
This content originally appeared on Level Up Coding - Medium and was authored by Joseph Gardi
Plus Empirical Notes on Deep Learning
For some context that’s not just a bullet list see my other article: Writing beautiful, reproducible, reversible, tested ML code should save time, not cost time
- Black formatting will ensure that your code is consistently formatted perfectly without you doing extra work. Use black formatting and integrate it with your editor: https://black.readthedocs.io/en/stable/editor_integration.html. It should automatically format your code every time you hit save
- Spend as little time as possible debugging. Debugging tends to frustrate people and consume huge amounts of time. Every time you encounter a difficult bug, think about how you could find that bug faster in the future. You essentially want to automate the process of debugging. Some ideas that help are
- Type hints. Type hints are the best because they find errors just milliseconds after you type them.
- Assertions are fantastic because they run every single time and find the error before the code even finishes running.
- Small fast unit tests
- Property-based tests: A lot of unit tests are just testing the cases that people think of off the top of their heads, but the hardest bugs tend to come from the cases we don’t foresee. Try to test on randomly generated data instead. You will usually not have labels for what the correct output should be on this randomly generated data, but assertions can reveal many issues automatically. - Sanity checks for debugging machine learning models:
- Always set a baseline using simple methods such as linear regression, kernel ridge regression, Gaussian process, random forest, or auto-sklearn. If the baseline doesn’t work that tells you that you made some dumb error in parsing the data
- Plots for diagnosing neural networks: https://towardsdatascience.com/useful-plots-to-diagnose-your-neural-network-521907fa2f45
- Ensure the model is in evaluation mode when testing so that dropout and batch normalization behave appropriately.
- Standardize and center the data. Not standardizing the data causes neural networks to fail completely and mysteriously. - Data hygiene / Garbage in, garbage out: You have to ensure you’re feeding in good data.
- The first step for any project should be visualizing in a Jupyter notebook.
- Use a histogram to look at the distribution of the data.
- Use anomaly detection based on entropy to identify anomalous data and then start manually examining anomalous examples. Entropy is a probabilistic measure of how surprising or interesting a particular piece of data is. - Do not waste time forgetting old commands you typed on the command line. Have some mechanism for remembering and searching through every command that you use. I use oh-my-zsh with vim keybindings and zsh history
- Use caching and multiprocessing to make your code run fast. Faster code means faster development and experimentation. Joblib is good for this. Cache everything in your ~/.[name of project] directory. Also, for runtime caching and wiring up complex dependencies, use python’s @cached_property decorator for lazy initialization. The cached properties make life easy because you don’t have to think about what order you initialize things (functions can call functions defined lower down in the file, while a variable can’t depend on a variable that is not yet defined).
- Use comet.ml to track experiments. Aim is open source and looks very promising but I have no experience with it and it is less mature since it’s new. Weights and biases is poorly architected in my opinion and they spend all their money on advertising rather than on making a better product. The weights and biases product itself seems to emphasize aesthetics. Perhaps weights and biases is a better fit for data science than ML engineering.
- Do not waste time manually tuning hyperparameters. This overfits the test set anyways. Use black-box optimization with validation accuracy instead. Make sure to record the results of your experiments. I’d recommend using comet.ml or pyGPGO
- In some cases, it makes sense to use PyTorch lightning to get well-structured code with lots of bells and whistles like early stopping and cyclic learning rate: https://pytorch-lightning.readthedocs.io/en/latest/new-project.html. See an example of integrating PyTorch lightning with comet.ml.
Empirical Notes on deep learning
- Debug neural networks by looking at histograms of activations, inputs, and outputs
- Use batch normalization almost always. Don’t forget to use model.eval() and model.train()
- Use small amounts of dropout in dense layers but never in convolutional layers. It is recommended to use 50% dropout on hidden layers. But I would start with tiny amounts of dropout because it requires a larger model and makes training unstable and slow. Don’t forget to use model.eval() and model.train() to turn dropout off.
- Optimizers are a hotly disputed topic and don’t make much difference, but for generalization, I would use SGD with Nesterov momentum. SGD with momentum generalizes better than adaptive learning rate methods like Adam (https://arxiv.org/pdf/1712.07628.pdf), and Nesterov gets better accuracy than classical momentum (http://proceedings.mlr.press/v28/sutskever13.pdf). Also, the simplicity of SGD is good for debugging. However, you will need an optimizer with an adaptive learning rate such as AdamW in order to deal with vanishing gradient problems. Also, AdamW often converges faster than SGD. If you really want something blazing fast with all the latest tricks, try Ranger.
