
This content originally appeared on Level Up Coding - Medium and was authored by Afaque Umer
RegEx — The only Ex you need to Remember!

Regular expressions (RegEx) are an incredibly powerful tool for manipulating text and data. They are used in a wide variety of applications, from search engines to text editors to programming languages. In Python, regular expressions are available through the built-in re module.
The module provides a number of functions and classes for working with regular expressions. When coupled with NLP pipelines it becomes a powerful asset for feature extraction from text, string replacement, and other string manipulations. Read official documentation here.
This blog post will explain the basics of regular expressions and how to use them in Python. After reading this article, you will be able to use regular expressions to solve a variety of real-world problems.
Functions in RegEx
The re module offers a bunch of functions that allows us to search a string for the pattern we defined, but here , only the most frequently used ones are covered.
re.search(pattern, string):
Searches the string for a match, returns only the first occurrence of the match if there is a match None otherwise.
re.findall(pattern, string):
Return a list of all non-overlapping matches in the string else None if no position in the string matches the pattern.
re.split(pattern, string):
It returns a list where the string has been split at each match.
re.sub(pattern, replacement, string):
This replaces the matches with the text of your choice.
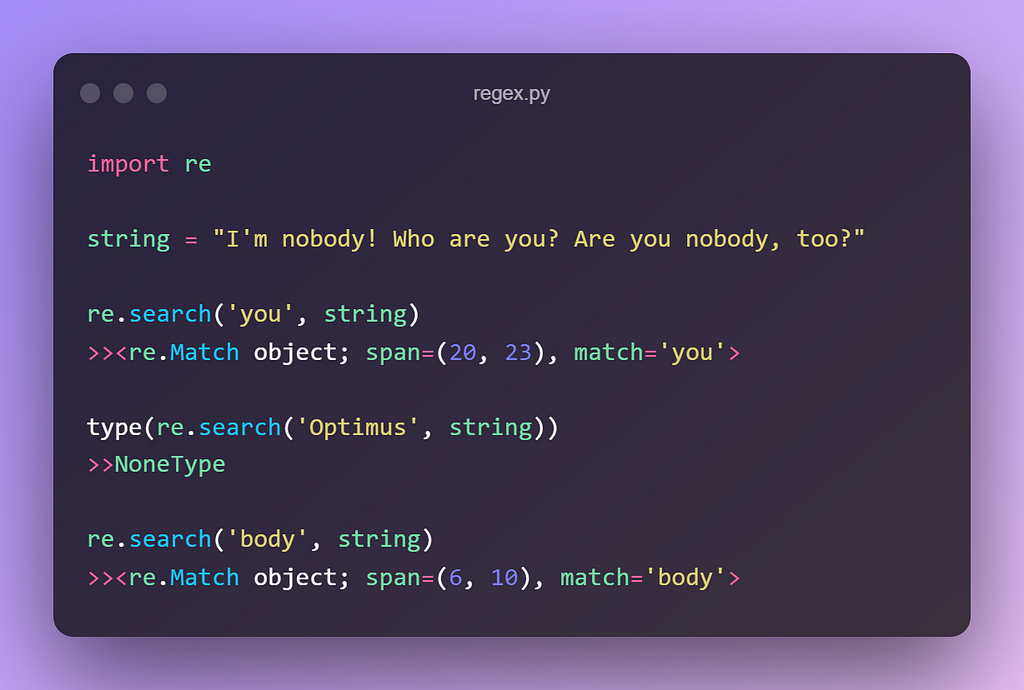
1. re.search(pattern, string)
It will look for the first occurrence of a pattern/regex and returns a match object otherwise, it returns “null”. It will verify all rows of the target string.
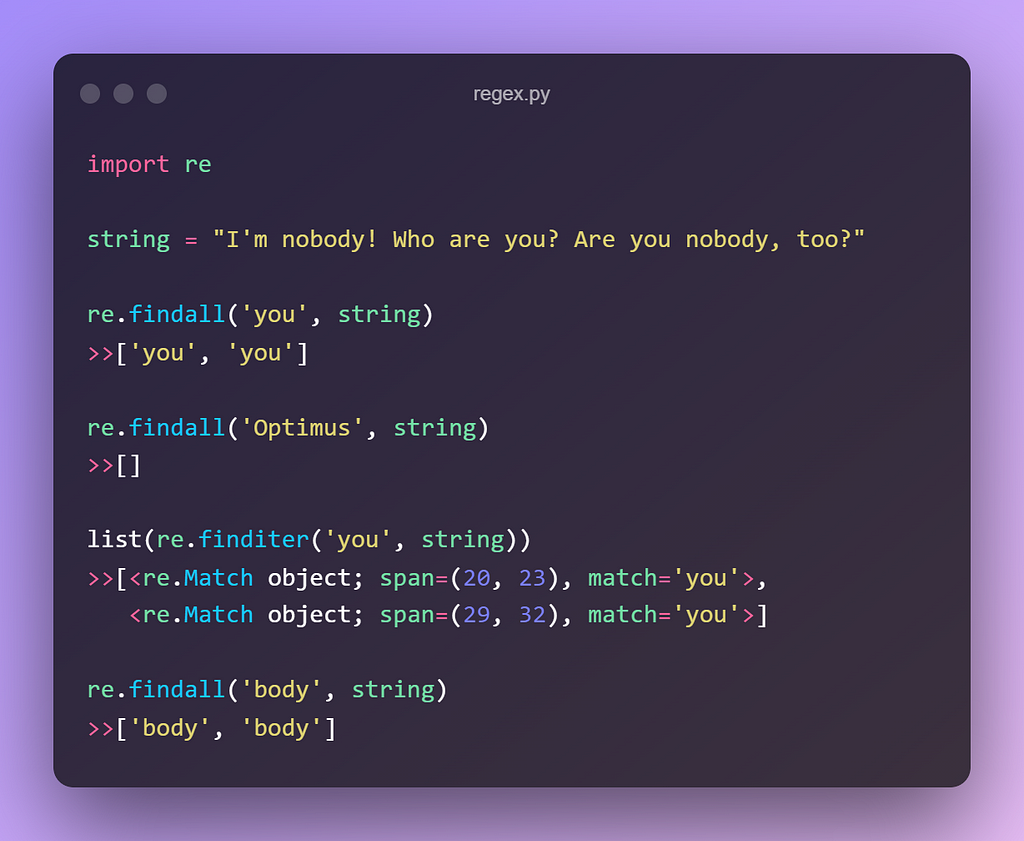
2. re.findall(pattern, string)
This function is used to look for “all” possible non-overlapping appearances of the pattern looping over all the rows of the target string.
