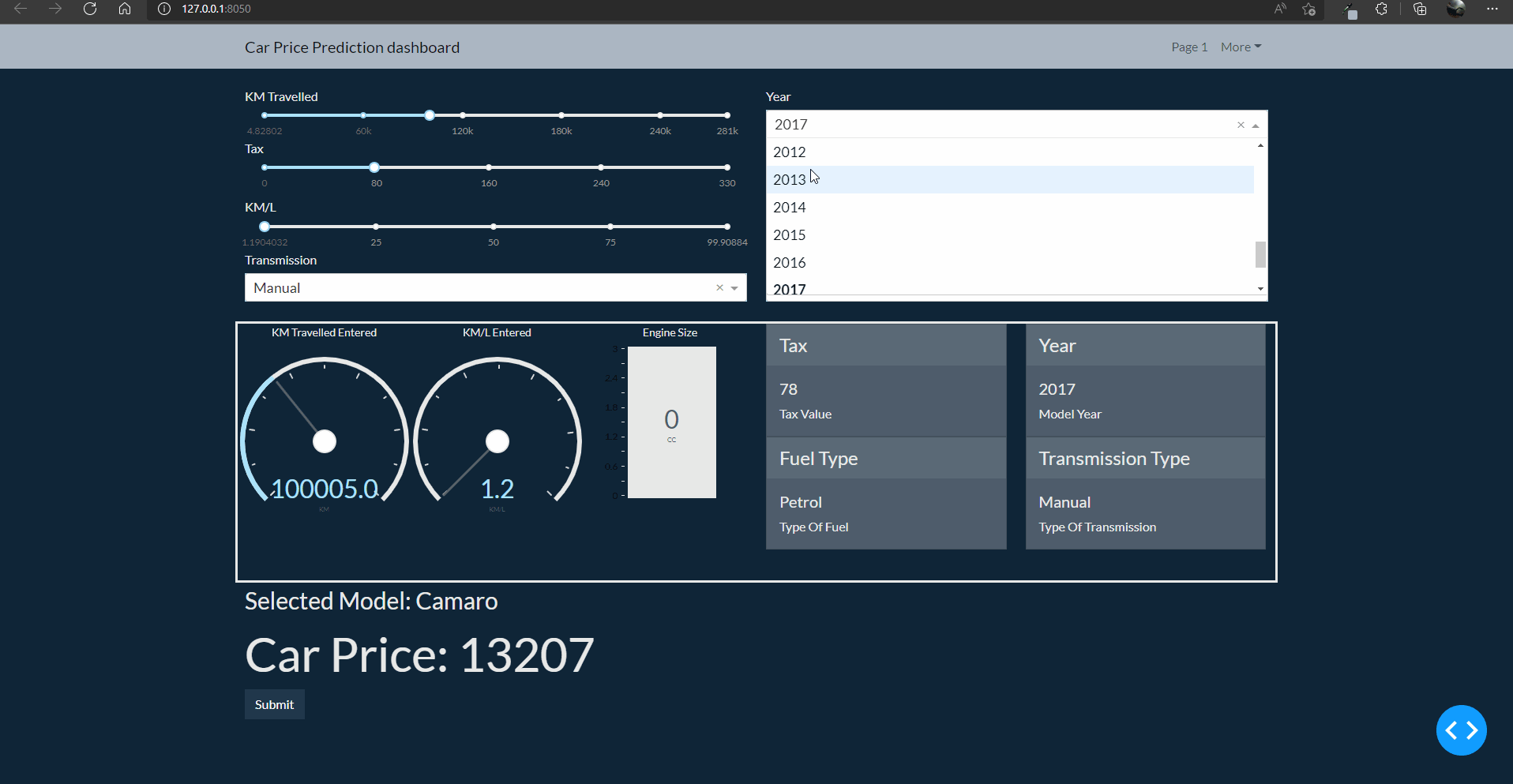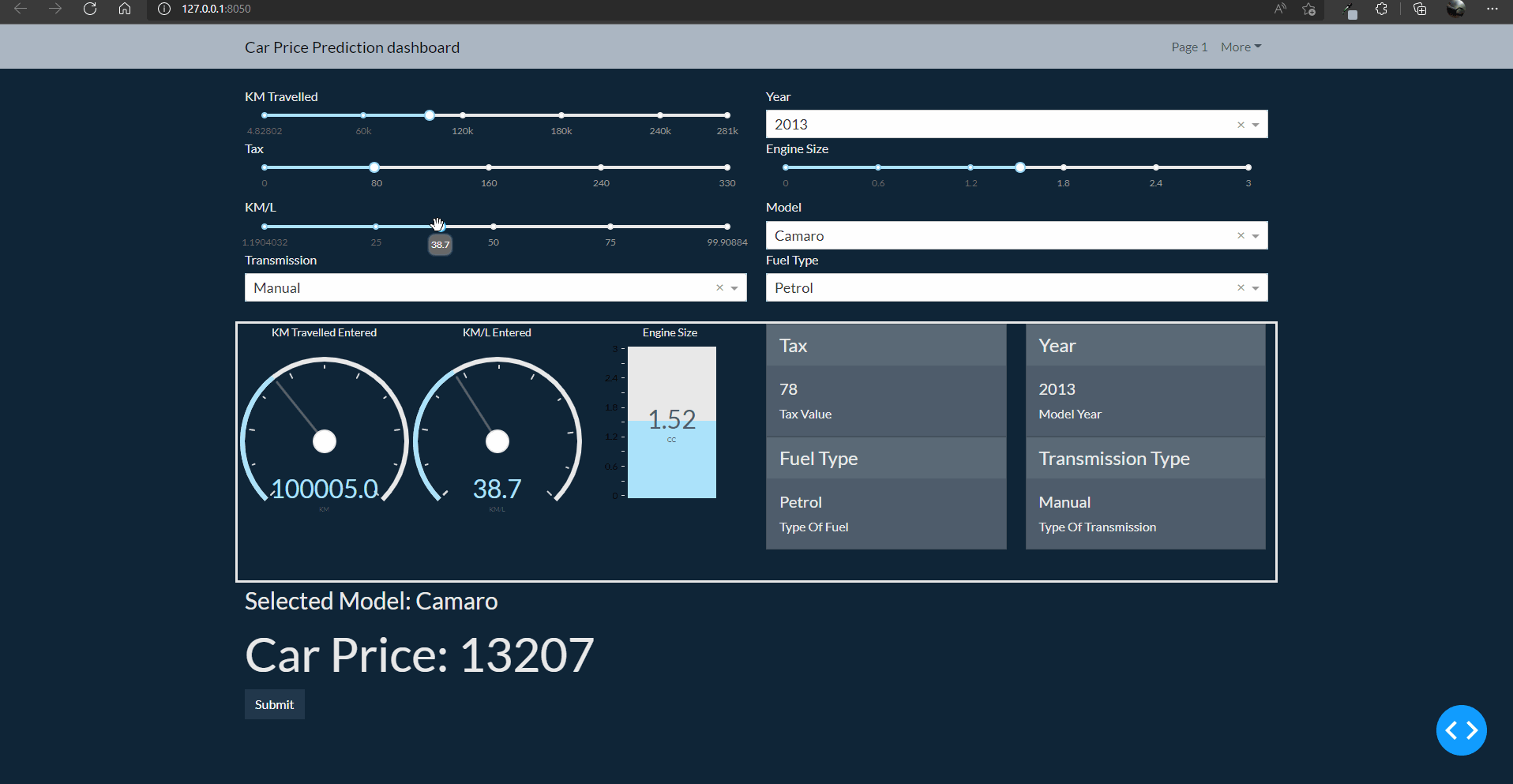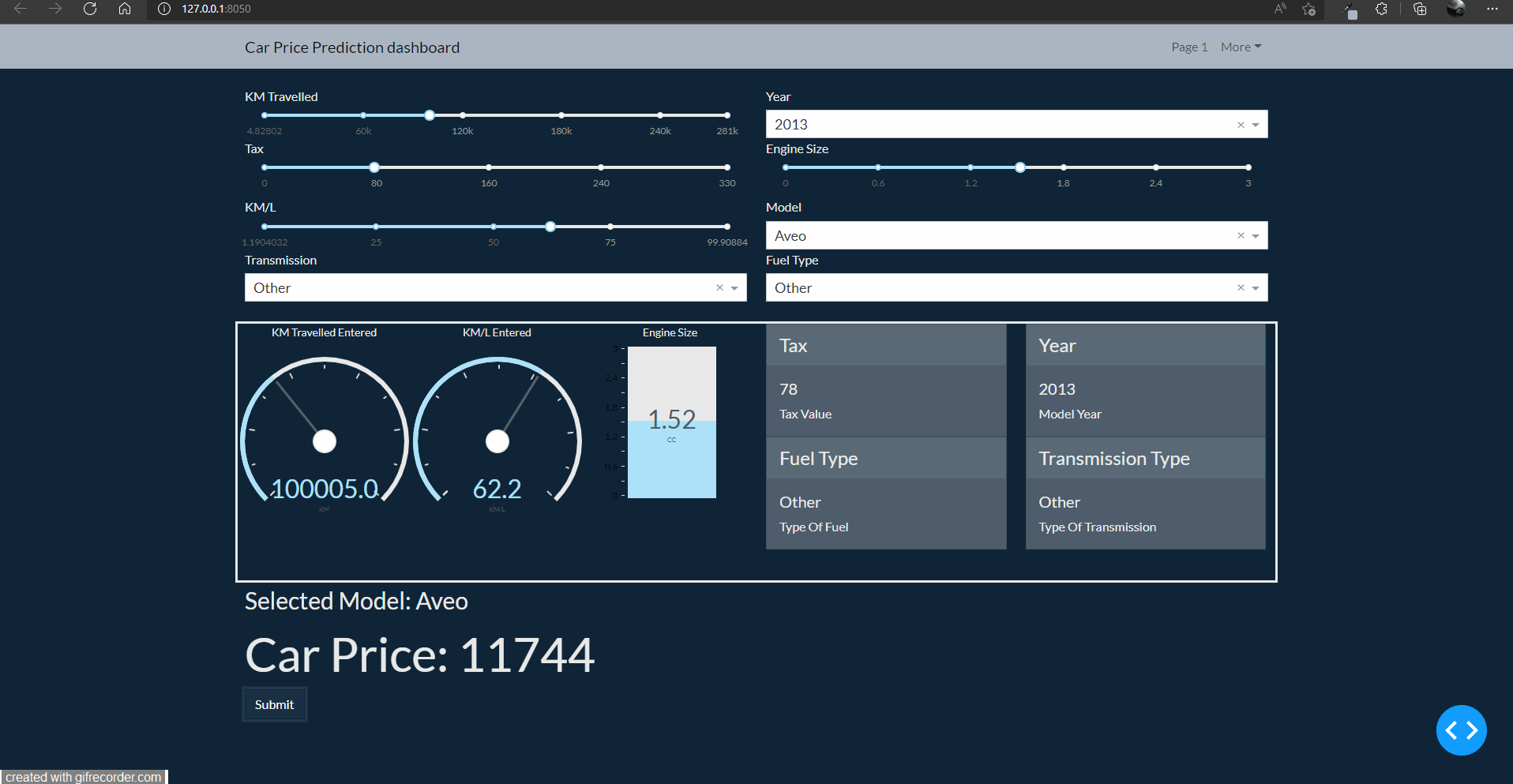
Code for this article is at:
kshirsagarsiddharth/machine_learning_model_for_car_prediction (github.com)
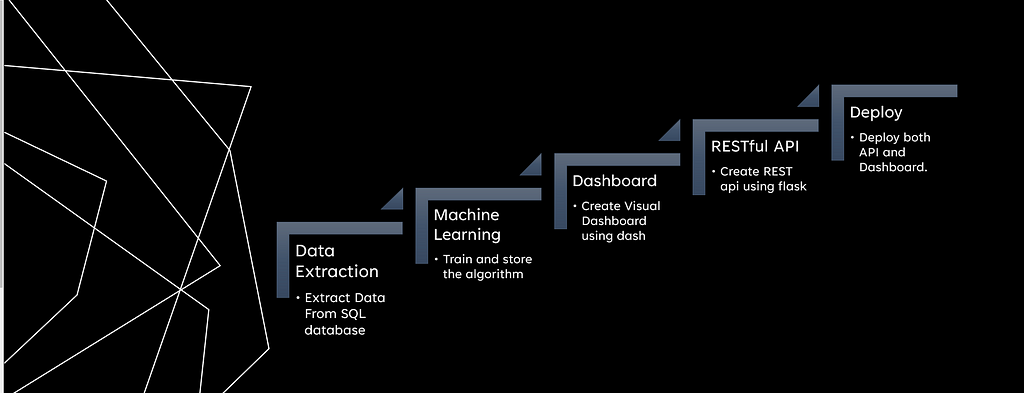
PROBLEM STATEMENT
- We are part of a company called SECOND CARS and we sell used cards.
- During a recent company survey it was observed that cars belonging to ‘Chevrolet’ are not priced correctly by the sellers. Some of the cars are way overpriced and some of the cars are way under priced which has caused substantial loss in the previous quarter.
- To remedy this the senior management has tasked us to create a model which will efficiently predict the price of cars with minimum error. So that it will be helpful to the sales people to correctly price the car.
