
This content originally appeared on DEV Community and was authored by Gwen (Chen) Shapira
It started innocently enough. During standup, someone mentioned “my branch deployment is a bit slow due to cold-start problem, but no big deal”. Indeed, cold-start should have no impact on production where the environment is long running. No big deal.
But later the same day, I tried checking something in a test system and noticed that a lot of my requests were taking very long time. In fact, I couldn’t get anything done. Since this environment was also long running, it could not be cold start problem.
Cloudwatch metrics on the load balancer showed that all requests return in 6ms or less and that they are all successful. My home internet seemed fine. Time to get an external view.
I set up Pingdom to get our /healthcheck every minute and the pattern became clear: 50% of the response times were around 300ms. The other 50% took over 15s.
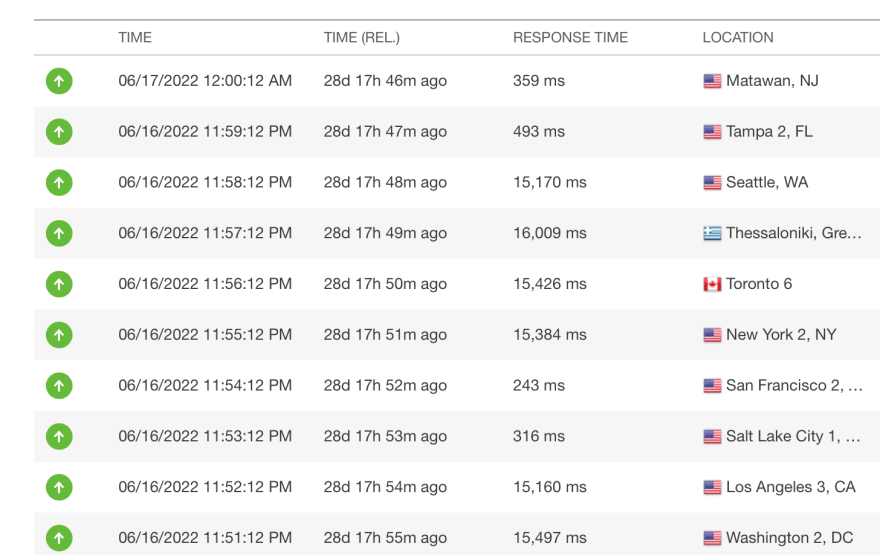
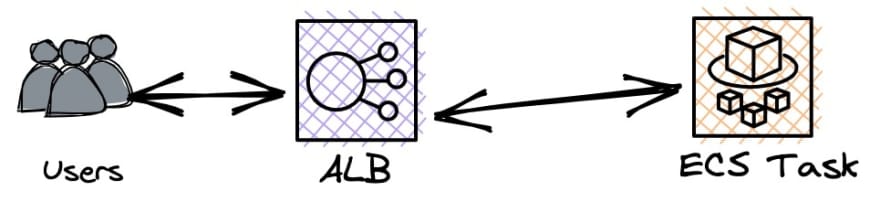
Up until this point, my mental model of our deployment was something like this (we have more stuff, but it isn’t relevant here):
I ran Wireshark on my machine and ran a bunch of test requests. The 50% that were successful talked to one IP and the other 50% talked to another IP.
Looking at our configuration, I discovered that our ALB has two availability zones and cross-zone failover. This is mandatory for ECS tasks. So now I had a better mental model:
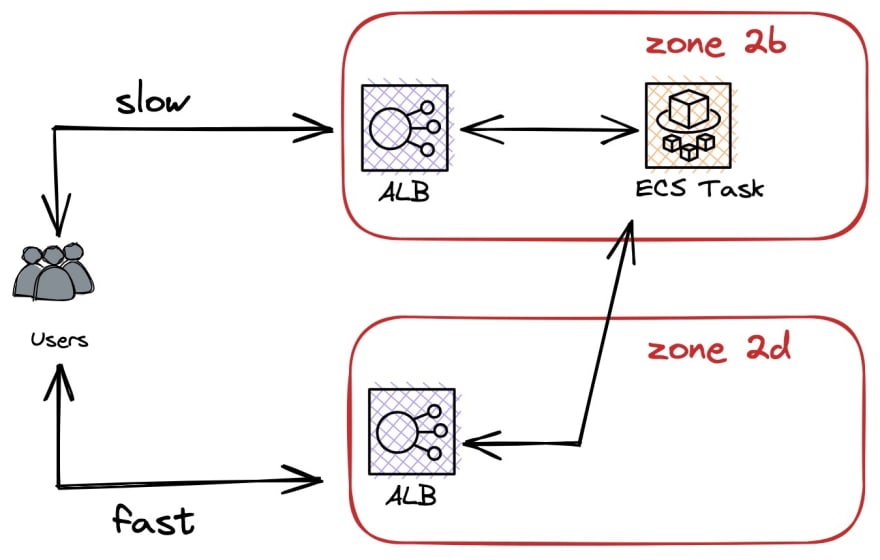
Note that we have LB in both zones, but ECS task in just on of them. An AWS documentation page that I can no longer find said something like “for best performance, run ECS task in every zone that has a load balancer”. I was naive enough to believe that I found the issue and went ahead to set up the extra tasks.
