
This content originally appeared on DEV Community and was authored by Subh Chaturvedi
Would you be interested in knowing which politician has made the most headlines? Do you want to see which celebrity has best held the attention of journalists over the years? Are you intrigued about the difference in crime news grouped by states?
If your answer is yes to any of those questions, then we share the same curiosity.
Looking at archives maintained by Newspapers, I wondered who would go through over twenty-five thousand pages of news headlines sorted by date and make any heads or tails of the big picture around it. How could someone analyse trends or gains insights from an almost endless list of headlines dating decades ago by just reading them on a website.
But I could not stop myself from doing something about this problem I had at hand. I needed to devise a way to reliably, efficiently and easily comb through the data these archives made available. To accomplish this goal, I set out with this project.
In this writeup I will go over how I created a fundamental tool or method for anyone to easily analyse, understand and research the Indian Headlines data of the past 25 years.
PART 1: The Data
To start with my project, I thought I could easily find a dataset which contained all the data I needed, properly formatted in a csv file and would only leave me to write scripts to analyse that data. If only life was that easy.
Unfortunately, I could not find any dataset suitable to my needs and thus had to dedicate a significant portion of work-time of this project on procuring and cleaning the data myself.
Ideally, we would need a data file with an exhaustive, credible and unbiased collection of headlines from a large enough timeline.
Sourcing the Data
In the absence of pre-prepared datasets, I had to find a credible source to collect headlines data stretching for a significant duration of time. So what better place than the websites of major journalistic organisations like The Times, The Hindu, Deccan Herald or the Indian Express.
But these organisations do not publicly provide an easy way to procure the data we need. So the most obvious way was to read the data off their own websites. Fortunately almost all of these organisations provide a public archive of their journalism which is better option than sitting and recording all the headlines myself for the next decade.
But the archives that these organisations provide do not allow you to easily export the data they make available themselves in a format which can be utilized by us. So the best way to obtain the data we need is to utilize Web Scraping.
Web Scraping
Web Scraping is essentially the process of automatically extract the data we need from websites by utilizing tools which can parse and read data from the source code of these websites (Mostly HTML).
For this project, I use the following python modules/packages which are extremely suited for the task:
- BeautifulSoup: A python library that makes it easy to scrape content from web pages. It sits atop an HTML or XML parser, providing Pythonic idioms for iterating, searching, and modifying the parse tree.
- Requests: The requests module allows you to send HTTP requests using Python. The HTTP request returns a Response Object with all the response data(the web page code).
❗ I have not covered the Ethics of using Web Scraping Techniques in the scope of this project. Please do your research before putting into practice any code/instructions present here. ❗
 |
|---|
| A screenshot of the Indian Express Archives page I scraped for the purpose of this project. |
I decided to use the Indian Express News Archives because it generates its content statically and the URL to change pages is easily iterable through code. Certain other public archives generate their web pages dynamically through JavaScript, while some others make it very difficult to traverse the content for the scraping script.
Now lets look at the code for the scraping script I wrote:
Code Implementation
This is the basic code needed to obtain the source HTML code from the Indian Express pages. The pageNumber is the variable iterated through a for loop in the range of the pages we need to scrape.
url = "https://indianexpress.com/section/news-archive/page/"+str(pageNumber)+"/"
page_request = requests.get(url)
data = page_request.content
soup = BeautifulSoup(data,"html.parser")
The final obtained source code is stored in the soup variable.
Now, the actual headlines in the code are actually stored inside <h2> tags with the class name as title. So all we need to do is use the BeautifulSoup library and filter the obtained code to read off the <a> tags from the filtered title headline tags. Then we further use get_text function to get the headline string.
for divtag in soup.find_all('h2', {'class': 'title'}):
for atag in divtag.find_all('a'):
#HEADLINES
hl=atag.get_text()
print("Headline: ",hl) # This prints the scraped headline.
It is much more convenient for us to store the scraped data in a text file, rather than print it on the terminal. A solution to write all of this data is easily implemented with the following code.
file1 = open(r"<ABSOLUTE PATH>\headlines.txt","a",encoding="utf-8")
file1.write(hl.lower()) # stored in lower for easier analysis
file1.write("\n")
file1.close()
When this code is properly looped, it can be used to scrape and obtain the headline data from the complete archive rather than just one page. In this case the pages extend to Page 25073 and thus a the above code can simply be put into a loop iterating over all the pages.
When I ran the final script for the first time, I realised that scraping over 25 thousand pages with this script would take me over multiple days running my the script 24x7, while any interruption to the process could erase all the progress.
Thus for the sake of accessibility, ease-of-use and practicality of the process I implemented the code in a fashion where it could be paused at any moment and would save and remember its progress. While this addressed the problem of interruptions and being able to pause the script execution, it was still projected to take me a very long time to just be able to scrape this data. To decrease the time it would take for the complete scraping of the archive, I divided the 25 thousand pages into 20 equal groups. This allowed my workstation to simultaneously run twenty instances of the same script running parallel workloads and reducing the time needed over twentyfold.
PART 2: The Framework
All of the above described process finally netted me a list of over 6.5 lac headlines in a text file in the following format:
covid-19: up govt extends closure of all schools, colleges till january 23
renotify 27% seats reserved for obcs in local body polls, sc tells maharashtra, sec
talks fail over action against karnal ex-sdm, siege continues
jagan promotes andhra as favoured investment destination, defends scrapping ppas
murder-accused husband of mla visits house, bjp slams congress
over 25,000 cops, cctvs, drones to secure gujarat rath yatra on july 4
in bhutan, teachers, medical staff will now be highest paid civil servants
‘cyclone man’ mrutyunjay mohapatra appointed imd chief
pakistan hotel attack: four killed as armed militants storm 5-star hotel in gwadar port city, says police
indian man convicted in dubai for hacking 15 client websites
[continued]
These headlines encompass a time period of 25 years (Thus the title) from 1997-2022.
Keyword Analysis
It is obviously in a much more accessible format now, but how do we run any kind of analysis on this data file?
