
This content originally appeared on DEV Community and was authored by qazmkop
1.Log in
Click on the link Alpha IDE: https://registry-alphaide.dmetasoul.com/#/login. You can register by email.
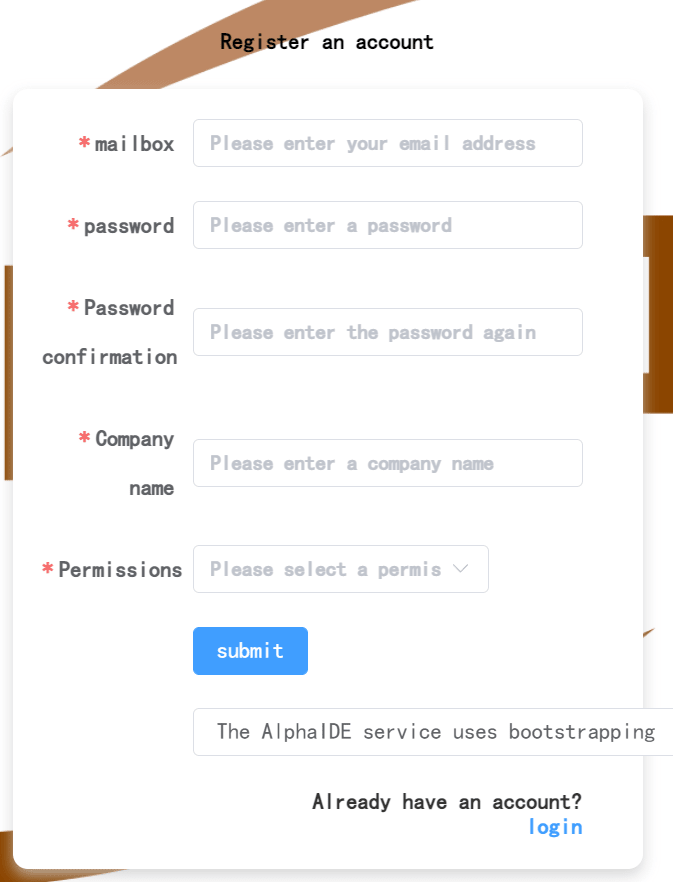
After registration, the email will receive a verification link. After clicking the verification link, you can log in through the email address and password you just registered.
After login, click to enter the trial IDE environment
If the login page is displayed, use the previous email password to log in.
2. The Usage of IDE
2.1 Creating a Namespace
First, in the left navigation bar, go to kubeflow-Home:
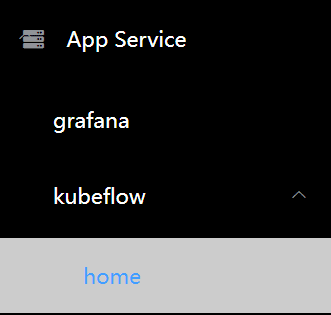
On the Kubeflow initialization page, click Start Setup.

Then on the Namespace creation page, click Finish. The default Namespace is the user name:
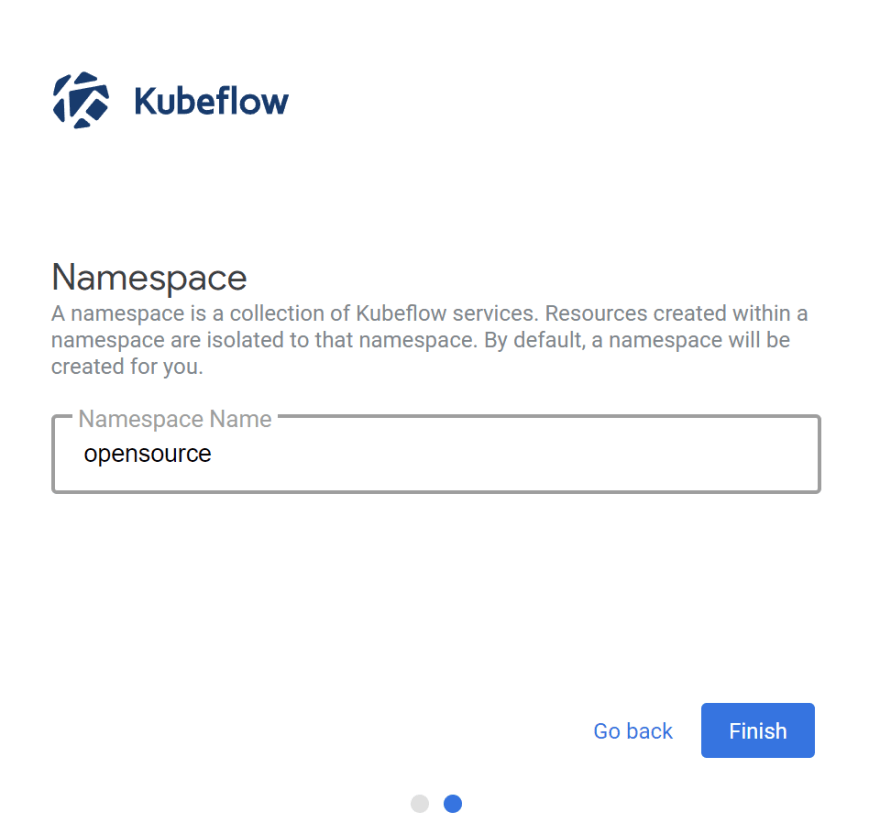
2.2 Creating a Jupyter Notebook
After entering the Demo IDE service, click the application service on the left and click the Kubeflow drop-down menu to enter the Jupyter page.

