
This content originally appeared on Level Up Coding - Medium and was authored by Sean Nolan

As the story goes, Steve Jobs once commissioned a study to determine the safest long-term storage medium for Apple’s source code. After evaluating all the most advanced technologies of the day ( LaserDisc!), the team ended up printing it all out on acid-free paper to be stored deep within the low-humidity environment at Yucca Mountain — the theory being that our eyes were the most likely data retrieval technology to survive the collapse of civilization. Of course this is almost certainly false, but I love it anyways. Just like the (also false) Soviet-pencils-in-space story, there is something very Jedi about simplicity outperforming complexity. If you need me, I’ll be hanging out in the basement with Mike Mulligan and Mary Anne.
Anyways, I was reminded of the Jobs story the other day because long-term data storage is something of a recurring challenge in the Nolan household. In the days of hundreds of free gigs from consumer services, you wouldn’t think this would be an issue, and yet it is. In particular my wife takes a billion pictures (her camera takes something like fifty shots for every shutter press), and my daughter has created an improbable tidal wave of video content.
Keeping all this stuff safe has been a decades-long saga including various server incarnations, a custom-built NAS in the closet, the usual online services, and more. They all have fatal flaws, from reliability to cost to usability. Until very recently, the most effective approach was a big pile of redundant drives in a fireproof safe. It’s honestly not a terrible system; you can get 2TB for basically no money these days, so keeping multiple copies of everything isn’t a big deal. Still not great though — mean time to failure for both spinning disks and SSD remains sadly low — so we need to remember to check them all a couple of time each year to catch hardware failures. And there’s always more. A couple of weeks ago, as my daughter’s laptop was clearly on the way out, she found herself trying to rescue yet more huge files that hadn’t made it to the safe.
Enter Glacier (and, uh, “Archive”)
It turns out that in the last five years or so a new long-term storage approach has emerged, and it is awesome.
Object (file) storage has been a part of the “cloud” ever since there was a “cloud” — Amazon calls their service S3; Microsoft calls theirs Blob Storage. Conceptually these systems are quite simple: files are uploaded to and downloaded from virtual drives (“buckets” for Amazon, “containers” for Azure) using more-or-less standard web APIs. The files are available to anyone anywhere that has the right credentials, which is super-handy. But the real win is that files stored in these services are really, really unlikely to be lost due to hardware issues. Multiple copies of every file are stored not just on multiple drives, but in multiple regions of the world — so they’re good even if Lex Luthor does manage to cleave off California into the ocean (whew). And they are constantly monitored for hardware failure behind the scenes. It’s fantastic.
But as you might suspect, this redundancy doesn’t come for free. Storing a 100 gigabyte file in “standard” storage goes for about $30 per year (there are minor differences between services and lots of options that can impact this number, but it’s reasonably close), which is basically the one-and-done cost of a 2 USB stick! This premium can be very much worth it for enterprises, but it’s hard to swallow for home use.
Ah, but wait. These folks aren’t stupid, and realized that long-term “cold” storage is its own beast. Once stored, these files are almost never looked at again — they just sit there as a security blanket against disaster. By taking them offline (even just by turning off the electricity to the racks), they could be stored much more cheaply, without sacrificing any of the redundancy. The tradeoff is only that if you do need to read the files, bringing them back online takes some time (about half a day generally) — not a bad story for this use case. Even better, the teams realized that they could use the same APIs for both “active” and “cold” file operations — and even move things between these tiers automatically to optimize costs in some cases.
Thus was born Amazon Glacier and the predictably-boringly-named Azure Archive Tier. That same 100GB file in long-term storage costs just $3.50 / year … a dramatically better cost profile, and something I can get solidly behind for family use. Woo hoo!
But Wait
The functionality is great, and the costs are totally fine. So why not just let the family loose on some storage and be done with it? As we often discover, the devil is in the user experience. Both S3 and Blob Service are designed as building blocks for developers and IT nerds — not for end users. The native admin tools are a non-starter; they exist within an uber-complex web of cloud configuration tools that make it very easy to do the wrong thing. There are a few hideously-complicated apps that all look like 1991 FTP clients. And there are a few options for using the services to manage traditional laptop backups, but they all sound pretty sketchy and that’s not our use case here anyways.