The simple answer is Keyword Analysis. In the context of this project, it is the method of classifying, categorizing, labelling, and analysing these headlines by the presence (or lack of) certain words in them.
For example, if a certain headline has the word "Mahatma Gandhi", "Bapu", or "Gandhi Ji", it is very likely to be a headline reporting something about Gandhi. We will be using this form of deduction in the scope of this project to analyse the dataset that we have formed.
Therefore to exercise this idea, we need to implement certain tools to be on our disposal. In the scope of this project, these tools are basically methods/functions which find(/aggregate) the headlines depending on the presence of keywords. Multiple different need based cases can be imagined, but overall they can all be divided into the following fundamental implementations:
- Finding the headlines where any of the keyword from a group is found.
- Finding the headlines where all of the keywords from a group are found.
- Finding the headlines where any of the keywords from each of the multiple groups are found.
Any other needed use-case can be made to fit/work with these fundamental functions. For example, if we need to find the headlines where all of the keywords from each of the multiple groups in found, we can just merge the groups and use the second function for them. On the other hand if we need to find the headlines where the keywords do not occur, we can just eliminate the headlines where those keywords do occur using the first function.
Code Implementation
The above mentioned three fundamental functions are implemented as follows:
-
Finding the headlines where any of the keyword from a group is found.
Here, the code iterates through all the headlines in the
headLinesListobject and if any of the keyword provided in the list is found then the counter maintained is bumped and finally returned.
# FUNCTION TO COUNT HEADLINES WHERE ANY OF THE WORD/S OCCURS
# - wordsToSearch is a list of the form ["word1","word2","word3",...]
def countOccurancesAny(wordsToSearch):
count = 0
for headline in headLinesList:
for eachWord in wordsToSearch:
if headline.find(eachWord.lower()) != -1:
count += 1
break
return count
- Finding the headlines where all of the keywords from a group are found. The premise here is almost the same as the 1st function, but instead of searching for one word and then bumping the counter, this function has to wait and make sure all the elements of the list are found in the headline. For optimisation purposes, the loop skips cycles if any of the element is not found.
# FUNCTION TO COUNT HEADLINES WHERE ALL OF THE WORD/S OCCURS
# - wordsToSearch is a list of the form ["word1","word2","word3",...]
def countOccurancesAll(wordsToSearch):
mainCount = 0
wordCount = 0
totalWords = len(wordsToSearch)
for headline in headLinesList:
wordCount = 0
for eachWord in wordsToSearch:
if headline.find(eachWord.lower()) == -1:
break
else:
wordCount += 1
if wordCount == totalWords:
mainCount += 1
return mainCount
- Finding the headlines where any of the keywords from each of the multiple groups are found. This function basically nests the first function one more time, finding out if a keyword from the groups passed off as 2D lists are present. There is also optimization similar to function 2 present here.
# FUNCTION TO COUNT HEADLINES WHERE ANY OF THE WORD/S FROM MULTIPLE GROUPS OCCURS
# - wordsToSearch is a list of lists, each of the form ["word1","word2","word3",...]
def countOccurancesGroupedAny(wordsToSearch):
count = 0
countMain = 0
for headline in headLinesList:
countMain = 0
for eachGroup in wordsToSearch:
optimiseCheck1 = 0
for eachWord in eachGroup:
if headline.find(eachWord.lower()) != -1:
optimiseCheck1 = 1
countMain += 1
break
if optimiseCheck1 == 0:
break
if countMain == len(wordsToSearch):
count += 1
return count
Well, now that we have looked at the tools and platforms I developed for this project, lets look at how these can be used to analyse and interpret data.
PART 3: The Analysis
An analysis was not so much the focus of this project than actually developing a framework allowing for easy analysis of this dataset. But I have still done some analysis and visualizations to demonstrate the usability of the above described code.
I will be using the word "Popular" to denote how much the entity has been in news. It has unreliable correlation with actual popularity.
Most Popular Political Party
First, we create lists with the keywords that will be used to identify appropriate headlines. These lists contain keywords that I think are enough to identify if a headline is aimed at these parties.Then the data is obtained and arranged as a pandas dataframe and then printed sorted by headlines count.
bjp = ["bjp","Bharatiya Janata Party"]
inc = ["INC","Congress"]
aap = ["AAP","Aam Aadmi Party"]
cpi = ["CPI","Communist Party of India"]
bsp = ["BSP","Bahujan Samaj Party"]
dmk = ["DMK","Dravida Munnetra Kazhagam"]
shivsena = ["sena","shiv sena"]
data = {'Party': ['BJP', 'INC', 'AAP', 'CPI', 'BSP', 'DMK', 'SHIV SENA'],
'Reported': [hd.countOccurancesAny(bjp),hd.countOccurancesAny(inc),hd.countOccurancesAny(aap),hd.countOccurancesAny(cpi),hd.countOccurancesAny(bsp),hd.countOccurancesAny(dmk),hd.countOccurancesAny(shivsena)]}
df = pd.DataFrame(data)
print(df.sort_values("Reported",ascending=False))
The result is visualised in the following graph:

As is clearly discernible, INC is the most reported on by part followed very closely by BJP.
