
This content originally appeared on DEV Community and was authored by valeriadibattista
A real case study on how AWS serverless ecosystem can give your product a lot of value with minimum effort
Publications about serverless adoption often miss a practical approach that can make it affordable in real-life use case scenarios. In Neosperience Cloud Services (formerly Mikamai) we challenge this pure theoretical adoption of serverless technologies, testing our skills in large scale projects that can leverage the full potential of serverless. One of the most interesting use cases is our BeatIdentity client.
Their platform contains thousands of instrumental music tracks, offered on an ecommerce platform in different takes. A user can select them one by one, or as part of a playlist.
The platform has to create a cover for each track and make clear when it belongs to a single or a playlist. Sometimes, due to marketing reasons, the client may need a cover image with the BeatIdentity logo as a watermark.
Since doing this task manually is extremely time consuming and stressful for content creators, we supported the company in building the BeatId Generator.
Thanks to the work of the Neosperience design team, along with the customer, we created a tool, using Processing, to procedurally generate the cover image from track details such as title, artist, instruments, whether it is part of a playlist or needs the logo.
A sample of the resulting images is as follows, either with a standalone song (the pink images) or a playlist (the purple images):

This core logic needs to be packaged within a service capable of storing the images in a way they could be easily retrieved in the future by third party applications (e.g. the ecommerce platform) or by BeatIdentity employees. Infrequent and unpredictable access patterns as well as maintenance considerations suggest this could be built as a cloud native application, leveraging all the benefits coming from serverless.
Project Overview
The application should support the following use cases:
- A general user can get an already generated cover in high resolution or in a custom defined size;
- A third party application can upload a single track, letting the system generate the high resolution versions of the cover;
- A BeatIdentity Admin can import a single track or massively import multiple tracks uploading a CSV file. At the end of the CSV import process the user can download a zip archive containing all the generated files.
The AWS Cloud Development Kit (CDK) lets define the AWS cloud infrastructure in a general-purpose programming language. Among the several available ones, we chose Typescript to take advantage of the benefits this programming language serves. Instead of writing the resulting Cloud Formation Stacks using the native JSON or YAML format, Typescript makes infrastructure design, deployment and the overall coding experience more enjoyable, even allowing good practices such as code reviews, unit tests, and source control to make the infrastructure more robust.
The overall architecture, implementing the beforehand use cases leverages the following AWS services:
- Lambda: it’s the core of our serverless application, since it allows us to run the code without caring about provisioning or managing servers (and only pay per use!);
- Amazon API Gateway: it sits in front of our lambdas exposing them as REST APIs and taking care of authentication;
- Amazon Cognito: this takes care of authenticating our users;
- Amazon S3: as a storage service, it helps us to manage data in every format we will need, storing them as objects in Buckets;
- AWS SQS: it’s a queue service and we use it as a decoupling mechanism, to avoid losing messages;
- Amazon DynamoDB: the fully managed NoSQL service offered by AWS. We use it to persist generation info and let users and third parties know the status of each of their imports;
- Amazon CloudFront: simply put, it’s a CDN fully integrated with the AWS ecosystem. We use it for caching and for generating resized covers on the fly;
- AWS Code Pipeline and AWS Code Build: to take advantage of the CI/CD approach in order to automatically build and deploy our code.
We need to store on Amazon S3 different sets of data, thus we defined four buckets starting from the access patterns:
- CSV Bucket: used for uploading the CSVs (via presigned URLs);
- Track Bucket: used for storing the track metadata. This bucket has no public access and is used only by the lambdas to write and read them;
- Image Bucket: this bucket is served by Cloudfront and contains the generated cover and the zip archives;
- Frontend Bucket: for storing the frontend web application, written in React. The bucket assets are then served by Cloudfront.
Using multiple buckets (instead of just one bucket for everything) makes our life easier for handling permissions and reduces the chance of human error.
The Cover Generation Lambda
The Lambda which translates the Processing algorithm must reproduce all the expected behaviors, such as receiving track details, generating some variables and colors, drawing shapes and applying stickers, if needed.
All the Processing APIs used by the algorithm were available as part of the Canvas API. So we decided to convert the Processing code in Typescript and use the node-canvas package to reproduce the same behavior. This package needs some native libraries which can be easily provisioned on the Lambda function via an existing AWS Lambda Layer.
Once we were able to replicate the algorithm result, making it work as a Lambda function was the easiest part: we just needed to slightly change our function definition to adhere to the lambda event specification.
The function would need to access several static assets which would make the deploy artifact bigger. We could have used S3 for them, but this would result in a lot of unnecessary API requests, so we moved these assets in a Lambda Layer too.
Having the cover generation lambda complete, the rest of the product was already appearing as an easy task. We divided the rest of this serverless architecture into three main parts, described in the following paragraphs.
Single Track Creation
The simplest flow is the Single Track Image Creation. The flow is thought to be used by a third party user and the BeatIdentity admin.
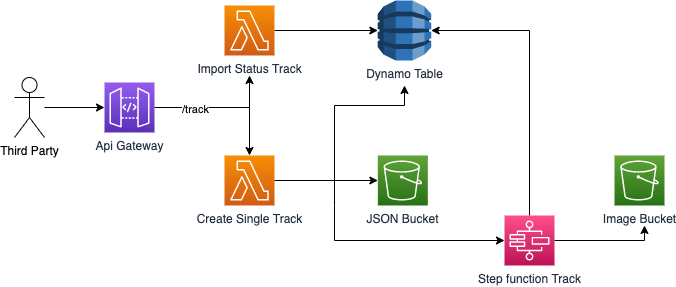
There are two APIs that need to be called by third party services. They are implemented as Lambda Functions and exposed via API Gateway and authenticated against an API Key.
Calling the “Create Single Track” API will insert the corresponding record in DynamoDB, save the JSON details in the JSON Bucket and start the Step Function workflow, which is async. This way the HTTP request is not blocked by the cover generation, and the user can know if the generation is complete by calling the Status API, which fetches the status from the corresponding record on DynamoDB. The state machine provided by the AWS Step function allows us to perform all the tasks needed to call the “Cover Generation” Lambda, keep the corresponding record on DynamoDB updated, and handle errors.
CSV Upload
The aim of the second flow is to allow BeatIdentity admins to massively import hundreds of tracks at the same time uploading a CSV in which each row represents a track.