Sounds like a good excuse to write some code! I know I’m repeating myself but … whether it’s your job or not, knowing how to code is the twenty-first century superpower. Give it a try.

The two services are basically equivalent; I chose to use Azure storage because our family is already deep down the Microsoft rabbit hole with Office365. And this time I decided to bite the bullet and deploy the user-facing code using Azure as well — in particular an Azure Static Web App using the Azure Storage Blob client library for JavaScript. You can create a “personal use” SWA for free, which is pretty sweet. Unfortunately, Microsoft’s shockingly bad developer experience strikes again and getting the app to run was anything but “sweet.” At its height my poor daughter was caught up in a classic remote-IT-support rodeo, which she memorialized in true Millennial Meme form.
Anyhoo — the key features of an app to support our family use case were pretty straightforward:
- Simple user experience, basically a “big upload button”.
- Login using our family Office365 accounts (no new passwords).
- A segregated personal space for each user’s files.
- An “upload” button to efficiently push files directly into the Archive tier.
- A “thaw” button to request that a file be copied to the Cool tier so it can be downloaded.
- A “download” button to retrieve thawed files.
- A “delete” button to remove files from either tier.
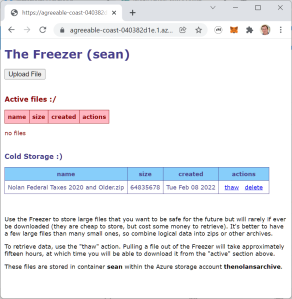
One useful feature I skipped — given that the “thawing” process can take about fifteen hours, it would be nice to send an email notification when that completes. I haven’t done this yet, but Azure does fire events automatically when rehydration is complete — so it’ll be easy to add later.
For the rest of this post, we’ll decisively enter nerd-land as I go into detail about how I implemented each of these. Not a full tutorial, but hopefully enough to leave some Google crumbs for folks trying to do similar stuff. All of the code is up on github in its own repository; feel free to use any of it for your own purposes — and let me know if I can help with anything there.
Set up the infrastructure
All righty. First you’ll need an Azure Static Web App. SWAs are typically deployed directly from github; each time you check in, the production website will automatically be updated with the new code. Set up a repo and the Azure SWA using this quickstart (use the personal plan). Your app will also need managed APIs — this quickstart shows how to add and test them on your local development machine. These quickstarts both use Visual Studio Code extensions — it’s definitely possible to do all of this without VSCode, but I don’t recommend it. Azure developer experience is pretty bad; sticking to their preferred toolset at least minimizes unwelcome surprises.
You’ll also need a Storage Account, which you can create using the Azure portal. All of the defaults are reasonable, just be sure to pick the “redundancy” setting you want (probably “Geo-redundant storage”). Once the account has been created, add a CORS rule (in the left-side navigation bar) that permits calls from your SWA domain (you’ll find this name in the “URL” field of the overview page for the SWA in the Azure portal).
Managing authentication with Active Directory
SWAs automatically support authentication using accounts from Active Directory, Github or Twitter (if you choose the “standard” pricing plan you can add your own). This is super-nice and reason alone to use SWA for these simple little sites — especially for my case where the users in question are already part of our Azure AD through Office365. Getting it to work correctly, though, is a little tricky.
Code in your SWA can determine the users’ logged-in status in two ways: (1) from the client side, make an Ajax call to the built-in route /.auth/me, which returns a JSON object with information about the user, including their currently-assigned roles; (2) from API methods, decode the x-ms-client-principal header to get the same information.
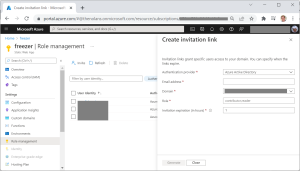
By default, all pages in a SWA are open for public access and the role returned will be “anonymous”. Redirecting a user to the built-in route /.auth/aad will walk them through a standard AD login experience. By default anyone with a valid AD account can log in and will be assigned the “authenticated” role. If you’re ok with that, then good enough and you’re done. If you want to restrict your app only to specific users (as I did), open up the Azure portal for your SWA and click “Role management” in the left-side navigation bar. From here you can “invite” specific users and grant them custom roles (I used “contributor”) — since only these users will have your roles, you can filter out the riff-raff.