Most Reported Politician
The code to crunch the numbers is very similar to the one we saw above:
modi = ["Modi","Narendra Modi","Narendra Damodardas Modi"]
amitshah = ["amit shah","shah"]
rajnath = ["rajnath singh"]
jaishankar = ["jaishankar"]
mamata = ["mamata","didi"]
kejriwal = ["aravind","kejriwal"]
yogi = ["adityanath","yogi","ajay bisht"]
rahul = ["rahul"]
stalin = ["stalin"]
akhilesh = ["akhilesh"]
owaisi = ["owaisi"]
gehlot = ["gehlot"]
biswa = ["himanta biswa","biswa"]
scindia = ["scindia"]
sibal = ["sibal"]
manmohan = ["manmohan singh"]
mayavati = ["mayavati"]
mulayam = ["mulayam"]
naveen = ["patnaik"]
nitish = ["nitish"]
sonia = ["sonia"]
uddhav = ["uddhav"]
data = {
'Political' : ['Narendra Modi','Amit Shah','Rajnath Singh','S Jaishankar',
'Mamata Bannerjee','Aravind Kejrival','Yogi Adityanath','Rahul Gandhi','MK Stalin',
'Akhilesh Yadav','Asaduddin Owaisi','Ashok Gehlot','Himanta Biswa Sarma', 'Jotiraditya Scindia',
'Kapil Sibal','Manmohan Singh','Mayavati','Mulayam Singh Yadav','Naveen Patnaik','Nitish Kumar','Sonia Gandhi','Uddhav Thackeray'],
'Reported' : [hd.countOccurancesAny(modi),hd.countOccurancesAny(amitshah),hd.countOccurancesAny(rajnath),hd.countOccurancesAny(jaishankar),
hd.countOccurancesAny(mamata),
hd.countOccurancesAny(kejriwal),hd.countOccurancesAny(yogi),hd.countOccurancesAny(rahul),hd.countOccurancesAny(stalin),
hd.countOccurancesAny(akhilesh),hd.countOccurancesAny(owaisi),hd.countOccurancesAny(gehlot),hd.countOccurancesAny(biswa),hd.countOccurancesAny(scindia),
hd.countOccurancesAny(sibal),hd.countOccurancesAny(manmohan),hd.countOccurancesAny(mayavati),hd.countOccurancesAny(mulayam),hd.countOccurancesAny(naveen),
hd.countOccurancesAny(nitish),hd.countOccurancesAny(sonia),hd.countOccurancesAny(uddhav)]
}
df = pd.DataFrame(data)
print(df.sort_values("Reported",ascending=False))
For the visualization aspect of this I thought of using a Circle Packing Graph. I explored my options with external visualization options but none of them offered what I was looking for.
After a lot of research I stumbled on a way to generate what I wanted through python code and the Circlify module.
So, I wrote the code to generate the graph I was looking for. But it turned out to not be as polished or presentable as I wanted it to be. But I am still including the code snippet I wrote:
# compute circle positions:
circles = circlify.circlify(
df['Reported'].tolist(),
show_enclosure=False,
target_enclosure=circlify.Circle(x=0, y=0, r=1)
)
# Create just a figure and only one subplot
fig, ax = plt.subplots(figsize=(10,10))
# Remove axes
ax.axis('off')
# Find axis boundaries
lim = max(
max(
abs(circle.x) + circle.r,
abs(circle.y) + circle.r,
)
for circle in circles
)
plt.xlim(-lim, lim)
plt.ylim(-lim, lim)
# list of labels
labels = df['Reported']
# print circles
for circle, label in zip(circles, labels):
x, y, r = circle
ax.add_patch(plt.Circle((x, y), r, alpha=0.2, linewidth=2))
plt.annotate(
label,
(x,y ) ,
va='center',
ha='center'
)
plt.show()
Instead of the Circle Packing Graph, I decided to create the following visualization which presents the data generated by my above code.

Crime Statistics By States
Before diving right into the the crime news statistics, lets first write individual code for calculating State statistics, and crime statistics.
# Crime Statistics
robbery = ['robbery','thief','thieves','chori']
sexual = ['rape','rapist','sexual assault']
dowry = ['dowry','dahej']
drugs = ['drug']
traffick = ['traffick']
cyber = ['hack','cyber crime','phish']
murder = ['murder']
data = {
'Crime':['Robbery','Sexual','Dowry',"Drugs",'Trafficking','Cyber','Murder'],
