
This content originally appeared on DEV Community and was authored by Abhishek Gupta
Replicate DynamoDB data from one table to another
This blog post will help you get quickly started with DynamoDB Streams and AWS Lambda using Go. It will cover how to deploy the entire solution using AWS CDK.
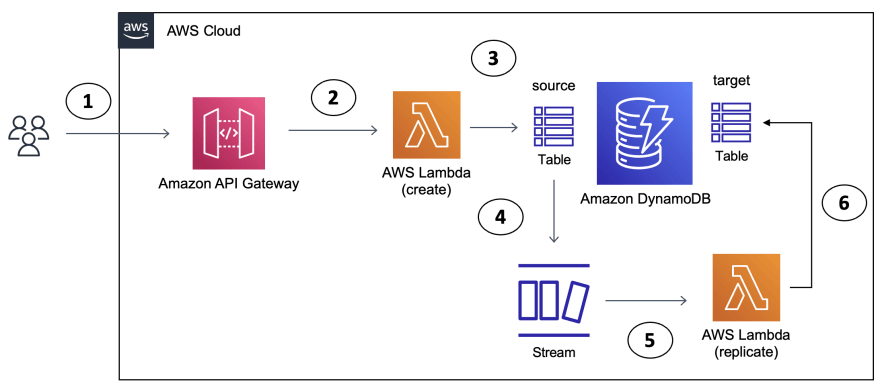
The use case presented here is pretty simple. There are a couple of DynamoDB tables and the goal is to capture the data in one of those tables (also referred to as the source table) and replicate them to another table (also referred to as the target table) so that it can serve different queries. To demonstrate an end-to-end flow, there is also an Amazon API Gateway that front ends a Lambda function which persists data in the source DynamoDB table. Changes in this table will trigger another Lambda function (thanks to DynamoDB Streams) which will finally replicate the data into the target table.
Global or Local Secondary Index offer similar capability.
Now that you have an overview of what we are trying to achieve here...
.. let's get right to it!
Before you proceed, make sure you have the Go programming language (v1.16 or higher) and AWS CDK installed.
Clone the project and change to the right directory:
git clone https://github.com/abhirockzz/dynamodb-streams-lambda-golang
cd cdk
To start the deployment...
.. all you need to do is run a single command (cdk deploy), and wait for a bit. You will see a list of resources that will be created and will need to provide your confirmation to proceed.
Don't worry, in the next section I will explain what's happening.
cdk deploy
# output
Bundling asset DynamoDBStreamsLambdaGolangStack/ddb-streams-function/Code/Stage...
✨ Synthesis time: 5.94s
This deployment will make potentially sensitive changes according to your current security approval level (--require-approval broadening).
Please confirm you intend to make the following modifications:
//.... omitted
Do you wish to deploy these changes (y/n)? y
This will start creating the AWS resources required for our application.
If you want to see the AWS CloudFormation template which will be used behind the scenes, run
cdk synthand check thecdk.outfolder
You can keep track of the progress in the terminal or navigate to AWS console: CloudFormation > Stacks > DynamoDBStreamsLambdaGolangStack

Once all the resources are created, you can try out the application. You should have:
- Two Lambda functions
- Two DynamoDB tables (source and target)
- One API Gateway (also route, integration)
- along with a few others (like IAM roles etc.)
Before you proceed, get the API Gateway endpoint that you will need to use. It's available in the stack output (in the terminal or the Outputs tab in the AWS CloudFormation console for your Stack):

End to end solution...