Next you have to configure routes in the file staticwebapp.config.json in the same directory with your HTML files to enforce security. There’s a lot of ways to do this and it’s a little finicky because your SWA has some hidden routes that you don’t want to accidentally mess with. My file is here; basically it does four things:
- Allows anyone to view the login-related pages (/.auth/*).
- Restricts the static and api files to users that have my custom “contributor” role.
- Redirects “/” to my index.html page.
- Redirects to the AD auth page when needed to prompt login.
I’m sure there’s a cleaner way to make all this happen, but this works and makes sense to me, so onward we go.
Displaying files in storage
The app displays files in two tables: one for archived files (in cold storage) and one for active ones that are either ready to download or pending a thaw. Generating the actual HTML for these tables happens on the client, but the data is assembled at the server. The shared “Freezer” object knows how to name the user’s personal container from their login information and ensure it exists. The listFiles method then calls listBlobsFlat to build the response object.
There are more details on the “thawing” process below, but note that if a blob is in the middle of thawing we identify it using the “archiveStatus” property on the blob. Other than that, this is a pretty simple iteration and transformation. I have to mention again just how handy JSON is these days — it’s super-easy to cons up objects and return them from API methods.
Remember the use case here is storing big files — like tens to hundreds of gigabytes big. Uploading things like that to the cloud is a hassle no matter how you do it, and browsers in particular are not known for their prowess at the job. But we’re going to try it anyways.
In the section above, the browser made a request to our own API (/api/listFiles), which in turn made requests to the Azure storage service. That works fine when the data packages are small, but when you’re trying to push a bunch of bytes, having that API “middleman” just doesn’t cut it. Instead, we want to upload the file directly from the browser to Azure storage. This is why we had to set up a CORS rule for the storage account, because otherwise the browser would reject the “cross-domain” request to https://STORAGE_ACCT.blob.core.windows.net where the files live.
The same client library that we’ve been using from the server (node.js) environment will work in client-side JavaScript as well — sort of. Of course because it’s a Microsoft client library, they depend on about a dozen random npm packages ( punycode, tough-cookie, universalify, the list goes on), and getting all of this into a form that the browser can use requires a “bundler.” They actually have some documentation on this, but it leaves some gaps — in particular, how best to use the bundled files as a library. I ended up using webpack to make the files, with a little index.js magic to expose the stuff I needed. It’s fine, I guess.
The upload code lives here in index.html. The use of a hidden file input is cute but not essential — it just gives us a little more control over the ux. Of course, calls to storage methods need to be authenticated; our approach is to ask our server to generate a “ shared access signature” (SAS) token tied to the blob we’re trying to upload — which happens in freezer.js (double-duty for upload and download). The authenticated URL we return is tied only to that specific file, and only for the operations we need.
The code then calls the SDK method BlockBlobClient.uploadData to actually push the data. This is the current best option for uploading from the browser, but to find it you have to make your way there through a bunch of other methods that are either gone, deprecated or only work in the node.js runtime. The quest is worthwhile, though, because there is some good functionality tucked away in there that is key for large uploads:
- Built in retries (we beef this up with retryOptions).
- Clean cancel using an AbortController.
- A differentiated approach for smaller files (upload in one shot) vs. big ones (upload in chunks).
- When uploading in chunks, parallel upload channels to maximize throughput. This one is tricky — since most of us in the family use Chrome, we have to be aware of the built-in limitation of five concurrent calls to the same domain. In the node.js runtime it can be useful to set the “concurrency” value quite high, but in the browser environment that will just cause blocked requests and timeout chaos. This took me awhile to figure out … a little mention in the docs might be nice folks.
With all of this, uploading seems pretty reliable. Not perfect though — it still dies with frustrating randomess. Balancing all the config parameters is really important, and unfortunately the “best” values change depending on available upload bandwidth. I think I will add a helper so that folks can use the “ azcopy “ tool to upload as well — it can really crank up the parallelization and seems much less brittle with respect to network hiccups. Command-line tools just aren’t very family friendly, but for what it’s worth:
- Download azcopy and extract it onto your PATH.
- Log in by running azcopy login ... this will tell you to open up a browser and log in with a one-time code.
- Run the copy with a command like azcopy cp FILENAME https://STORAGE_ACCT.blob.core.windows.net/CONTAINER/FILENAME --put-md5 --block-blob-tier=Archive.