'Reported':[hd.countOccurancesAny(robbery),hd.countOccurancesAny(sexual),hd.countOccurancesAny(dowry),hd.countOccurancesAny(drugs)
,hd.countOccurancesAny(traffick),hd.countOccurancesAny(cyber),hd.countOccurancesAny(murder)]
}
df = pd.DataFrame(data)
print(df.sort_values("Reported",ascending=False))
# Crime Reported
# 6 Murder 3271
# 1 Sexual 2533
# 5 Cyber 1538
# 3 Drugs 1403
# 0 Robbery 384
# 2 Dowry 217
# 4 Trafficking 170
# States Stats
UttarPradesh = ['Uttar Pradesh', ' UP ',"Agra" ,"Aligarh" ,"Ambedkar Nagar" ,"Amethi" ,"Amroha" ,"Auraiya" ,"Ayodhya" ,"Azamgarh" ,"Baghpat" ,"Bahraich" ,"Ballia" ,"Balrampur" ,"Barabanki" ,"Bareilly" ,"Bhadohi" ,"Bijnor" ,"Budaun" ,"Bulandshahr" ,"Chandauli" ,"Chitrakoot" ,"Deoria" ,"Etah" ,"Etawah" ,"Farrukhabad" ,"Fatehpur" ,"Firozabad" ,"Gautam Buddha Nagar" ,"Ghaziabad" ,"Ghazipur" ,"Gorakhpur" ,"Hamirpur" ,"Hardoi" ,"Hathras" ,"Jalaun" ,"Jaunpur" ,"Jhansi" ,"Kannauj" ,"Kanpur Dehat" ,"Kanpur Nagar" ,"Kasganj" ,"Kaushambi" ,"Kushinagar" ,"Lalitpur" ,"Lucknow" ,"Maharajganj" ,"Mahoba" ,"Mainpuri" ,"Mathura" ,"Meerut" ,"Mirzapur" ,"Moradabad" ,"Muzaffarnagar" ,"Pilibhit" ,"Pratapgarh" ,"Prayagraj" ,"Raebareli" ,"Rampur" ,"Saharanpur" ,"Sambhal" ,"Sant Kabir Nagar" ,"Shahjahanpur" ,"Shamli" ,"Shravasti" ,"Siddharthnagar" ,"Sitapur" ,"Sonbhadra" ,"Sultanpur" ,"Unnao" ,"Varanasi" ]
AndamanNicobar = ["Andaman","Nicobar"]
AndhraPradesh = ["Andhra","Anantapur" ,"Chittoor" ,"East Godavari" ,"Alluri Sitarama Raju" ,"Anakapalli" ,"Annamaya" ,"Bapatla" ,"Eluru" ,"Guntur" ,"Kadapa" ,"Kakinada" ,"Konaseema" ,"Krishna" ,"Kurnool" ,"Manyam" ,"N T Rama Rao" ,"Nandyal" ,"Nellore" ,"Palnadu" ,"Prakasam" ,"Sri Balaji" ,"Sri Satya Sai" ,"Srikakulam" ,"Visakhapatnam" ,"Vizianagaram" ,"West Godavari"]
ArunachalPradesh = ['Arunachal',"Anjaw" ,"Changlang" ,"Dibang Valley" ,"East Kameng" ,"East Siang" ,"Kamle" ,"Kra Daadi" ,"Kurung Kumey" ,"Lepa Rada" ,"Lohit" ,"Longding" ,"Lower Dibang Valley" ,"Lower Siang" ,"Lower Subansiri" ,"Namsai" ,"Pakke Kessang" ,"Papum Pare" ,"Shi Yomi" ,"Siang" ,"Tawang" ,"Tirap" ,"Upper Siang" ,"Upper Subansiri" ,"West Kameng" ,"West Siang" ]
Assam = ['assam',"Bajali" ,"Baksa" ,"Barpeta" ,"Biswanath" ,"Bongaigaon" ,"Cachar" ,"Charaideo" ,"Chirang" ,"Darrang" ,"Dhemaji" ,"Dhubri" ,"Dibrugarh" ,"Dima Hasao" ,"Goalpara" ,"Golaghat" ,"Hailakandi" ,"Hojai" ,"Jorhat" ,"Kamrup" ,"Kamrup Metropolitan" ,"Karbi Anglong" ,"Karimganj" ,"Kokrajhar" ,"Lakhimpur" ,"Majuli" ,"Morigaon" ,"Nagaon" ,"Nalbari" ,"Sivasagar" ,"Sonitpur" ,"South Salmara-Mankachar" ,"Tinsukia" ,"Udalguri" ,"West Karbi Anglong" ]
Bihar = ['bihar', "Araria" ,"Arwal" ,"Aurangabad" ,"Banka" ,"Begusarai" ,"Bhagalpur" ,"Bhojpur" ,"Buxar" ,"Darbhanga" ,"East Champaran" ,"Gaya" ,"Gopalganj" ,"Jamui" ,"Jehanabad" ,"Kaimur" ,"Katihar" ,"Khagaria" ,"Kishanganj" ,"Lakhisarai" ,"Madhepura" ,"Madhubani" ,"Munger" ,"Muzaffarpur" ,"Nalanda" ,"Nawada" ,"Patna" ,"Purnia" ,"Rohtas" ,"Saharsa" ,"Samastipur" ,"Saran" ,"Sheikhpura" ,"Sheohar" ,"Sitamarhi" ,"Siwan" ,"Supaul" ,"Vaishali" ,"West Champaran"]
Chandigarh = ['Chandigarh']
Chhattisgarh = ['Chhattisgarh', "Balod" ,"Baloda Bazar" ,"Balrampur" ,"Bastar" ,"Bemetara" ,"Bijapur" ,"Bilaspur" ,"Dantewada" ,"Dhamtari" ,"Durg" ,"Gariaband" ,"Gaurela Pendra Marwahi" ,"Janjgir Champa" ,"Jashpur" ,"Kabirdham" ,"Kanker" ,"Kondagaon" ,"Korba" ,"Koriya" ,"Mahasamund" ,"Manendragarh" ,"Mohla Manpur" ,"Mungeli" ,"Narayanpur" ,"Raigarh" ,"Raipur" ,"Rajnandgaon" ,"Sakti" ,"Sarangarh Bilaigarh" ,"Sukma" ,"Surajpur"]
Dadra = ['Dadra', 'Daman', 'Diu']
Delhi = ['Delhi']
Goa = ['Goa']