Start by creating a few users in the (source) DynamoDB table
To do this, invoke the API Gateway (HTTP) endpoint with the appropriate JSON payload:
# export the API Gateway endpoint
export APIGW_ENDPOINT=<replace with API gateway endpoint above>
# for example:
export APIGW_ENDPOINT=https://gy8gxsx9x7.execute-api.us-east-1.amazonaws.com/
# invoke the endpoint with JSON data
curl -i -X POST -d '{"email":"user1@foo.com", "state":"New York","city":"Brooklyn","zipcode": "11208"}' -H 'Content-Type: application/json' $APIGW_ENDPOINT
curl -i -X POST -d '{"email":"user2@foo.com", "state":"New York","city":"Staten Island","zipcode": "10314"}' -H 'Content-Type: application/json' $APIGW_ENDPOINT
curl -i -X POST -d '{"email":"user3@foo.com", "state":"Ohio","city":"Cincinnati","zipcode": "45201"}' -H 'Content-Type: application/json' $APIGW_ENDPOINT
curl -i -X POST -d '{"email":"user4@foo.com", "state":"Ohio","city":"Cleveland","zipcode": "44101"}' -H 'Content-Type: application/json' $APIGW_ENDPOINT
curl -i -X POST -d '{"email":"user5@foo.com", "state":"California","city":"Los Angeles","zipcode": "90003"}' -H 'Content-Type: application/json' $APIGW_ENDPOINT
Navigate to the DynamoDB table in the AWS console and ensure that records have been created:
If you the AWS CLI handy, you can also try
aws dynamodb scan --table <name of table>

If all goes well, our replication function should also work. To confirm, you need to check the target DynamoDB table.

Notice that the
zipcodeattribute is missing - this is done on purpose for this demo. You can pick and choose the attributes you want to include in the target table and write your function logic accordingly.
The target DynamoDB table has state as a partition key and city as the sort key, you can query it in a different way (as compared to the source table which you could query only based on email).
Don't forget to clean up!
Once you're done, to delete all the services, simply use:
cdk destroy
#output prompt (choose 'y' to continue)
Are you sure you want to delete: DynamoDBStreamsLambdaGolangStack (y/n)?
Awesome! You were able to setup and try the complete solution. Before we wrap up, let's quickly walk through some of important parts of the code to get a better understanding of what's going the behind the scenes.
Code walk-through
Since we will only focus on the important bits, lot of the code (print statements, error handling etc.) omitted/commented out for brevity.
Infra-IS-code with AWS CDK and Go!
You can refer to the CDK code here
We start by creating a DynamoDB table and ensure that DynamoDB Streams is enabled.
sourceDynamoDBTable := awsdynamodb.NewTable(stack, jsii.String("source-dynamodb-table"),
&awsdynamodb.TableProps{
PartitionKey: &awsdynamodb.Attribute{
Name: jsii.String("email"),
Type: awsdynamodb.AttributeType_STRING},
Stream: awsdynamodb.StreamViewType_NEW_AND_OLD_IMAGES})
sourceDynamoDBTable.ApplyRemovalPolicy(awscdk.RemovalPolicy_DESTROY)
Then, we handle the Lambda function (this will take care of building and deploying the function) and make sure we provide it appropriate permissions to write to the DynamoDB table.
createUserFunction := awscdklambdagoalpha.NewGoFunction(stack, jsii.String("create-function"),
&awscdklambdagoalpha.GoFunctionProps{
Runtime: awslambda.Runtime_GO_1_X(),
Environment: &map[string]*string{envVarName: sourceDynamoDBTable.TableName()},
Entry: jsii.String(createFunctionDir)})
sourceDynamoDBTable.GrantWriteData(createUserFunction)
The API Gateway (HTTP API) is created, along with the HTTP-Lambda Function integration as well as the appropriate route.
api := awscdkapigatewayv2alpha.NewHttpApi(stack, jsii.String("http-api"), nil)
createFunctionIntg := awscdkapigatewayv2integrationsalpha.NewHttpLambdaIntegration(jsii.String("create-function-integration"), createUserFunction, nil)
api.AddRoutes(&awscdkapigatewayv2alpha.AddRoutesOptions{
Path: jsii.String("/"),
Methods: &[]awscdkapigatewayv2alpha.HttpMethod{awscdkapigatewayv2alpha.HttpMethod_POST},
Integration: createFunctionIntg})
We also need the target DynamoDB table - note that this table has a composite Primary Key (state and city):
targetDynamoDBTable := awsdynamodb.NewTable(stack, jsii.String("target-dynamodb-table"),
&awsdynamodb.TableProps{
PartitionKey: &awsdynamodb.Attribute{
Name: jsii.String("state"),
Type: awsdynamodb.AttributeType_STRING},
SortKey: &awsdynamodb.Attribute{
Name: jsii.String("city"),
Type: awsdynamodb.AttributeType_STRING},
})
targetDynamoDBTable.ApplyRemovalPolicy(awscdk.RemovalPolicy_DESTROY)
Finally, we create the second Lambda function which is responsible for data replication, grant it the right permissions and most importantly, add the DynamoDB as the event source.
