
This content originally appeared on Bits and Pieces - Medium and was authored by Akash Yadav
The problem with different flows of code execution and how we can solve with it.
In our previous post, we looked at different flows of code executions and introduce the synchronous and asynchronous nature of programming.
In this article, we will understand the problem we can solve with it.
Many times, our programs are written like this:
System.out.println("Enter value");
// waiting for input from keyboard
Scanner sc = sc.nextInt();
System.out.println("Value entered is : " + sc);// waiting for the data to be available at nic
String name = db.query("Select first_name from users where id=1");
System.out.println("Name : " + firstName);
What’s common in both these above code snippets ?. In both cases, we are wasting lots of CPU cycles and doing nothing at all, and waiting for the data to be available.
When executing an I/O bound task such as file IO, or network IO on network interface cards, the computing devices spend their time performing these IO operations, and the CPU sits idle during this time.
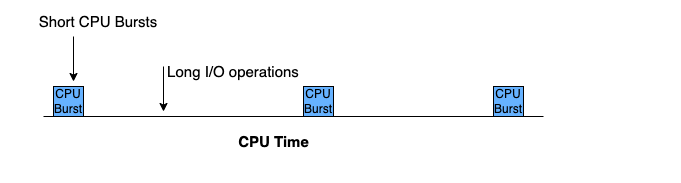
In an IO-bound task, we have a small CPU burst i.e the amount of time taken to execute a task, and long IO blocks.
Here is the benchmark of IO latency:

IO blocks are the worst.
If our application is CPU intensive and performs tons of CPU calculations there is no way to scale it without adding more resources and more CPU cores to it. What we are more worried about is the thread that gets blocks on IO.
A thread is a unit of computation and only one thread can run on the CPU core at a given point in time. Having a lot of threads being blocked on IO will eventually mean that most of the threads are just stuck waiting for their turn to get scheduled.
Network IO wastes most of the CPU resource and in a microservice architecture, this can be very costly. When we make an API call or query to the database the thread on which the call was made waits around till the data is being received, after which the sequential execution of code begins again. Also known as the one thread-per-request or thread-per-connection model.
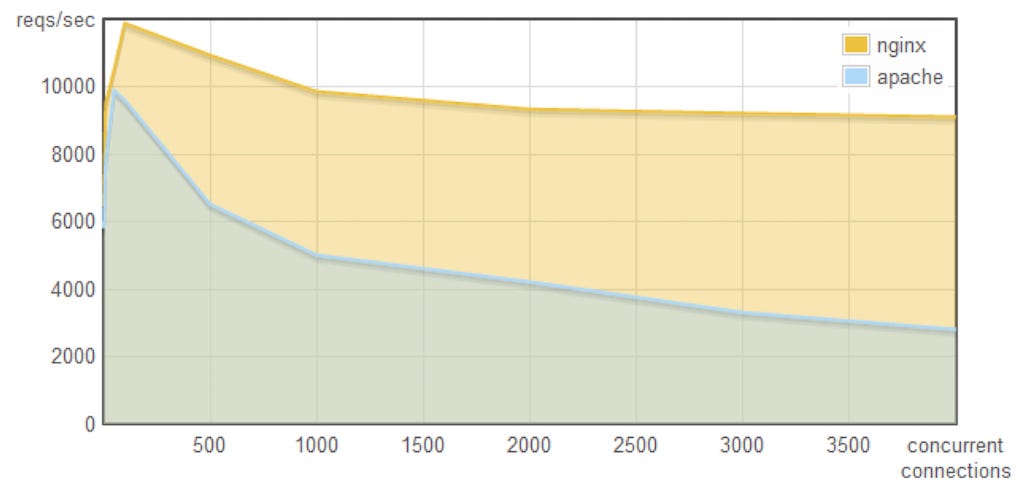
In the first graph, we can see as the number of concurrent connections keeps getting increasing throughput is getting decreased and now we are serving less number of requests per second on the Apache webserver.
On the other hand, there is much less effect on the Nginx webserver. This is because Apache uses one thread per request or connection which leads to having too many threads causing frequent context switches.
Context switching between the different threads is not free it cost some CPU time.
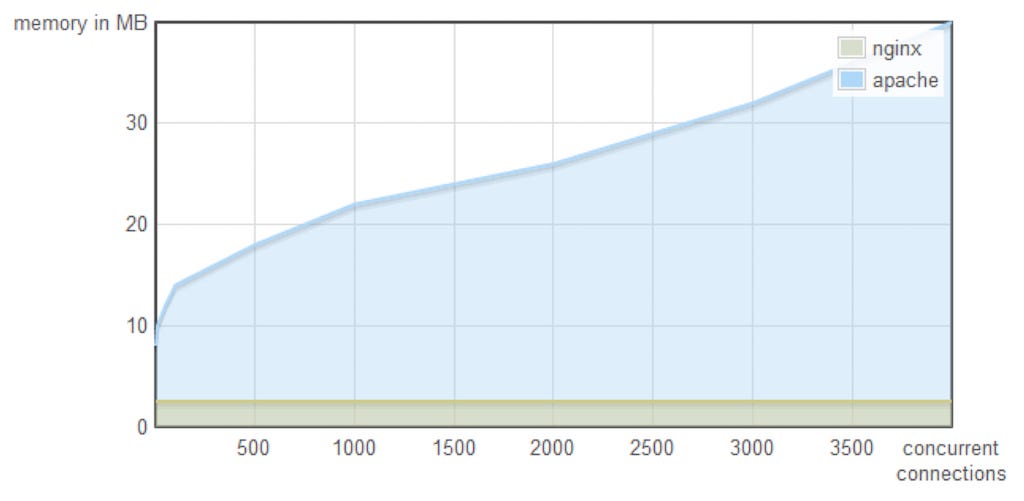
In the second graph, we can see the memory footprint of the Nginx web server is way lower than the apache one. Nginx doesn’t use threads. It uses an event loop which results in consuming less memory.