Click Create Notebook in the upper right corner to go to the Notebook creation page.

After entering the Notebook name, select all configurations in the Configuration area and use the default settings for other configurations.
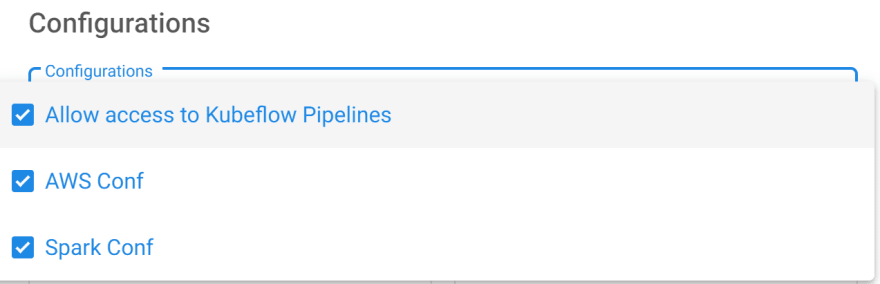
Drag to the bottom and click Launch. After creating the Notebook, click Connect to enter the Jupyter development environment. Many resource files need to be read during the initial loading. Wait one minute.
2.3 Testing Spark Tasks
In Jupyter Notebook, create a Python3 Kernel Notebook:

After entering the Notebook code development screen, enter the following test code:
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.config('spark.master', 'local')\
.getOrCreate()
from datetime import datetime, date
from pyspark.sql import Row
df = spark.createDataFrame([
Row(a=1, b=2., c='string1', d=date(2000, 1, 1), e=datetime(2000, 1, 1, 12, 0)),
Row(a=2, b=3., c='string2', d=date(2000, 2, 1), e=datetime(2000, 1, 2, 12, 0)),
Row(a=4, b=5., c='string3', d=date(2000, 3, 1), e=datetime(2000, 1, 3, 12, 0))
])
df.show()
Then press Shift + Enter to see the result:
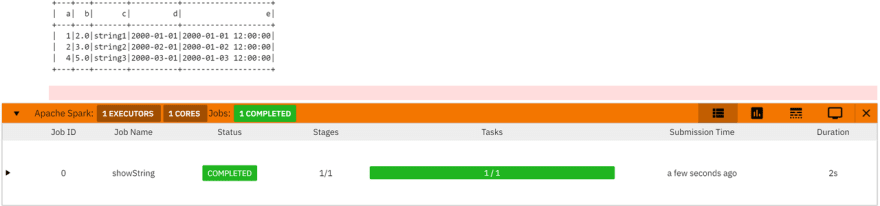
AlphaIDE Jupyter integrates plug-ins such as Python Language Server and Spark Monitor to provide Functions such as Python code completion and Spark task progress display, facilitating development and debugging. You can also install additional plug-ins or themes you need in the Jupyter Extension interface.
2.4 Test MetaSpore task
AlphaIDE is already integrated with MetaSpore. You can test MetaSpore’s introductory tutorial Notebook: https://github.com/meta-soul/MetaSpore/blob/main/tutorials/metaspore-getting-started.ipynb.
The S3 bucket name of the AlphaIDE Demo service is alphaide-demo. YOUR_S3_BUCKET in the tutorial can be replaced with this bucket name and prefixes the path to save data with S3://alphaide-demo/. The feature description schema file required for the test is in the tutorial directory.
2.5 Test the LakeSoul task
LakeSoul Demo link: https://github.com/meta-soul/LakeSoul/wiki/03.-Usage-Doc#1-create-and-write-lakesoultable
The introduction of LakeSoul: https://dev.to/qazmkop/design-concept-of-a-best-opensource-project-about-big-data-and-data-lakehouse-24o2
2.6 Running Movielens Demo
DMetaSoul has provided a MovieLens Demo:https://github.com/meta-soul/MetaSpore/blob/main/demo/movielens/offline/README-CN.md.
This content originally appeared on DEV Community and was authored by qazmkop
qazmkop | Sciencx (2022-06-15T06:29:47+00:00) Usage Guide:Quickly deploy an intelligent data platform with the One-stop AI development and production platform, AlphaIDE. Retrieved from https://www.scien.cx/2022/06/15/usage-guide%ef%bc%9aquickly-deploy-an-intelligent-data-platform-with-the-one-stop-ai-development-and-production-platform-alphaide/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.