
This content originally appeared on Level Up Coding - Medium and was authored by Floris Alexandrou
A Gentle Introduction to High Performance Computing

Intro
Supercomputing — nowadays known as High Performance Computing (HPC) — is mainly used for scientific and engineering purposes such as physical simulations, cryptanalysis, quantum mechanics, weather forecasting, molecular modeling, aerodynamics, nuclear fusion research, and many others. While personal computers operate at the scale of hundreds of gigaFLOPS (floating-point operations per second) to tens of teraFLOPS, recent supercomputers reach speeds of hundreds of petaFLOPS. To help grasp the difference in speed, one petaFLOPS consists of a thousand teraFLOPS. This huge speedup allows us to compute heavy data-intensive calculations in matters of minutes and hours instead of weeks and months. It sounds impressive but how are these computers so fast? To answer this question we first need to understand the difference between serial and parallel execution.
Serial VS Parallel Execution
Traditionally, personal computers with one core work in a sequential/serial order even though it appears that things run simultaneously. This effect of “fake” parallelization happens because the operating system’s scheduler enables the CPU to rapidly switch its processing power between programs/processes. This change happens so quickly that it remains unnoticed by the human brain.
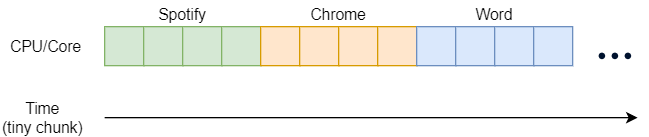
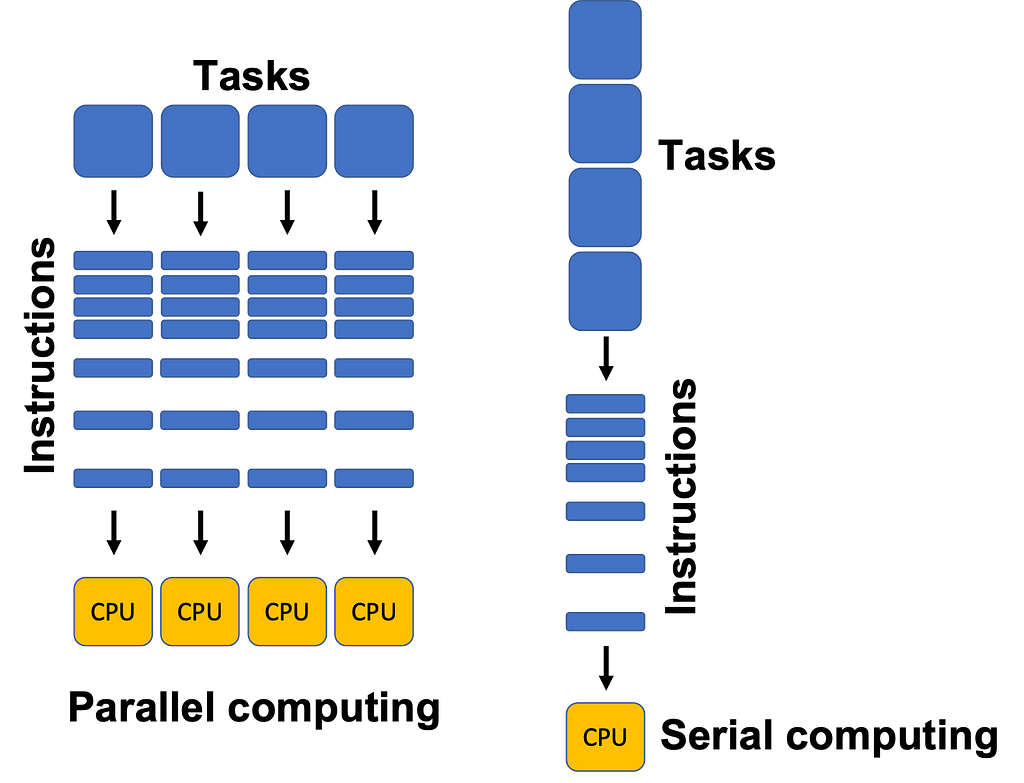
Real parallelization though can be achieved by having multiple CPUs/Cores that can either run independently or by taking a chunk of the same workload. We won’t get into the nitty details of threads and processes but as the image below illustrates, having multiple CPUs/Cores allows the computer to execute code in parallel, thus leading to a speed increase.
High Performance Computing (HPC) Clusters
A high performance computing cluster is made up of dozens to thousands of networked computing machines/nodes, where each node contains approximately 8 to 128 CPUs/Cores. For example, executing code on 10 nodes with 16 cores each allows us to have 160 processes operating in parallel, enhancing processing speed, thus enabling high performance computing.
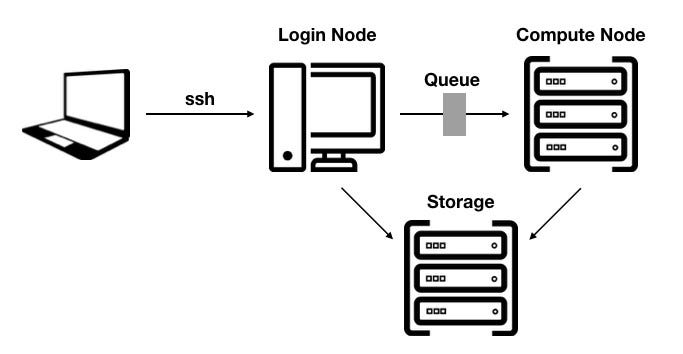
An HPC cluster typically also includes a login node from which users connect to the cluster with their own computer using ssh. Then, using specific slurm (Simple Linux Utility for Resource Management) script commands, batch jobs can be submitted to the cluster’s scheduler for execution.
HPC Standards & Frameworks
In this section we will briefly go over the most popular HPC libraries and frameworks, starting off with OpenMP which is used under the hood by most parallel processing frameworks. OpenMP stands for Open Multi-Processing and it is a cross-platform shared-memory multiprocessing API for C, C++, and Fortran. Realistically, the sole use of OpenMP might be insufficient as it can only parallelize code within a single node whose processing power might not be enough for demanding calculations. MPI (Message Passing Interface) on the other hand allows the parallelization of code across multiple nodes. The most popular MPI library is OpenMPI, which — along with OpenMP — is open source, endorsed and standardized by the industry and academia.