replicateUserFunction := awscdklambdagoalpha.NewGoFunction(stack, jsii.String("replicate-function"),
&awscdklambdagoalpha.GoFunctionProps{
Runtime: awslambda.Runtime_GO_1_X(),
Environment: &map[string]*string{envVarName: targetDynamoDBTable.TableName()},
Entry: jsii.String(replicateFunctionDir)})
replicateUserFunction.AddEventSource(awslambdaeventsources.NewDynamoEventSource(sourceDynamoDBTable, &awslambdaeventsources.DynamoEventSourceProps{StartingPosition: awslambda.StartingPosition_LATEST, Enabled: jsii.Bool(true)}))
targetDynamoDBTable.GrantWriteData(replicateUserFunction)
Lambda Function - create user
You can refer to the Lambda Function code here
The function logic is pretty straightforward - it converts the incoming JSON payload into a Go struct and then invokes DynamoDB PutItem API to persist the data.
func handler(ctx context.Context, req events.APIGatewayV2HTTPRequest) (events.APIGatewayV2HTTPResponse, error) {
payload := req.Body
var user User
err := json.Unmarshal([]byte(payload), &user)
if err != nil {//..handle}
item := make(map[string]types.AttributeValue)
item["email"] = &types.AttributeValueMemberS{Value: user.Email}
item["state"] = &types.AttributeValueMemberS{Value: user.State}
item["city"] = &types.AttributeValueMemberS{Value: user.City}
item["zipcode"] = &types.AttributeValueMemberN{Value: user.Zipcode}
item["active"] = &types.AttributeValueMemberBOOL{Value: true}
_, err = client.PutItem(context.Background(), &dynamodb.PutItemInput{
TableName: aws.String(table),
Item: item,
})
if err != nil {//..handle}
return events.APIGatewayV2HTTPResponse{StatusCode: http.StatusCreated}, nil
}
Lambda Function - replicate data
You can refer to the Lambda Function code here
The handler for the data replication function accepts DynamoDBEvent as a parameter. It extracts the new added record and creates a new record which can be saved to the target DynamoDB table. The data type for each attribute is checked and handled accordingly. Although the code just shows String and Boolean types, this can be used for other DynamoDB data types such as Maps, Sets etc.
func handler(ctx context.Context, e events.DynamoDBEvent) {
for _, r := range e.Records {
item := make(map[string]types.AttributeValue)
for k, v := range r.Change.NewImage {
if v.DataType() == events.DataTypeString {
item[k] = &types.AttributeValueMemberS{Value: v.String()}
} else if v.DataType() == events.DataTypeBoolean {
item[k] = &types.AttributeValueMemberBOOL{Value: v.Boolean()}
}
}
_, err := client.PutItem(context.Background(), &dynamodb.PutItemInput{
TableName: aws.String(table),
Item: item})
if err != nil {//..handle}
}
}
Here are some things you can try out:
- Insert more data in the source table - look for ways to do bulk inserts into a DynamoDB table
- Execute queries in the target table based on
state,cityor both.
Wrap up
In this blog, you saw a simple example of how to leverage DynamoDB Streams to react to table data changes in near-real time using a combination of DynamoDB Streams and Lambda functions. You also used AWS CDK to deploy the entire infrastructure including API Gateway, Lambda Functions, DynamoDB tables, integrations as well as Lambda event source mappings.
All this was done using the Go programming language, which is very well supported in DynamoDB, AWS Lambda and AWS CDK.
Happy building!
This content originally appeared on DEV Community and was authored by Abhishek Gupta
Abhishek Gupta | Sciencx (2022-07-21T04:04:22+00:00) Learn how to use DynamoDB Streams with AWS Lambda and Go. Retrieved from https://www.scien.cx/2022/07/21/learn-how-to-use-dynamodb-streams-with-aws-lambda-and-go/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.