- They have also asked us to prepare a decision tree for the sellers who want to also use their own intuition combined with the model.
- They have asked us to create interactive dashboards for our sellers with non technical background.
- They have also asked us to create a RESTful API which will be used by IT departments of our other clients programmatically to get the pricing.
Objectives
- Company Data is in a SQLite database. So We need to extract rows only belonging to ‘Chevrolet’.
- Convert Data into a pandas DataFrame.
- Train the machine learning model And Save The Machine Learning Model.
- Create a RESTful API and deploy in heroku.
- Create a Plotly Dash Dashboard as a front end for sellers to find the price also deploy on heroku.
Part 1 : Loading Data from SQL database into pandas
1.1: Method 1 to load data from database into a dataframe: Install ipython-sql to run queries directly in jupyter cell
pip install ipython-sql
1.1.1 Connecting to the database
# in my case the data is at the same location where my notebook is located hence I have given that location
%load_ext sql
%sql sqlite:///car_prediction_dataset.sqlite3
Understanding the database structure

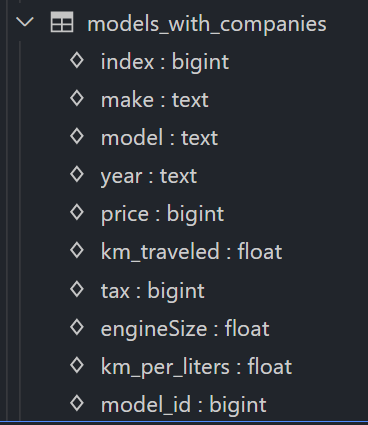
- There are two tables which contains data which we need.
- index column in model_info is actually model_id from model_with_companies.
- In other words model_id in model_with_companies is foreign key of model_info.
- We will perform inner join on index in model_info and model_id in model_with_companies and select only rows required for our modelling.
According to the problem statement I am only selecting companies belonging to “Cheverolet”
Note: ON mc.model_id = mi.”index” in this case “index” is in double quotes because index is a standard function or something in SQLite hence it is in double quotes.
1.1.2 Method 2 to load data into pandas DataFrame using read_sql_query method of pandas
Install required module: pip install SQLAlchemy
2.1 Training Machine Learning Model
Import necessary libs
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import OrdinalEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
2.2 Check for null values
df.isnull().sum()
year 0
price 0
km_traveled 0
tax 0
engineSize 0
km_per_liters 0
model 0
transmission 0
fuel_type 0
dtype: int64
2.3 Seperate the Dataset into dependent and independent
y = df['price']
X = df.drop('price', axis = 1)
df['model']
0 Camaro
1 TrailBlazer
2 Silverado 2500 Extended Cab
3 Astro Cargo
4 S10 Extended Cab
...
5096 Express 1500 Cargo
5097 Silverado 2500 HD Regular Cab
5098 Cavalier
5099 Monte Carlo
5100 Silverado 2500 HD Extended Cab
Name: model, Length: 5101, dtype: object
2.4 Divide Dataset into 3 parts Train, Test and Valid
Note: we could simply take the whole dataset apply pd.dummies on unordered columns and convert ordered categorical columns into integers but I am not doing this because this is very bad practice reason being.
- We want to keep training, testing and validation datasets seperate
- What if new data comes, we cannot use pd.dummies method to transform the new dataset.
- using pd.dummies method is not scalable and probhits us from rapid developement of new models and testing
2.5 Extracting names of numerical and categorical columns
Note: columns year, model are label encoded, columns transmission,fuel_type are one hot encoded.
numeric_columns = X.select_dtypes(exclude='object').columns
unordered_columns =['transmission', 'fuel_type']
# I am not one hot encoding year and model because there are too many values
ordered_columns = ['year', 'model']
print(numeric_columns)
print(unordered_columns)
print(ordered_columns)
Index(['km_traveled', 'tax', 'engineSize', 'km_per_liters'], dtype='object')
['transmission', 'fuel_type']
['year', 'model']
2.6 One Hot Encoding categorical columns
2.7 Lable Encoding ordered categorical columns
2.8 Scaling Numerical Column
2.9 Combining Numerical and Categorical Columns
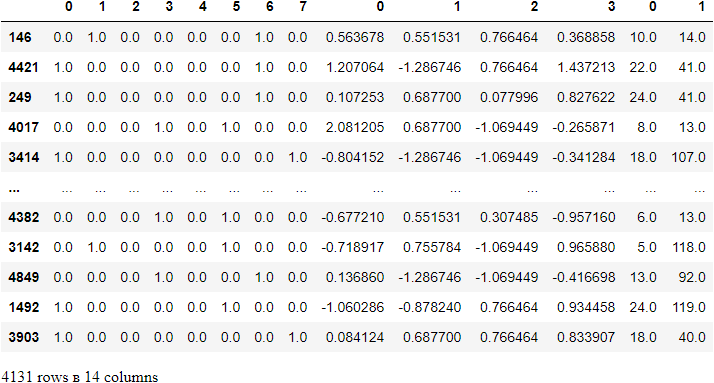
2.10 Converting above task into a function instead separately encoding the columns respective columns. In other words automating the above process of encoding.