It took longer than I would have liked because zone 2d didn’t have the EC2 machine type that my task required, so I had to re-configure everything around a new machine type or move everything around zones, which meant learning more about ASG and ECS. But finally I had the following configuration:
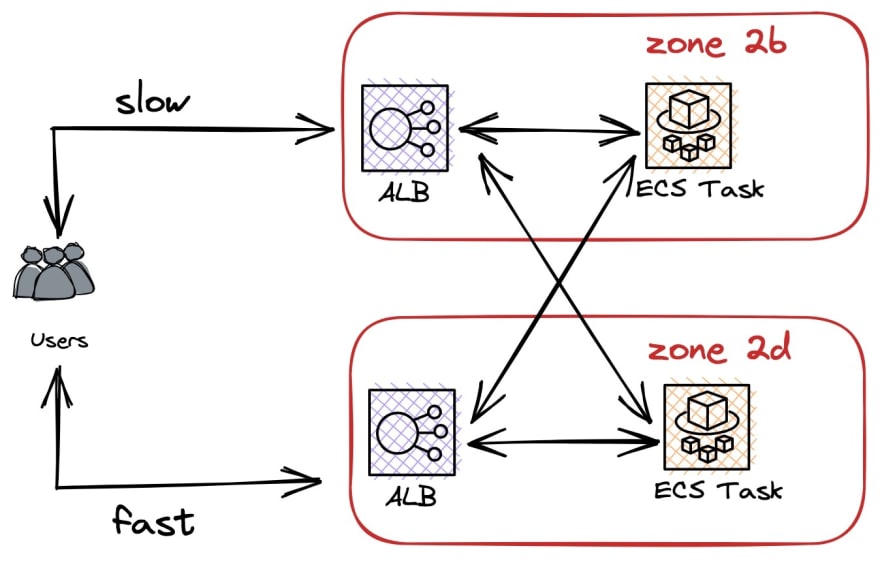
Unfortunately, the performance issue remained. Damn it.
I went back to the original system, but investigated the network configuration in more detail. One detail that I discarded until then was that few days earlier, after a long investigation and much debates, we added a NAT to our system.
Why NAT? Because our ECS task occasionally had to make an outbound call to a public service (Google’s identity platform) and our investigation revealed that the only way an EC2 ECS task can make an external call is via NAT. Worth noting that Fargate and EC2 don’t have this limitation. I am not sure we would have used ECS EC2 if we knew about it - NATs are expensive.
When we added the NAT we also added a routing rule (as documented). Outgoing traffic from zone 2b (the zone with the task) will be routed via the NAT. The actual architecture that I worked on was actually:
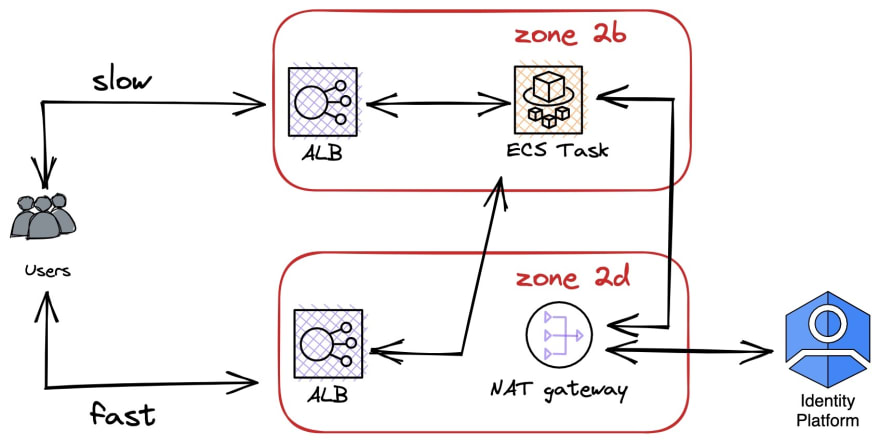
With these routing rules, traffic that users initiated went through the internet gateway (this is the default way services with public IP address talk to the internet in AWS) to the LB to the task and then back. Outbound traffic went to the NAT.
Or so we thought.
The routing rule that we added to zone 2b for the NAT didn’t really say “outbound traffic goes via NAT”. It rather said: “If destination is anywhere outside the VPC, go via NAT”. I assumed it applied to outbound only, but our load balancer is in the subnet that has these rules.
What if any time the LB tries to send a response to a user, it actually gets routed via the NAT and AWS networking doesn’t deal with this very well?
