
This content originally appeared on DEV Community and was authored by qazmkop
The previous article, "The design concept of the best open-source project about big data and data lakehouse" introduced the design concept and partial realization principle of LakeSoul's open-source and stream batch integrated surface storage framework. The original intention of the design of LakeSoul is to solve various problems that are difficult to solve in traditional Hive data warehouse scenarios, including Upsert update, Merge on Read, and concurrent write. This article will demonstrate the core capabilities of LakeSoul using a typical application scenario: building a real-time machine learning sample library.
1. Background of business requirements
1.1 Online recommendation system
In the Internet, finance, and other industries, many business scenarios, such as search, advertising, recommendation, risk control, etc., can be summarized as an online personalized recommendation system. For example, in the e-commerce business, customized "guess you like" recommendations based on the personalized recommendation system can improve users' click rate and purchase rate. In the advertising business, the personalized recommendation is the core system for achieving proper orientation and improving ROI. In financial risk control, it is necessary to realize the real-time prediction of users' repayment ability and overdue possibility and provide a personalized credit line and loan repayment cycle for each user.
Recommendation system has been widely used in various industries. Building an industrial-grade online recommendation system requires the connection of many links and systems, spending a large amount of time on the development work. The MetaSpore framework developed by DmetaSoul provides a one-stop recommendation system development solution. Please refer to my previous post, "The design concept of an almighty Opensource project about machine learning platform."
This paper focuses on building a real-time sample database to realize the complete closed loop of "user feedback-model iteration." The recommendation system can learn and iterate independently and quickly capture user interest changes.
1.2 What is the sample library of recommendation System machine learning?
In the recommendation system, the core part is an algorithm model of personalized sorting. Model training starts with constructing samples and learning each user's preference through various characteristics and user behavior feedback labels. A sample library usually consists of several parts:
- User Feature: includes the basic attributes, historical behaviors, and recent real-time behaviors of users. The basic attributes of users may come from real-time online requests or behavior labels mined by offline DMP. Users' historical and real-time behavior generally includes the events with feedback behaviors in the history of users and some relevant aggregate statistical indicators.
- Item-Feature: Item is the object to be recommended to users, which can be commodities, news, advertisements, etc. Features generally include all kinds of attributes of articles, including discrete attributes and continuous attributes of statistical values.
- User feedback: is the label in the algorithm model. Labels are all kinds of user feedback behaviors, such as show, click, transform, etc. Algorithmic models need to learn to model user preferences through the relationship between features and labels.
*1.3 Challenges of building the machine learning sample library *
There are several kinds of problems and challenges when building the machine learning sample library:
- Real-time requirements. The model learning of the mainstream recommendation system in the industry has developed in the direction of online and real-time. The more timely the model is updated, the faster it can capture the changes in users' interests, thus providing more accurate recommendation results and improving business effects, which requires the sample library to support a high write throughput capacity.
- Multi-stream updates. Many online features must be influenced in real-time for further model training after the online sorting calculation by the model. User feedback also needs to be fed back into the sample library, often with multiple live streams of user feedback. In this case, multiple live streams simultaneously write to different columns in the update sample library. Traditional Hive data storehouses generally cannot support real-time updates and must be implemented through full Join. However, the operation efficiency is low when the Join window is large and a large amount of data is redundant. The window Join of Flink also has the problem of enormous state data and high operation and maintenance costs.
- Parallel-experiments. In practical business development, algorithm engineers often need to conduct parallel experiments of multiple models to compare the results simultaneously. Different models may require different feature and label columns, updating differently. For example, Offline batch job computing generates some features, and these batch data also need to be inserted into the feature database.
- Feature backtracking. In algorithmic business development, Adding features is needed sometimes, while the same is true of backtracking models, requiring batch updates of new features to historical data. It is also challenging to implement efficiently in Hive.
There are many challenges in constructing a real-time sample database in the recommendation system algorithm scenario. The main problems of these challenges are that Hive data warehouse functions and performance are weak, and scenarios such as stream batch integration, incremental update, and concurrent write cannot be well supported. Bytedance and other companies have previously shared solutions based on Hudi to build recommendation system samples in streaming and batch integration. However, Hudi still has problems, such as concurrent updates in actual use.
Developed by DMetaSoul and an open-source streaming batch one body table storage framework, LakeSoul can solve these problems well. The following article details how to use LakeSoul to build a sample library of industrial-grade recommendation systems.
2 Building a real-time machine learning sample library
LakeSoul is a table storage framework designed for streaming batch scenarios with the following key features:
- Column level Update (Upsert)
- Support Merge on Read, which merges data while reading to improve write throughput
- Support object storage without file semantics
- Concurrent write, which can support multiple streams and batch jobs to update the same partition
- Distributed metadata management to improve the scalability of metadata
- Schema evolution allows you to add and delete columns of a table The overall design of building the machine learning sample library by LakeSoul is to use Upsert instead of Join to write multiple groups of features and labels into the same table by streaming and batch, respectively, achieving high concurrent write and read/write throughput. The following part explains the specific implementation process and fundamental principles in detail.
2.1 Primary key design
To enable efficient Merge, LakeSoul provides the ability to set primary keys. Divide the primary key columns in a table into a specified number of hash buckets evenly according to the number of hash buckets. In each bucket, the primary key columns are sorted and written. Merge several incremental files with the ordered primary key at reading time, obtaining the Merge result.