- If you’re running Linux, handy to do #3 in a screen session so you can detach and not worry about logging out.
Thawing
Remember that files in the Archive tier can’t be directly downloaded — they need to be “rehydrated” (I prefer “thawed”) out of Archive first. There are two ways to do this: (1) just flip the “tier” bit to Hot or Cool to initiate the thaw, or (2) make a duplicate copy of the archived blob, leaving the original in place but putting the new one into an active tier. Both take the same amount of time to thaw (about fifteen hours), but it turns out that #2 is usually the better option for cold-storage use cases. The reason why comes down to cost management — if you move a file out of archive before it’s been there for 180 days, you are assessed a non-trivial financial penalty (equivalent to if you were using an active tier for storage the whole time). Managing this time window is a hassle and the copy avoids it.
So this should be easy, right? Just call beginCopyFromURL with the desired active tier value in the options object. I mean, that’s what the docs literally say to do, right?
Nope. For absolutely no reason that I can ascertain online, this doesn’t work in the JavaScript client library — it just returns a failure code. Classic 2020 Microsoft developer experience … things work in one client library but not another, the differences aren’t documented anywhere, and it just eats hour after hour trying to figure out what is going on via Github, Google and Stack Exchange. Thank goodness for folkslike this that document their own struggles … hopefully this post will show up in somebody else’s search and help them out the same way.
Anyways, the only approach that seems to work is to just skip the client library and call the REST API directly. Which is no big deal except for the boatload of crypto required. Thanks to the link above, I got it working using the crypto-js npm module. I guess I’m glad to have that code around now at least, because I’m sure I’ll need it again in the future.
But wait, we’re still not done! Try as I might, the method that worked on my local development environment would not run when deployed to the server: “CryptoJS not found”. Apparently the emulator doesn’t really “emulate” very well. Look, I totally understand that this is a hard job and it’s impossible to do perfectly — but it is crystal clear that the SWA emulator was hacked together by a bunch of random developers with no PM oversight. Argh.
By digging super-deep into the deployment logs, it appeared that the Oryx build thingy that assembles SWAs didn’t think my API functions had dependent modules at all. This was confusing, since I was already dependent on the @azure/storage-blob package and it was working fine. I finally realized that the package.json file in the API folder wasn’t listing my dependencies. The same file in the root directory (where you must run npm install for local development) was fine. What the f*ck ever, man … duping the dependencies in both folders fixed it up.
Downloading and Deleting
The last of our tasks were to implement download and delete — thankfully, not a lot of surprises with these. The only notable bit is setting the correct Content-Type and Content-Disposition headers on download so that the files saved as downloaded files, rather than opening up in the browser or whatever other application is registered. Hooray for small wins!
That’s All Folks
What a journey. All in all it’s a solid little app — and great functionality to ensure our family’s pictures and videos are safe. But I cannot overstate just how disappointed I am in the Microsoft developer experience. I am particularly sensitive to this for two reasons:
First, the fundamental Azure infrastructure is really really good! It performs well, the cost is reasonable, and there is a ton of rich functionality — like Static Web Apps — that really reduce the cost of entry for building stuff. It should be a no-brainer for anyone looking to create secure, modern, performant apps — not a spider-web of sh*tty half-assed Hello World tutorials that stop working the day after they’re published.

Even worse for my personal blood pressure, devex used to be the crown jewel of the company. When I was there in the early 90s and even the mid 00s, I was really, really proud of how great it was to build for Windows. Books like Advanced Windows and Inside OLE were correct and complete. API consistency and controlled deprecation were incredibly important — there was tons of code written just to make sure old apps kept working. Yes it was a little insane — but I can tell you it was 100% sincere.
Building for this stuff today feels like it’s about one third coding, one third installing tools and dependencies, and one third searching Google to figure out why nothing works. And it’s not just Microsoft by any means — it just hurts me the most to see how far they’ve fallen. I’m glad to have fought the good fight on this one, but I think I need a break … whatever I write next will be back in my little Linux/Java bubble, thank you very much.
Originally published at http://shutdownhook.com on February 14, 2022.
Cold Storage on Azure was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Sean Nolan
Sean Nolan | Sciencx (2022-04-03T15:20:41+00:00) Cold Storage on Azure. Retrieved from https://www.scien.cx/2022/04/03/cold-storage-on-azure/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.