{kind=link}
Even when using multiple nodes, various problems require even more processing power. Specifically, computations that are related to matrix transformations such as computer graphics rendering or neural network training, are more suitable to be executed on the GPU (Graphics Processing Unit). Luckily there are a few frameworks that enable this execution, such as CUDA (Compute Unified Device Architecture) for Nvidia GPUs and OpenCL (Open Computing Language) which offers support for both AMD and Nvidia graphics cards. Typically, Cuda and MPI are combined to enable the execution of code on multiple GPUs across multiple nodes, thus maximizing the performance output.
OpenMP Demo
In this section, we will see how code can be parallelized using OpenMP as well as its speed benefit. The code shown in the image below has no semantic meaning as it’s used only for demonstration purposes. In brief terms, it creates two random arrays of size 50000 and performs some basic calculations (multiplication, division and addition) for 5 million iterations (2 x L x L).
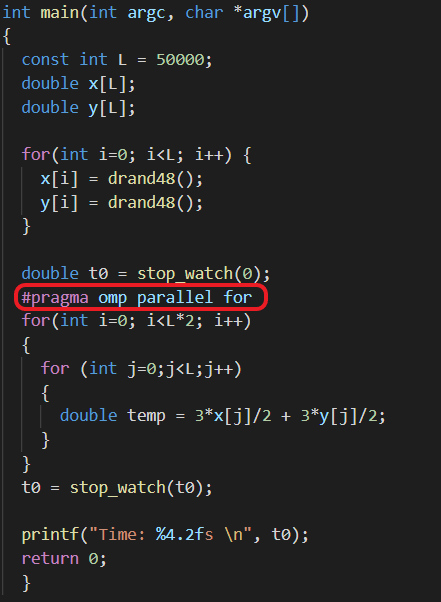
The OpenMP keyword “#pragma omp parallel for” is used to parallelize the outer for loop across multiple threads. For example, instead of iterating 100k times (2 x L) on a single thread, we can run the program with 4 threads, so that it iterates 25k (100k / 4) times on each thread in parallel. It’s important to note that the “stop_watch” function is used to calculate the time needed to execute the parallel region (code inside the for loop) and not the whole program.

As shown in the images above and below, executing the program with 1 thread takes ~41 seconds, while executing with 8 threads takes ~6 seconds. That is almost 7 times faster. It’s always slower than what we’d expect (8 times faster) because opening and closing parallel regions consumes resources.

The code was executed on Cyclamen for which I was granted access to complete the Introduction to High Performance Computing course at The Cyprus Institute.
Thank you for reading as I hope this article will spark your curiosity to learn more about the amazing world of supercomputers.
References
- https://www.suse.com/suse-defines/definition/supercomputer/
- https://pythonnumericalmethods.berkeley.edu/notebooks/chapter13.01-Parallel-Computing-Basics.html
- https://www.netapp.com/data-storage/high-performance-computing/what-is-hpc/
- https://www.ssh.com/academy/ssh/protocol
- https://slurm.schedmd.com/
- https://www.openmp.org/
- https://www.open-mpi.org/
- https://developer.nvidia.com/cuda-toolkit
- https://www.khronos.org/opencl/
How do supercomputers work? was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Floris Alexandrou
Floris Alexandrou | Sciencx (2022-03-29T19:42:15+00:00) How do supercomputers work?. Retrieved from https://www.scien.cx/2022/03/29/how-do-supercomputers-work/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.