Gujrat = ['Gujrat', "Ahmedabad" ,"Amreli" ,"Anand" ,"Aravalli" ,"Banaskantha" ,"Bharuch" ,"Bhavnagar" ,"Botad" ,"Chhota Udaipur" ,"Dahod" ,"Dang" ,"Devbhoomi Dwarka" ,"Gandhinagar" ,"Gir Somnath" ,"Jamnagar" ,"Junagadh" ,"Kheda" ,"Kutch" ,"Mahisagar" ,"Mehsana" ,"Morbi" ,"Narmada" ,"Navsari" ,"Panchmahal" ,"Patan" ,"Porbandar" ,"Rajkot" ,"Sabarkantha" ,"Surat" ,"Surendranagar" ,"Tapi" ,"Vadodara" ,"Valsad"]
Haryana = ['Haryana', "Ambala" ,"Bhiwani" ,"Charkhi Dadri" ,"Faridabad" ,"Fatehabad" ,"Gurugram" ,"Hisar" ,"Jhajjar" ,"Jind" ,"Kaithal" ,"Karnal" ,"Kurukshetra" ,"Mahendragarh" ,"Mewat" ,"Palwal" ,"Panchkula" ,"Panipat" ,"Rewari" ,"Rohtak" ,"Sirsa" ,"Sonipat" ,"Yamunanagar"]
HimachalPradesh = ['Himachal',"Bilaspur" ,"Chamba" ,"Hamirpur" ,"Kangra" ,"Kinnaur" ,"Kullu" ,"Lahaul Spiti" ,"Mandi" ,"Shimla" ,"Sirmaur" ,"Solan" ,"Una" ]
JammuKashmir = ["Jammu", "Kashmir", "J&K", "JK", "Anantnag" ,"Bandipora" ,"Baramulla" ,"Budgam" ,"Doda" ,"Ganderbal" ,"Jammu" ,"Kathua" ,"Kishtwar" ,"Kulgam" ,"Kupwara" ,"Poonch" ,"Pulwama" ,"Rajouri" ,"Ramban" ,"Reasi" ,"Samba" ,"Shopian" ,"Srinagar" ,"Udhampur"]
Jharkand = ["Jharkand", "Bokaro" ,"Chatra" ,"Deoghar" ,"Dhanbad" ,"Dumka" ,"East Singhbhum" ,"Garhwa" ,"Giridih" ,"Godda" ,"Gumla" ,"Hazaribagh" ,"Jamtara" ,"Khunti" ,"Koderma" ,"Latehar" ,"Lohardaga" ,"Pakur" ,"Palamu" ,"Ramgarh" ,"Ranchi" ,"Sahebganj" ,"Seraikela Kharsawan" ,"Simdega" ,"West Singhbhum"]
Karnataka = ['Karnataka',"Bagalkot" ,"Bangalore Rural" ,"Bangalore Urban" ,"Belgaum" ,"Bellary" ,"Bidar" ,"Chamarajanagar" ,"Chikkaballapur" ,"Chikkamagaluru" ,"Chitradurga" ,"Dakshina Kannada" ,"Davanagere" ,"Dharwad" ,"Gadag" ,"Gulbarga" ,"Hassan" ,"Haveri" ,"Kodagu" ,"Kolar" ,"Koppal" ,"Mandya" ,"Mysore" ,"Raichur" ,"Ramanagara" ,"Shimoga" ,"Tumkur" ,"Udupi" ,"Uttara Kannada" ,"Vijayanagara" ,"Vijayapura" ,"Yadgir"]
Kerala = ['Kerala', "Alappuzha" ,"Ernakulam" ,"Idukki" ,"Kannur" ,"Kasaragod" ,"Kollam" ,"Kottayam" ,"Kozhikode" ,"Malappuram" ,"Palakkad" ,"Pathanamthitta" ,"Thiruvananthapuram" ,"Thrissur" ,"Wayanad"]
Ladakh = ['Ladakh','leh','kargil']
Lakshadweep = ['Lakshadweep']
MadhyaPradesh = ["Madhya", "Agar Malwa" ,"Alirajpur" ,"Anuppur" ,"Ashoknagar" ,"Balaghat" ,"Barwani" ,"Betul" ,"Bhind" ,"Bhopal" ,"Burhanpur" ,"Chachaura" ,"Chhatarpur" ,"Chhindwara" ,"Damoh" ,"Datia" ,"Dewas" ,"Dhar" ,"Dindori" ,"Guna" ,"Gwalior" ,"Harda" ,"Hoshangabad" ,"Indore" ,"Jabalpur" ,"Jhabua" ,"Katni" ,"Khandwa" ,"Khargone" ,"Maihar" ,"Mandla" ,"Mandsaur" ,"Morena" ,"Nagda" ,"Narsinghpur" ,"Neemuch" ,"Niwari" ,"Panna" ,"Raisen" ,"Rajgarh" ,"Ratlam" ,"Rewa" ,"Sagar" ,"Satna" ,"Sehore" ,"Seoni" ,"Shahdol" ,"Shajapur" ,"Sheopur" ,"Shivpuri" ,"Sidhi" ,"Singrauli" ,"Tikamgarh" ,"Ujjain" ,"Umaria" ,"Vidisha"]
Maharashtra = ["Maharashtra", "Bombay", "Ahmednagar" ,"Akola" ,"Amravati" ,"Aurangabad" ,"Beed" ,"Bhandara" ,"Buldhana" ,"Chandrapur" ,"Dhule" ,"Gadchiroli" ,"Gondia" ,"Hingoli" ,"Jalgaon" ,"Jalna" ,"Kolhapur" ,"Latur" ,"Mumbai" ,"Mumbai Suburban" ,"Nagpur" ,"Nanded" ,"Nandurbar" ,"Nashik" ,"Osmanabad" ,"Palghar" ,"Parbhani" ,"Pune" ,"Raigad" ,"Ratnagiri" ,"Sangli" ,"Satara" ,"Sindhudurg" ,"Solapur" ,"Thane" ,"Wardha" ,"Washim" ,"Yavatmal"]
Manipur = ['Manipur', "Bishnupur" ,"Chandel" ,"Churachandpur" ,"Imphal East" ,"Imphal West" ,"Jiribam" ,"Kakching" ,"Kamjong" ,"Kangpokpi" ,"Noney" ,"Pherzawl" ,"Senapati" ,"Tamenglong" ,"Tengnoupal" ,"Thoubal" ,"Ukhrul"]
Meghalaya = ['Megh', "East Garo Hills" ,"East Jaintia Hills" ,"East Khasi Hills" ,"Mairang" ,"North Garo Hills" ,"Ri Bhoi" ,"South Garo Hills" ,"South West Garo Hills" ,"South West Khasi Hills" ,"West Garo Hills" ,"West Jaintia Hills" ,"West Khasi Hills"]
Mizoram = ['Mizoram', "Aizawl" ,"Champhai" ,"Hnahthial" ,"Khawzawl" ,"Kolasib" ,"Lawngtlai" ,"Lunglei" ,"Mamit" ,"Saiha" ,"Saitual" ,"Serchhip" ]
