
This content originally appeared on DEV Community and was authored by Deepesha Burse
One of the most popular models in the time series domain is LSTM – Long Short-Term Memory model. It is a type of recurrent neural network and is heavily used in sequence prediction. In this blog, we will go through why LSTM is preferred and how it works. Before jumping into LSTM, let us dive a little deeper into what these terms mean.
Time Series Analysis – In this, data points are analyzed over specific intervals of time. It is used to understand the pattern over a period of time, could be monthly, yearly, or even daily. This kind of analysis can be seen in stock price predictions or in businesses.
Neural Network – A neural network consists of multiple algorithms that is majorly used to analyze the underlying relationship between various data points. It is inspired by the biological neural network.

Recurrent Neural Network (RNN) – If we have data points which are related, then we use RNNs. RNNs use the concept of memory, where they store certain data points. The problem with traditional RNNs is that as the number of data points increases, they are unable to remember data. Say, we want to process a paragraph of text to do predictions, RNN’s may leave out important information from the beginning.
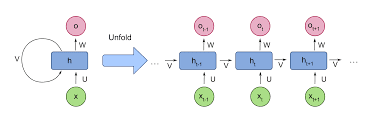
LSTM is a special type of RNN where it stores data long term. It overcomes two technical problems vanishing gradients and exploding gradients. An LSTM module consists of a cell state and 3 gates. The cell state is like a conveyer belt, it allows information to flow linearly with minor changes. The model does have the ability to remove or add information, this is done using the 3 gates. The gates help in regulating the information. But as the flow of information is linear, it makes the flow easier.

Architecture of LSTM:
In LSTM, there are three main steps. We either forget, input or output. An analogy for this would be how news channels work. Say, there is a murder case that they are broadcasting and initially it is suspected that the cause of death is poisoning, but once the post mortem report comes through, the cause of death turns out to be an injury on the head, the information about the poisoning is “forgotten”.
Similarly, if there were 3 suspects and then another suspected. This person is added or “inputted”.
Finally, after the investigation of the police, there is a prime suspect, this information will be “outputted”.
To carry out these three steps, we have 3 gates. Let us look at each one of them in detail:
1. Forget gate:
A forget gate is responsible for removing information. It removes information that is no longer needed for analysis and vacates space for the next information. This helps the model to become more efficient.

This gate takes in 2 inputs,
- ht_1: Hidden state from previous cell
- x_t: Input at the particular step
These inputs are multiplied by the weight matrices and then a bias is added. Following this, the sigmoid function is applied to the calculated value. The sigmoid function gives an output between 0 and 1. This helps the model decide which information to “forget”. If the output is 0, the information of that cell is forgotten completely. Similarly, if the output is 1, the information of that entire cell is to be remembered. This vector output from the sigmoid function is multiplied with the cell state.
2. Input gate:
This gate, as the name suggests, is used to add information to the cell state. Here is its structure,

First, the values that need to be added are regulated using the sigmoid function. The inputs are still h_t-1 and x_t. Next, a vector is created which contains all the possible values to be added to the cell state. This is done using the tan h function. Tan outputs a value between -1 to +1. The value of the regulatory function (sigmoid function) is multiplied with the created vector. The useful information is then added to the cell state using the addition operation.
This allows us to make sure we have only filtered and important information.
3. Output gate:
This gate is used to use the information currently available and show the most relevant output. It looks like this:
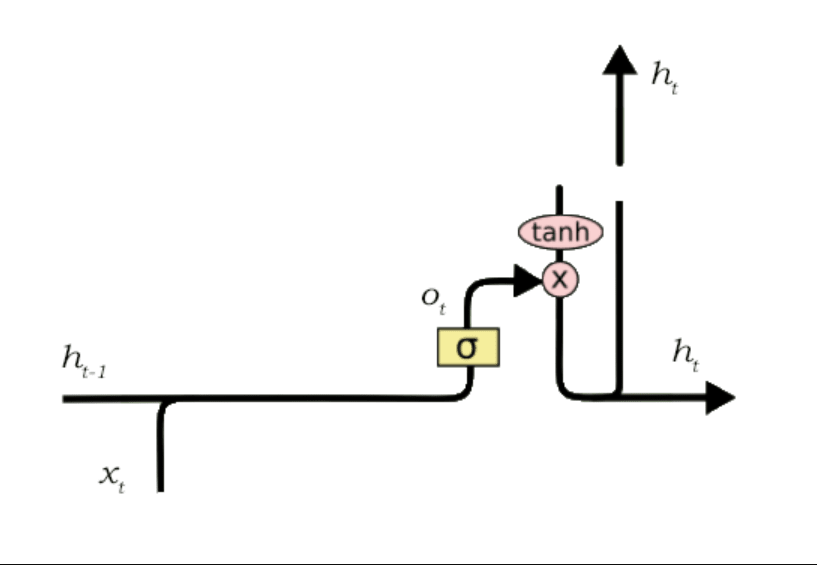
A vector is created after applying the tan h function to the cell state. The output ranges between -1 and +1. The sigmoid function is again used to regulate the values that need to be outputted from the vector using h_t-1 and x_t. The value of the regulatory function is multiplied with the vector and sent as the output. It is also sent to the hidden state of the next cell.
LSTMs have proven to give state of the art results in sequence predictions. It is used in complex problem domains like machine translation, speech recognition, text generation, etc. I hope this gave you a basic idea on how LSTM models work.
References:
Essentials of Deep Learning : Introduction to Long Short Term Memory
Illustrated Guide to LSTM’s and GRU’s: A step by step explanation
This content originally appeared on DEV Community and was authored by Deepesha Burse
Deepesha Burse | Sciencx (2022-03-30T17:29:24+00:00) How does LSTM work?. Retrieved from https://www.scien.cx/2022/03/30/how-does-lstm-work/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.