At the very start of the flow, the frontend application calls the “Presigned URL” API to obtain a presigned URL which allows uploading the CSV on the S3. This technique guarantees a secure way of:
- Keeping the CSV bucket private;
- Offloading the file from our service to S3, reducing the overhead of receiving the file on the backend and then uploading it from the backend onto S3.
More info on this topic can be found here.
When the upload on S3 is complete, a message is propagated to a SQS Queue, and consumed by a Lambda Function (Start State Machine) which is responsible for starting the Step Function responsible of processing the CSV (a Step Function cannot be started directly from an SQS queue). If any error occurs, a message will be requeued and, if the error persists, after some time it will be archived in a DLQ queue for further analysis.
The Step Function of this flow is slightly different with respect to the previous one, since it needs to create images from each CSV row as fast as possible. Thus, the iterator operator was implemented to perform the actions in parallel and to process rows in groups of 5 elements for each iteration. At the end of the generation a zip archive is created containing all the generated Covers and stored in the Image Bucket to be later downloaded.
Cover Request
Until this point each generated image can be fetched in its high resolution size. But someone may also need scaled down versions. To allow this we implemented a common pattern through Lambda@Edge.

When a cover image is requested to Cloudfront (its path starts with “/covers”), the request is sent to S3 to retrieve an object from there. The S3 response is then handled by a Lambda@Edge which is a special Lambda acting as a middleware.
If the S3 response is a “Not Found Object” and the requested path is referring to a cover image, the Lambda@Edge will fetch the high resolution image from S3, size it down to the desired dimension, store it on S3 and return the image content. This way on the next request for the same object, S3 would return the resized version and the Lambda would just ignore the message.
This pattern is explained in detail here.
What we got at the end of the day
We could have delivered this product in a plain, classic way: a simple server configured with Java and Processing and a couple of PHP web pages. The user would have used the web pages to let PHP handle the Processing sketch and generated the images, maybe storing them on the EC2 EBS itself. This would have reduced (slightly) the development time, but at what cost?
- Scaling is not obvious and needs some additional work;
- Security is not by-default. An EC2 server needs additional work on this point too;
- The instance needs periodic updates;
- The infrastructure has fixed costs, even if we don’t use the platform.
Instead we decided to aim for a fully serverless architecture:
- The cover generation lambda and the resize lambda@edge function complete their work in about 2 seconds, which means that generating covers for 1 MILLION tracks will cost 34$ which is slightly less than paying a t3a.large EC2 instance;
- We don’t have to take care of infrastructure security at the same level of classic infrastructures, we just need to ensure the correct permissions are set and that our code is not faulty;
- We have built-in decoupling between the different components, which means changing a peace of our design is pretty easy;
- Thanks to CDK we have a single repository, put in CI/CD, which contains both our infrastructure and application logic, in a homogeneous language, making it easy to understand how data is flowing.
Overall, the final result exceeded the client expectations, and the effort required to both translate the original generation algorithm to a different language and to develop the product with a serverless approach required the same time we would have needed to provision and properly configure a classic infrastructure.
Looking at the repository, it’s easy to see which components do what in our architecture, because the stack code appears as an imperative function of code composing pieces together and adding behaviors. For example, we create a csvBucket, then we create a “CSVGenerationFSM” (which is a construct for our step function) then we do “fsm.bindToS3Bucket(csvBucket)” to imply that our step function will start when an event is triggered on the csv bucket.
So, our advice is, don’t be afraid of the serverless world, and don’t play safe! Just start playing with it and look at some other architectural examples (like the one we talked about in this post) to get inspiration for improving your design more and more.
Some advice for the beginners:
- The AWS world aims for security over all. If you have a bucket and a lambda, you have to explicitly give permission to the lambda to write or read on that bucket, and you can also scope this permission to specific objects or prefixes. This applies to any AWS service and to any action you make on them. So, even if it may seem complicated when you start, once you’ll get used to it, you’ll discover your products have never been so robust and secure!
- It’s not you that are not good at googling for documentation! This is indeed one the few things on which AWS could improve. And they are doing it, because if you look at the CDK documentation, it’s awesome!
Co-Authored with: Antonio Riccio
This content originally appeared on DEV Community and was authored by valeriadibattista
valeriadibattista | Sciencx (2022-07-11T07:30:44+00:00) A Serverless Architecture to handle image generation from bulk data. Retrieved from https://www.scien.cx/2022/07/11/a-serverless-architecture-to-handle-image-generation-from-bulk-data/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.