When recommending system sample libraries, the backflow of all features and tags is tagged with the request ID generated during an online request, used as the Join Key in offline Join scenarios. Therefore, you can use the request ID as the primary key of the LakeSoul sample table and the hour as the Range partition. Create the LakeSoul table in the Spark job as follows:
LakeSoulTable.createTable(data, path).shortTableName("sample").hashPartitions("request_id").hashBucketNum(100).rangePartitions("hour").create()
This creates a table with 'request_id' as the primary key, hash buckets 100, and hours as a Range partition.
2.2 Data writing and Concurrent update
Since the characteristics and labels come from different streams and batches, we need jobs from multiple streams or batches to update the SAMPLE table concurrently. Each data must have a request_id column and an hour column. When executing LakeSoulTable.Upsert, LakeSoul Spark Writer automatically repartitions buckets based on the request_id and writes data into the corresponding partition bucket according to the hour column. A batch of written data can have values of multiple Range partitions.
LakeSoul supports multi-stream concurrent Upsert, which can meet the needs of multi-stream real-time updates of the sample database. For example, there are two streams, namely feature reflux and label reflux data, which can be updated into the sample database in real-time by performing Upsert:
// Read feature reflow, update sample table
val featureStreamDF = spark.readStream...
val lakeSoulTable = LakeSoulTable.forPath(tablePath)
lakeSoulTable.upsert(featureStreamDF)
// Read label reflow, update sample sheet
val labelStreamDF = spark.readStream...
val lakeSoulTable = LakeSoulTable.forPath(tablePath)
lakeSoulTable.upsert(labelStreamDF)
Because the Merge operation is not required, only the current incremental data is written so that the writing can have a high throughput. In actual tests, the write rate of each core on cloud merchant object storage is over 30MB/s, that is, 30 Spark Executors, meaning that write speed can reach 1GB with one CPU Core allocated to each.
2.3 the Merge On the Read
LakeSoul automatically merges _Upsert _data when reading it. So the interface to read is no different from that to read a table:
val lakeSoulTable = LakeSoulTable.forPath(path)
lakeSoulTable.toDF.select("*").show()
It can also be queried using SQL Select statements. In the underlying implementation, for each hash bucket, as the primary key is already ordered, only an external merge of multiple ordered lists is required, as shown below:
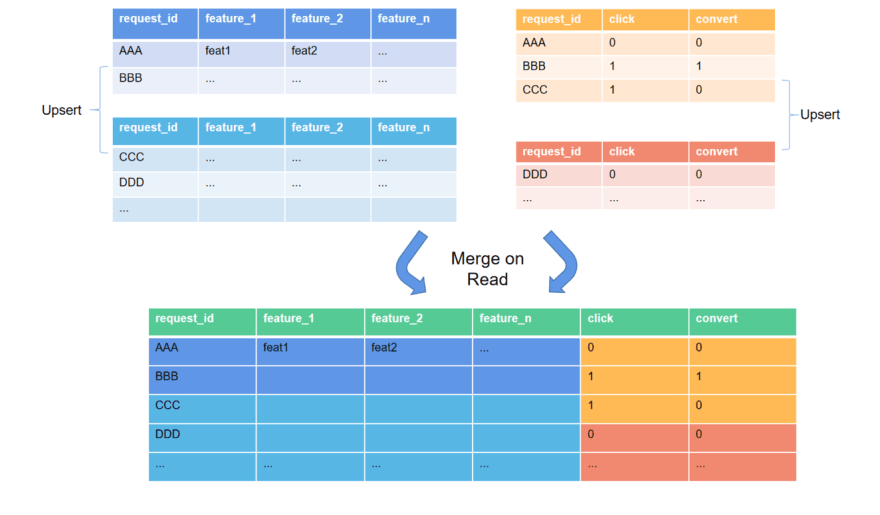
The figure shows that both the sample and label streams perform multiple _Upsert_s. LakeSoul will automatically find the incremental updated file based on the metadata service's update record and complete an ordered external merge when a read job works. LakeSoul implements ordered merging of Parquet files and improves the performance of multi-way ordered merging by optimizing the small top heap design.
2.4 Data Backfill
Since LakeSoul supports Upsert of any Range partitioned data, there is no difference between backtracking and streaming write. When the data to be inserted is ready, Spark performs Upsert to update historical data. LakeSoul automatically recognizes Schema changes. Update meta information of tables to implement Schema evolution. LakeSoul provides a complete storage function of data warehouse tables, and each historical partition can be queried and updated. Compared with Flink's window Join scheme, it solves the problem of invisible intermediate states and can quickly realize mass updates and traceability of historical data.
Conclusion
This article introduces the application of LakeSoul in a typical stream batch integration scenario, building the sample library of recommender system machine learning. LakeSoul stream batch integration, Merge on Read capability, can support large-scale, large window multi-stream real-time update, solve some problems existing in Hive warehouse mass Join and Flink window Join.
This content originally appeared on DEV Community and was authored by qazmkop
qazmkop | Sciencx (2022-05-06T14:17:08+00:00) Build a real-time machine learning sample library using the best open-source project about big data and data lakehouse, LakeSoul. Retrieved from https://www.scien.cx/2022/05/06/build-a-real-time-machine-learning-sample-library-using-the-best-open-source-project-about-big-data-and-data-lakehouse-lakesoul/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.