
This content originally appeared on DEV Community and was authored by Robin Martijn
There are many things you might want to make backups of. It could be of your code, of assets, or of your entire database.
Whatever it is, backups will make sure you don't lose them. In this blog post, we'll look at making backups of your MySQL database. This technique can also be used to make backups of all kinds of other assets.
What's AWS S3?
We will store our backups in AWS S3. AWS stands for Amazon Web Services, and is Amazon's cloud service. S3 is one of their services, and stands for Simple Storage Service. It uses the same scalable storage systems that Amazon itself uses to run their web shop.
AWS offers lots of different storage classes, all with their own advantages and disadvantages. The most significant difference is mainly in the speed at which you can retrieve objects.
They also all have their own pricing model, which is very favourable. For example, for the first 50 TB per month, you pay only $0.023 per GB. However, the first 5 GB fall under the free tier for the first 12 months, and are therefore completely free.
We are going to use that free storage to store our backups there automatically.
Installing AWS CLI
To write a script to perform backups, it is necessary to install the AWS CLI. This is a program that allows you to interact with AWS in the command line.
Exactly how you install the AWS CLI depends on your operating system. This is explained on the AWS website itself.
For many operating systems, there is an easier way than described there. For example, as a macOS user, you can just use Brew:
brew install awscli
If you have installed AWS CLI, you can test if it works by running the following command:
$ aws --version
aws-cli/2.5.2 Python/3.9.11 Darwin/21.1.0 exe/x86_64 prompt/off
Logging in to AWS CLI
Now that you have the AWS CLI installed, you can use the services of AWS. You will, of course, need an account to do this. If you don't have one yet, you can create one at AWS.
Then you need to create access keys to use the CLI. You do this in the AWS Console, under IAM > Security credentials. Create a new pair of keys and do not close the pop-up. That's where your credentials are. You can't get these back later.
After creating the access keys, you still need to tell that to AWS CLI, so it can access your account. You do that with aws configure:
$ aws configure
AWS Access Key ID [None]: AKIAIOSFODNN7EXAMPLE
AWS Secret Access Key [None]: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
Default region name [None]: us-west-2
Default output format [None]: json
Setting up the S3 bucket
The next step is to create an S3 bucket where we will store the backups. To accomplish this, go to the AWS Console and to S3.
There, you press "Create bucket".
Give the bucket a name and put it in the region where you want it. It is most convenient to put it in your own region, but you may want to store your data somewhere else due to laws or regulations.
You can leave all other settings unchanged.
At the bottom, press "Create bucket" to actually create the S3 bucket.
Open the newly created bucket and then create a new folder, by pressing "Create folder". Name it backups, or anything else you find convenient. This will be the folder where the backups are actually stored.
Once you have opened the folder, you can press "Copy S3 URI" at the top right. We will need this in the next step.
Setting up the backup script
Now that we have AWS fully set up, we have all the data we need to back up our MySQL database.
For this, I use a variant of Yong Mook Kim's script that he published on his blog.
#!/bin/bash
NOW=$(date +"%Y-%m-%d")
NOW_TIME=$(date +"%Y-%m-%d %T %p")
NOW_MONTH=$(date +"%Y-%m")
MYSQL_HOST="localhost"
MYSQL_PORT="3306"
MYSQL_DATABASE="database"
MYSQL_USER="user"
MYSQL_PASSWORD="password"
BACKUP_DIR="/Users/bowero/backup/$NOW_MONTH"
BACKUP_FULL_PATH="$BACKUP_DIR/$MYSQL_DATABASE-$NOW.sql.gz"
AMAZON_S3_BUCKET="s3://cronly-backups/backups/"
AMAZON_S3_PATH="$AMAZON_S3_BUCKET$NOW_MONTH/"
AMAZON_S3_BIN="/usr/local/bin/aws"
#################################################################
mkdir -p ${BACKUP_DIR}
backup_mysql(){
mysqldump -h ${MYSQL_HOST} \
-P ${MYSQL_PORT} \
-u ${MYSQL_USER} \
-p${MYSQL_PASSWORD} ${MYSQL_DATABASE} | gzip > ${BACKUP_FULL_PATH}
}
upload_s3(){
${AMAZON_S3_BIN} s3 cp ${BACKUP_FULL_PATH} ${AMAZON_S3_BUCKET}
}
backup_mysql
upload_s3
Place this script in a convenient location from where you can run it. Then fill in all the variables that need to be changed. These are likely to be:
- MYSQL_DATABASE: The name of your MySQL DB
- MYSQL_USER: The name of your MySQL user
- MYSQL_PASSWORD: Your MySQL password
- BACKUP_DIR: The location where you locally want to store your backups
- AMAZON_S3_BUCKET: The S3 bucket URI (that you got in the previous step)
-
AMAZON_S3_BIN: The location of your AWS CLI binary. If you don't know this, you can also just fill in
aws.