Nagaland = ['Nagaland', "Chumukedima" ,"Dimapur" ,"Kiphire" ,"Kohima" ,"Longleng" ,"Mokokchung" ,"Niuland" ,"Noklak" ,"Peren" ,"Phek" ,"Tseminyu" ,"Tuensang" ,"Wokha" ,"Zunheboto"]
Odisha = ['Odisha', "Angul" ,"Balangir" ,"Balasore" ,"Bargarh" ,"Bhadrak" ,"Boudh" ,"Cuttack" ,"Debagarh" ,"Dhenkanal" ,"Gajapati" ,"Ganjam" ,"Jagatsinghpur" ,"Jajpur" ,"Jharsuguda" ,"Kalahandi" ,"Kandhamal" ,"Kendrapara" ,"Kendujhar" ,"Khordha" ,"Koraput" ,"Malkangiri" ,"Mayurbhanj" ,"Nabarangpur" ,"Nayagarh" ,"Nuapada" ,"Puri" ,"Rayagada" ,"Sambalpur" ,"Subarnapur" ,"Sundergarh"]
Puducherry = ['Puducherry', "Karaikal" ,"Mahe" ,"Puducherry" ,"Yanam" ]
Punjab = ['Punjab', "Amritsar" ,"Barnala" ,"Bathinda" ,"Faridkot" ,"Fatehgarh Sahib" ,"Fazilka" ,"Firozpur" ,"Gurdaspur" ,"Hoshiarpur" ,"Jalandhar" ,"Kapurthala" ,"Ludhiana" ,"Malerkotla" ,"Mansa" ,"Moga" ,"Mohali" ,"Muktsar" ,"Pathankot" ,"Patiala" ,"Rupnagar" ,"Sangrur" ,"Shaheed Bhagat Singh Nagar" ,"Tarn Taran"]
Rajasthan = ['Rajasthan', "Ajmer" ,"Alwar" ,"Banswara" ,"Baran" ,"Barmer" ,"Bharatpur" ,"Bhilwara" ,"Bikaner" ,"Bundi" ,"Chittorgarh" ,"Churu" ,"Dausa" ,"Dholpur" ,"Dungarpur" ,"Hanumangarh" ,"Jaipur" ,"Jaisalmer" ,"Jalore" ,"Jhalawar" ,"Jhunjhunu" ,"Jodhpur" ,"Karauli" ,"Kota" ,"Nagaur" ,"Pali" ,"Pratapgarh" ,"Rajsamand" ,"Sawai Madhopur" ,"Sikar" ,"Sirohi" ,"Sri Ganganagar" ,"Tonk" ,"Udaipur"]
Sikkim = ['Sikkim','Soreng','Pakyong']
TamilNadu = ["Tamil Nadu", "Ariyalur" ,"Chengalpattu" ,"Chennai" ,"Coimbatore" ,"Cuddalore" ,"Dharmapuri" ,"Dindigul" ,"Erode" ,"Kallakurichi" ,"Kanchipuram" ,"Kanyakumari" ,"Karur" ,"Krishnagiri" ,"Madurai" ,"Mayiladuthurai" ,"Nagapattinam" ,"Namakkal" ,"Nilgiris" ,"Perambalur" ,"Pudukkottai" ,"Ramanathapuram" ,"Ranipet" ,"Salem" ,"Sivaganga" ,"Tenkasi" ,"Thanjavur" ,"Theni" ,"Thoothukudi" ,"Tiruchirappalli" ,"Tirunelveli" ,"Tirupattur" ,"Tiruppur" ,"Tiruvallur" ,"Tiruvannamalai" ,"Tiruvarur" ,"Vellore" ,"Viluppuram" ,"Virudhunagar"]
Telangana = ['Telangana',"Adilabad" ,"Bhadradri Kothagudem" ,"Hanamkonda" ,"Hyderabad" ,"Jagtial" ,"Jangaon" ,"Jayashankar" ,"Jogulamba" ,"Kamareddy" ,"Karimnagar" ,"Khammam" ,"Komaram Bheem" ,"Mahabubabad" ,"Mahbubnagar" ,"Mancherial" ,"Medak" ,"Medchal" ,"Mulugu" ,"Nagarkurnool" ,"Nalgonda" ,"Narayanpet" ,"Nirmal" ,"Nizamabad" ,"Peddapalli" ,"Rajanna Sircilla" ,"Ranga Reddy" ,"Sangareddy" ,"Siddipet" ,"Suryapet" ,"Vikarabad" ,"Wanaparthy" ,"Warangal" ,"Yadadri Bhuvanagiri"]
Tripura = ['Tripura',"Dhalai" ,"Gomati" ,"Khowai" ,"North Tripura" ,"Sepahijala" ,"South Tripura" ,"Unakoti" ,"West Tripura" ]
Uttarakhand = ['Uttarakhand',"Almora" ,"Bageshwar" ,"Chamoli" ,"Champawat" ,"Dehradun" ,"Haridwar" ,"Nainital" ,"Pauri" ,"Pithoragarh" ,"Rudraprayag" ,"Tehri" ,"Udham Singh Nagar" ,"Uttarkashi"]
WestBengal = ['Bengal', "Alipurduar" ,"Bankura" ,"Birbhum" ,"Cooch Behar" ,"Dakshin Dinajpur" ,"Darjeeling" ,"Hooghly" ,"Howrah" ,"Jalpaiguri" ,"Jhargram" ,"Kalimpong" ,"Kolkata" ,"Malda" ,"Murshidabad" ,"Nadia" ,"North 24 Parganas" ,"Paschim Bardhaman" ,"Paschim Medinipur" ,"Purba Bardhaman" ,"Purba Medinipur" ,"Purulia" ,"South 24 Parganas" ,"Uttar Dinajpur"]
data ={
"States":['Andaman Nicobar', 'Andhra Pradesh', 'Arunachal Pradesh',
'Assam', 'Bihar', 'Chandigarh',
'Chhattisgarh', 'Dadra Nagar',
'Delhi', 'Goa', 'Gujarat', 'Haryana', 'Himachal Pradesh',
'Jammu Kashmir', 'Jharkhand', 'Karnataka', 'Kerala',
'Ladakh', 'Lakshadweep', 'Madhya Pradesh', 'Maharashtra',
'Manipur', 'Meghalaya', 'Mizoram', 'Nagaland', 'Odisha',
'Puducherry', 'Punjab', 'Rajasthan', 'Sikkim', 'Tamil Nadu'
, 'Telangana', 'Tripura', 'Uttar Pradesh',
'Uttarakhand', 'West Bengal'],
"Reported":[hd.countOccurancesAny(AndamanNicobar),hd.countOccurancesAny(AndhraPradesh),hd.countOccurancesAny(ArunachalPradesh),