I have no proof for this theory. I spent a bunch of time playing with AWS's network reachability analyzer. It is nifty, but I couldn't create the routes that would conclusively prove this theory.
But I was out of any more ideas, so I decided that if the theory is right, I need to get the LB that is in zone 2b to a zone that doesn't have the NAT routing rule.
Why not move the LB to zone 2c? Turns out that ECS requires an LB to exist in the zone where the task exists.
We ended up with a messy solution and a better solution for the long term.
Messy solution:
Modify the routing rules. Instead of routing all traffic that goes to the internet via the NAT, we’ll route only traffic going to Google via the NAT. Luckily Google published its IP ranged, so I could add routing rules specific to it: https://www.gstatic.com/ipranges/goog.txt
This isn't a great solution because we'll need to add more routes for every external service we'll need to access.
Better solution:
Use the fact that routing rules apply to subnets but ECS tasks need an LB in the same zone. So we can create two subnets in each zone. One with virtual network equipment and the other with tasks. Something like this:
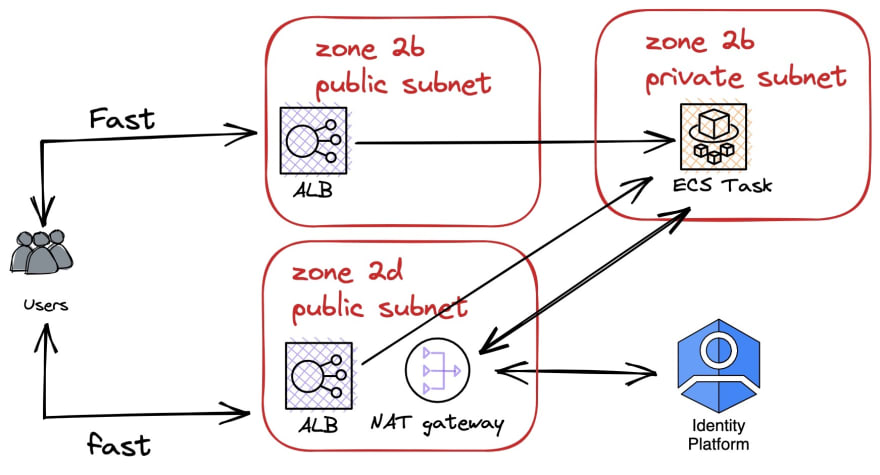
This is very similar to pretty much every diagram AWS publishes about how to set up public internet access for services. They all look like this:
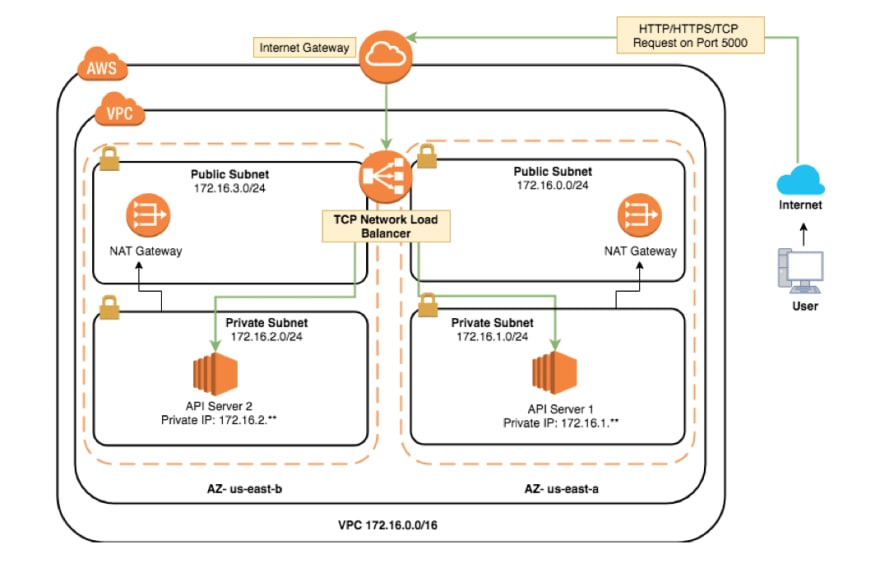
I just wish they explained why they set it up that way and what happens if you don’t. But here is the full story, at least my readers won't need to learn about it the hard way.
Enjoyed reading this?
- Read more about Infra SaaS and Control Planes on my company blog.
- Or join the SaaS Developer Community Slack.
This content originally appeared on DEV Community and was authored by Gwen (Chen) Shapira
Gwen (Chen) Shapira | Sciencx (2022-07-16T02:53:24+00:00) Investigating 15s HTTP response time in AWS ECS. Retrieved from https://www.scien.cx/2022/07/16/investigating-15s-http-response-time-in-aws-ecs/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.