You can save the file with any name you want, such as backups. The file does not need an extension, but if you want to give one, .sh is not unusual.
You still need to make the file executable. You do that with the following command:
$ chmod +x backup.sh
You can run the script to test if it works properly. Just do that with:
./backup.sh
If it works properly, you'll see something like:
upload: 2022-06/cronly-2022-06-17.sql.gz to s3://cronly-backups/backups/cronly-2022-06-17.sql.gz
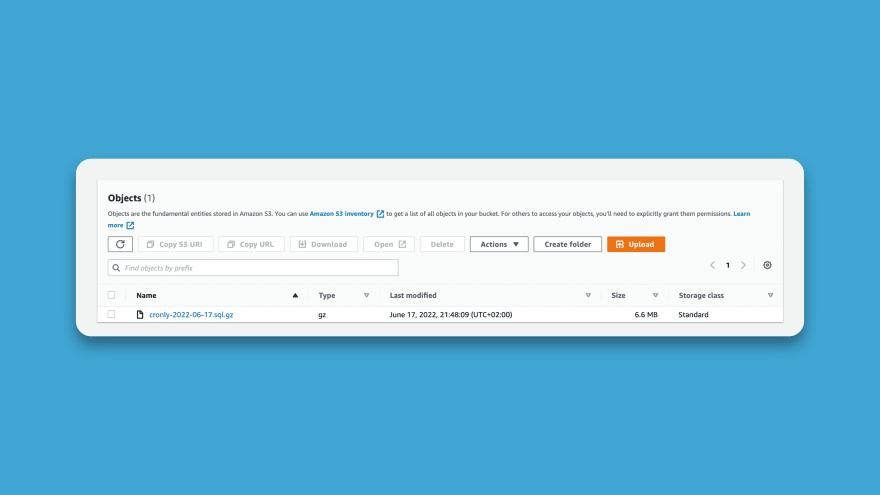
Your backup is then added in S3 if all goes well. You can easily check this with the AWS console, by just going to your S3 bucket and opening the backups folder.
Setting up a cron job
Of course, you don't want to manually run this daily. That's why you need to create a cron job.
You can do this in several ways. One easy way is the built-in way on Unix systems.
A cron job is a task that runs on an interval basis. You can set up a cron job to process payments every hour, process analytics every four hours, send emails every eight hours, or backup every day, just to name a few examples.
The interval and job are expressed through a crontab. That is a line that cron reads to know what to do when. That rule looks like this:
a b c d e /directory/command
Here a b c d e is the interval, and the last part is the command you want to run.
If we intend to make the backups every day at 4 am, we can do it with the following cron tab:
0 4 * * * /home/Users/backup.sh
You can easily study crontabs using a tool like crontab.guru.
To add the crontab to your system, run in your command line:
crontab -e
This opens your default CLI text editor. Here you can add the crontab. Then save the file.
Our backup script now runs automatically every day at 4 am.
Extra: Monitoring the cron job
If it is an important process, it is nice to be sure that the cron job is actually running.
I created a product called Cronly that allows you to do this effortlessly. You just create the cronjob on Cronly.app and add a cURL request to the end of backup.sh. For example:
curl -m 10 https://cronly.app/api/monitors/pulse/39e9c77a-61bc-4b31-a813-e6bb04340529
When your script finishes running, it makes a request to Cronly. This way, Cronly knows that your backups have run on time. So you can sleep easy knowing your backup script is working.

Conclusion
And that was him again! You have now learned how to:
- Install AWS CLI
- Create an S3 bucket and directory
- Automatically create and upload backups to the cloud
- Set up a cron job
- Monitoring your cron jobs
Congratulations! You really do deserve a pat on the back.
This content originally appeared on DEV Community and was authored by Robin Martijn
Robin Martijn | Sciencx (2022-06-17T19:52:46+00:00) Making automatic backups to the cloud for free. Retrieved from https://www.scien.cx/2022/06/17/making-automatic-backups-to-the-cloud-for-free/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.