hd.countOccurancesAny(Assam),hd.countOccurancesAny(Bihar),hd.countOccurancesAny(Chandigarh),
hd.countOccurancesAny(Chhattisgarh),hd.countOccurancesAny(Dadra),hd.countOccurancesAny(Delhi),
hd.countOccurancesAny(Goa),hd.countOccurancesAny(Gujrat),hd.countOccurancesAny(Haryana),
hd.countOccurancesAny(HimachalPradesh),hd.countOccurancesAny(JammuKashmir),hd.countOccurancesAny(Jharkand),
hd.countOccurancesAny(Karnataka),hd.countOccurancesAny(Kerala),hd.countOccurancesAny(Ladakh),
hd.countOccurancesAny(Lakshadweep),hd.countOccurancesAny(MadhyaPradesh),hd.countOccurancesAny(Maharashtra),
hd.countOccurancesAny(Manipur),hd.countOccurancesAny(Meghalaya),
hd.countOccurancesAny(Mizoram),hd.countOccurancesAny(Nagaland),hd.countOccurancesAny(Odisha),
hd.countOccurancesAny(Puducherry),hd.countOccurancesAny(Punjab),hd.countOccurancesAny(Rajasthan),
hd.countOccurancesAny(Sikkim),hd.countOccurancesAny(TamilNadu),hd.countOccurancesAny(Telangana),
hd.countOccurancesAny(Tripura),hd.countOccurancesAny(UttarPradesh),hd.countOccurancesAny(Uttarakhand),hd.countOccurancesAny(WestBengal)]
}
df = pd.DataFrame(data)
print(df.sort_values("Reported",ascending=False))
print(df)
# States Reported
# 33 Uttar Pradesh 19712
# 20 Maharashtra 11281
# 8 Delhi 6031
# 13 Jammu Kashmir 5658
# 10 Gujarat 4998
# 12 Himachal Pradesh 4335
# 4 Bihar 3712
# 27 Punjab 3627
# 35 West Bengal 3310
# 19 Madhya Pradesh 2543
# 28 Rajasthan 2293
# 9 Goa 2170
# 11 Haryana 2123
# 1 Andhra Pradesh 2030
# 16 Kerala 2025
# 6 Chhattisgarh 1860
# 5 Chandigarh 1860
# 15 Karnataka 1812
# 30 Tamil Nadu 1799
# 3 Assam 1637
# 25 Odisha 1484
# 31 Telangana 1285
# 17 Ladakh 1158
# 7 Dadra Nagar 587
# 21 Manipur 575
# 34 Uttarakhand 563
# 22 Meghalaya 409
# 2 Arunachal Pradesh 394
# 14 Jharkhand 340
# 26 Puducherry 307
# 32 Tripura 199
# 24 Nagaland 185
# 29 Sikkim 160
# 23 Mizoram 144
# 0 Andaman Nicobar 102
# 18 Lakshadweep 29
Now we will proceed to combine the above code to produce statistics for state wise crime reports grouped by type of crime.
I used the following code to derive values for the analysis we are performing, replacing crimeMerged with the combination of crimes I am analysing.
crimeMerged = murder
data ={
"States":['Andaman Nicobar', 'Andhra Pradesh', 'Arunachal Pradesh',
'Assam', 'Bihar', 'Chandigarh',
'Chhattisgarh', 'Dadra Nagar',
'Delhi', 'Goa', 'Gujarat', 'Haryana', 'Himachal Pradesh',
'Jammu Kashmir', 'Jharkhand', 'Karnataka', 'Kerala',
'Ladakh', 'Lakshadweep', 'Madhya Pradesh', 'Maharashtra',
'Manipur', 'Meghalaya', 'Mizoram', 'Nagaland', 'Odisha',
'Puducherry', 'Punjab', 'Rajasthan', 'Sikkim', 'Tamil Nadu'
, 'Telangana', 'Tripura', 'Uttar Pradesh',
'Uttarakhand', 'West Bengal'],
"Reported":[hd.countOccurancesGroupedAny([AndamanNicobar,crimeMerged]),hd.countOccurancesGroupedAny([AndhraPradesh,crimeMerged]),hd.countOccurancesGroupedAny([ArunachalPradesh,crimeMerged]),
hd.countOccurancesGroupedAny([Assam,crimeMerged]),hd.countOccurancesGroupedAny([Bihar,crimeMerged]),hd.countOccurancesGroupedAny([Chandigarh,crimeMerged]),
hd.countOccurancesGroupedAny([Chhattisgarh,crimeMerged]),hd.countOccurancesGroupedAny([Dadra,crimeMerged]),hd.countOccurancesGroupedAny([Delhi,crimeMerged]),
hd.countOccurancesGroupedAny([Goa,crimeMerged]),hd.countOccurancesGroupedAny([Gujrat,crimeMerged]),hd.countOccurancesGroupedAny([Haryana,crimeMerged]),
hd.countOccurancesGroupedAny([HimachalPradesh,crimeMerged]),hd.countOccurancesGroupedAny([JammuKashmir,crimeMerged]),hd.countOccurancesGroupedAny([Jharkand,crimeMerged]),
hd.countOccurancesGroupedAny([Karnataka,crimeMerged]),hd.countOccurancesGroupedAny([Kerala,crimeMerged]),hd.countOccurancesGroupedAny([Ladakh,crimeMerged]),