- Resnet is the apex of many years of empirical experimentation on the imagenet dataset so it is worth studying its hyperparameters: https://towardsdatascience.com/an-overview-of-resnet-and-its-variants-5281e2f56035. Noteworthy features are:
- Most famously, it uses residual connections. This tends to make the resulting function smoother and combats the vanishing/exploding gradient problem
- Only two pooling layers. Pooling is helpful for translation invariance, but it is good not to use it more than once or twice because pooling throws away a considerable amount of information
- Stride one and kernel size 3 or 3x3 are almost always good choices if you have enough compute power for it.
- The number of neurons in a convolutional layer tends to be the same as the previous layer or double the previous layer. This is like how units of information tend to go up exponentially. For example, you have bytes, kilobytes, megabytes, and gigabytes. You also have half-precision floats (16 bits), floats (32 bits), and doubles which are 64 bits. - Deeper networks require a lower learning rate because the resulting functions tend to have higher curvature
- Use tanh, not sigmoid: https://stats.stackexchange.com/questions/330559/why-is-tanh-almost-always-better-than-sigmoid-as-an-activation-function. Indeed your network will often not even train with sigmoid. It is a little disturbing that something that easy to miss could make the whole thing not work because a benefit of ML is supposed to be letting the data take care of the details. But no. You have to know what you’re doing.
- You can usually get better performance on GPUs with little to no downside by using mixed-precision training
Theoretical Ideas
- No Free lunch theorem states that all algorithms actually have the same performance when averaged over all possible problems. This implies that no one machine learning algorithm can be the best solution for all problems. This is because all machine learning models must make some assumptions (inductive bias) to generalize beyond the training data and make predictions about new inputs. These assumptions or inductive biases cannot apply equally well to all problems. Another implication is that no one compression algorithm or dimensionality reduction can work well on all data. For more on No Free Lunch Theorem see my earlier post.
- Understand Occam’s razor, which states that the simplest explanation is the most likely. We should therefore prefer simpler machine learning models. https://www.dropbox.com/s/2qrefr8fiks6gvi/occamsrazor.pdf?dl=0
- Take a look at Chomsky’s universal grammar: https://en.wikipedia.org/wiki/Universal_grammar.
- Understand the limits of humans understanding and how it applies to machine learning: Youtube: Noam Chomsky Interview on Limits of Language & Mind
- Deep relations between kernels, distance metrics, probability, and entropy: Kernels are equivalent to divergences (which are often a distance squared) where
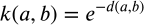
Here d is a divergence which equals a distance squared. and this is an isomorphic function so
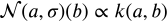
So divergences are negative log-likelihoods; in other words, distance squared is equivalent to entropy.
- Know that Neural networks are equivalent to Gaussian processes in the limit of infinite neurons. But also know that Gaussian processes are O(n³) where n is the number of training examples while neural networks are O(n)
- According to mercer’s theorem, we can approximate any positive definite kernel (a measure of similarity) as a dot product in a sufficiently high dimension.
- Any high-dimensional space can be understood by looking at many low-dimensional projections. Use this to deal with the curse of dimensionality. Humans understand the 4-dimensional world by looking at just 2(one from each eye) 2-dimensional projections of the world at a time. The proof is at https://medium.com/cantors-paradise/the-johnson-lindenstrauss-lemma-3058a123c6c. This is the principle that Spotify annoy uses to do approximate nearest neighbors search in extremely high dimensional spaces. Spotify uses Spotify annoy for their music recommendations. For example, humans understand their 4-dimensional world by looking at many tiny 2-dimensional projections. Each eyeball only sees a very small 2d projection at any given time.
- A picture is worth a thousand words: Understand everything visually because the visual cortex is like the brain’s GPU. See the big picture of what you want to build before coding.
I hope you found this helpful. Any feedback or suggestions for this would be appreciated! 🙏
Level Up Coding
Thanks for being a part of our community! More content in the Level Up Coding publication.
Follow: Twitter, LinkedIn, Newsletter
Level Up is transforming tech recruiting ➡️ Join our talent collective
Essential Engineering Principles For ML was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Joseph Gardi
Joseph Gardi | Sciencx (2022-06-23T02:11:12+00:00) Essential Engineering Principles For ML. Retrieved from https://www.scien.cx/2022/06/23/essential-engineering-principles-for-ml/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.