On the other hand, creating a thread for every conn. or request takes considerable memory per thread and that ends up being consuming a lot of memory.
We now will be introducing different concurrency models to deal with these problems in this blog. How they do it will be covered in successive blogs.
1. User Space aka LightWeight Threads
Apache uses OS/Kernel-level threads. There is another threading system called user-level thread or co-routines aka lightweight threads. These can help the situation pretty much, serving more requests and bringing down the memory footprint to a good extent.
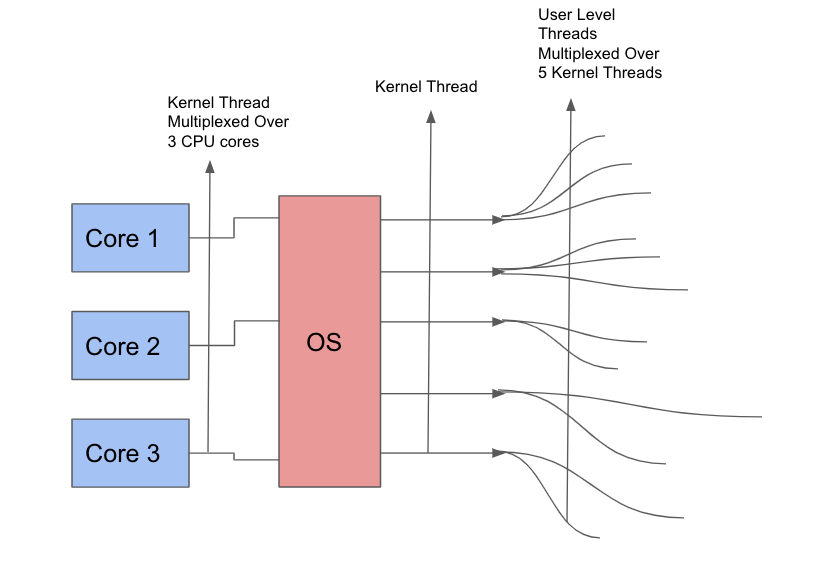
This model separates User-level threads (threads started and used by our application in this case language runtime) from Kernel threads (those managed by underlying OS). In this model multiple user-level threads
are multiplexed over a single kernel thread which in turn multiplexed over an even smaller number of CPU cores.
User-level threads make the execution lightweight as it does not involve a full context switch. So whenever some user thread is blocked on an IO task, the language runtime scheduler swaps it out with another user-level thread keeping the underlying kernel thread the same.
The disadvantage of this model is that there is still a piece of machinery involved in making the execution thread-safe, we still have locking, leaking, and memory problems. The other worst-case we can think of is what if all the application code is blocking, then at some point, the user-level scheduler will start creating new user-level threads and will start running into the same “too many thread scenario”
2. Asynchronous Programming
Asynchronous execution means that the thread that launched the task does not needs to wait for the task to complete to continue to work and can get the result at some point in the future. They are then notified when the task is complete and they can resume execution of code from that point onwards.
In this model, two flavors of asynchronous programming are there
Thread Based
The thread-based model also known as the worker-pool model, tries to achieve a semblance of asynchronicity by creating different thread pools for different tasks and having threads hand over tasks to the correct pool for actual execution thereby unblocking themselves.
The designated pool carries out the blocking task (incurring the same blocking overhead as the traditional programming model but over a limited set of threads) and then notifies the original thread of completion.
In this model, threads are not multiplexed onto the same kernel thread instead there is only one on-mapping of kernel-level thread to a user-level thread. The creation of a new user thread indeed has some new kernel thread underneath it and participates in a full context switch by the scheduler.
Event-Based
This model was made popular by the node.js which uses kernel capabilities using a library called libuv implemented in C/C++ to make processing truly non-blocking for all thread.
A thread starts an IO task and registers it with the kernel, stashes away the entire call stack, and goes on to do other things.
The kernel watches all the tasks thereby reducing blocking behavior to one thread in the entire system and notifying the submitting thread by an event with the result when the task is complete.
No application thread is ever blocked.
Both the above models rely on callbacks to handle the interruption of task completion.
Thanks for reading this long. In the successive articles, we will explore how both these asynchronous programming able to achieve asynchronicity.
Read Next
I would love to hear from you. You can reach me for any query, feedback, or just want to have a discussion through the following channels:
Drop me a message on Linkedin or email me on akash.codingforliving@gmail.com
Build composable web applications
Don’t build web monoliths. Use Bit to create and compose decoupled software components — in your favorite frameworks like React or Node. Build scalable and modular applications with a powerful and enjoyable dev experience.
Bring your team to Bit Cloud to host and collaborate on components together, and speed up, scale, and standardize development as a team. Try composable frontends with a Design System or Micro Frontends, or explore the composable backend with serverside components.

Learn more
- Building a Composable UI Component Library
- How We Build Micro Frontends
- How we Build a Component Design System
- How to build a composable blog
- The Composable Enterprise: A Guide
- Meet Component-Driven Content: Applicable, Composable
- Sharing Components at The Enterprise
Reducing I/O overhead was originally published in Bits and Pieces on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Bits and Pieces - Medium and was authored by Akash Yadav
Akash Yadav | Sciencx (2022-06-03T11:47:39+00:00) Reducing I/O overhead. Retrieved from https://www.scien.cx/2022/06/03/reducing-i-o-overhead/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.