hd.countOccurancesGroupedAny([Lakshadweep,crimeMerged]),hd.countOccurancesGroupedAny([MadhyaPradesh,crimeMerged]),hd.countOccurancesGroupedAny([Maharashtra,crimeMerged]),
hd.countOccurancesGroupedAny([Manipur,crimeMerged]),hd.countOccurancesGroupedAny([Meghalaya,crimeMerged]),
hd.countOccurancesGroupedAny([Mizoram,crimeMerged]),hd.countOccurancesGroupedAny([Nagaland,crimeMerged]),hd.countOccurancesGroupedAny([Odisha,crimeMerged]),
hd.countOccurancesGroupedAny([Puducherry,crimeMerged]),hd.countOccurancesGroupedAny([Punjab,crimeMerged]),hd.countOccurancesGroupedAny([Rajasthan,crimeMerged]),
hd.countOccurancesGroupedAny([Sikkim,crimeMerged]),hd.countOccurancesGroupedAny([TamilNadu,crimeMerged]),hd.countOccurancesGroupedAny([Telangana,crimeMerged]),
hd.countOccurancesGroupedAny([Tripura,crimeMerged]),hd.countOccurancesGroupedAny([UttarPradesh,crimeMerged]),hd.countOccurancesGroupedAny([Uttarakhand,crimeMerged]),hd.countOccurancesGroupedAny([WestBengal,crimeMerged])]
}
df = pd.DataFrame(data)
print(df.sort_values("Reported",ascending=False))
The visualization in forms of a heat map for the 3 heavies (in terms of the range of dataset) is as follows:
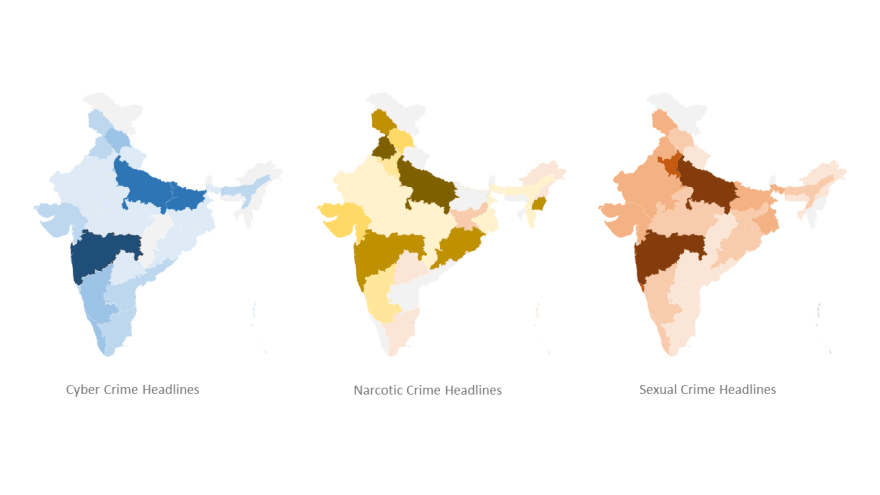 |
|---|
| Here darker colours represent heavier intensity of the labelled crime. |
This is a similar heatmap which encompasses a general image of crime intensity over the Indian states:
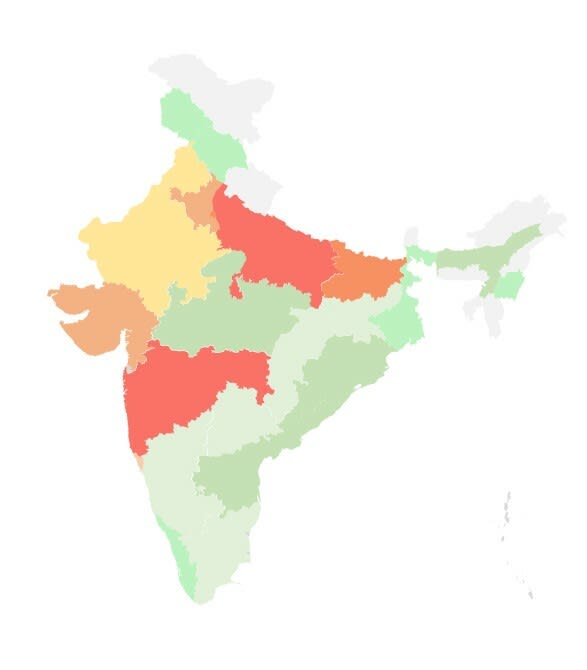 |
|---|
| Map of India: Warmer colours represent heavier intensity. |
The crime news statistics actually correspond to the real crime stats of the states as per government data. The only exception are the southern states. The southern states show much lower numbers in journalistic data compared to actual govt data. This raises an interesting question on what the reason can be? Is it journalistic bias? Unfortunately I am not qualified to answer that question but I do encourage you to find the answer to this question.
The Three Khans of Bollywood
I still remember when a famous saying used to be "Bollywood is ruled by the Three Khans". Well to take a lighter (away from crime and politics) look at the data, lets see which khan ends up the most popular amongst the three.

Here is the code which was run to find the most popular amongst the three.
srk = ["srk","shah rukh"]
salman = ["salman","sallu"]
amir = ["aamir",]
data = {"Actor":["SRK","Salman","Amir"],
"Reported":[hd.countOccurancesAny(srk),hd.countOccurancesAny(salman),hd.countOccurancesAny(amir)]
}
df = pd.DataFrame(data)
print(df.sort_values("Reported",ascending=False))
# Actor Reported
# 1 Salman 335
# 0 SRK 304
# 2 Amir 130
As it turns out its the "Bhai" of the industry. To be very honest it makes sense with how crazy his fans are.
PART 4: Epilogue
The aim of this endeavour was to make available a tool to be able to perform analysis like the ones shown above. And in that I have succeeded.
The scripts for the Web Scraper and the Headline Analysis Functions is available on the project repository.
It was extremely fun and informative working on this project. I learned and gained experience with the following:
- Web Scraping (BeautifulSoup, requests)
- Keyword Analysis
- Data Visualization
- Data Analysis (pandas, matplotlib)
- Open Source and Version Control
Thankyou very much for reading through the whole write-up. I really hope you found it interesting. Please leave a comment sharing any feedback.
This content originally appeared on DEV Community and was authored by Subh Chaturvedi
Subh Chaturvedi | Sciencx (2022-06-21T20:11:34+00:00) 25 Years of Indian Headlines: A Data Opportunity. Retrieved from https://www.scien.cx/2022/06/21/25-years-of-indian-headlines-a-data-opportunity/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.