2.11 Using different models to check which model gives best result.
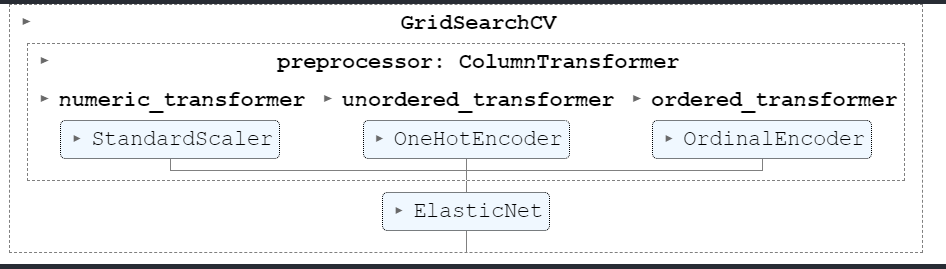
2.12 So the model performing best is ElasticNet and RandomForest so lets do grid search on ElasticNet algorithm
GridSearch on ElasticNet
2.13 So we kind of simplified the preprocessing but still there is too much code so, there is another method through which the whole process can be automated, We will be using Column transformer
- There is also another disadvantage of above method first being we need to persist all 3 transformers and the model to load later. In other words we need to pickle the three transformers and model and load the 4 files later in deployment code to predict.
- The approach is not streamlined for rapid training.
Column Transformer with Mixed Types
2.14 Using Column Transformer
Applies transformers to columns of an array or pandas DataFrame.
This estimator allows different columns or column subsets of the input to be transformed separately and the features generated by each transformer will be concatenated to form a single feature space. This is useful for heterogeneous or columnar data, to combine several feature extraction mechanisms or transformations into a single transformer.
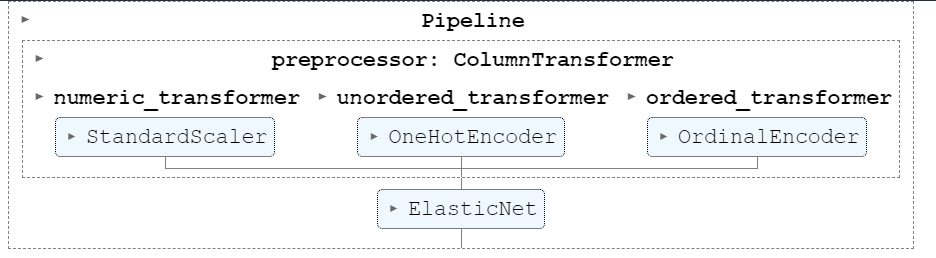
So this pipeline did OK, To improve results we can also perform grid search on this pipeline. Please refer ColumnTransformer guideline for more info.
Saving the model
import joblib
# saving the model
joblib.dump(grid_search.best_estimator_,'final_car_prediction_model.pkl')
# saving the column names
joblib.dump(list(X.columns),'column_names.pkl')
['column_names.pkl']
Loading the saved model
loaded_model = joblib.load('final_car_prediction_model.pkl')Making prediction on loaded model
joblib.load('column_names.pkl')))loaded_model.predict(pd.DataFrame(data = [['2018', 39842.43038, 0, 1.5, 20.3643976, 'Camaro', 'Manual','Petrol']],
columns =
array([12693.99485813])
Now its time to create dashboard as asked find the next part at
https://siddharth1.medium.com/deploy-ml-project-as-dashboard-with-google-authentication-14fee8c6988c
End To End Machine Learning Extraction To Deployment. was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Siddharth Kshirsagar
Siddharth Kshirsagar | Sciencx (2022-03-27T15:28:13+00:00) End To End Machine Learning Extraction To Deployment.. Retrieved from https://www.scien.cx/2022/03/27/end-to-end-machine-learning-extraction-to-deployment/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.