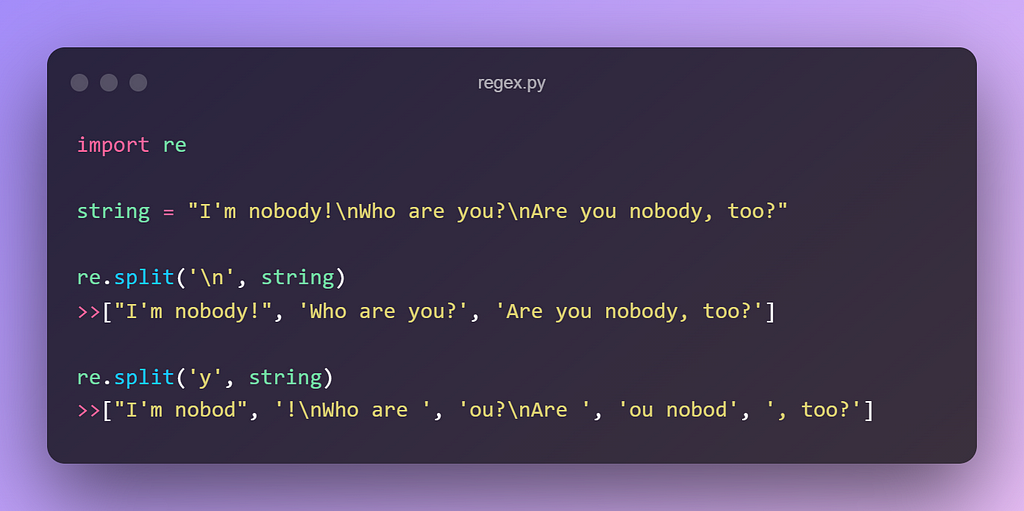
3. re.split(pattern, string, maxsplit)
This function splits the string by the occurrences of the regex pattern, thereby returning a list containing the resulting substrings. Maxplit defines the number of splits you wanted to perform.
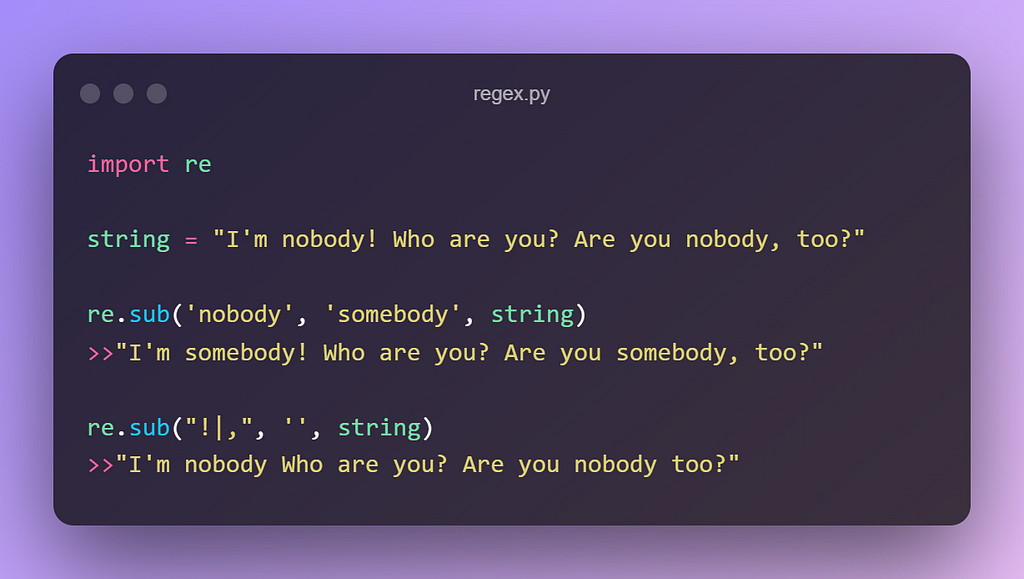
4. re.sub(pattern, repl, string)
This function searches for the pattern in the string and replaces the matched strings with the replacement repl.
Metacharacters in RegEx
Metacharacters are characters with special meanings. Metacharacters don’t match themselves. Instead, they indicate some rules. These are the metacharacters that we’ll discuss [] \ . ^ $ * + ? {} | () here 👇
1. [] - A set of characters class you wish to match. You can also specify a range of characters using - inside square brackets.
- [abc] This will match(single character) any of the characters a, b or c this is the same as [a-c].
- [1-4] is the same as [1234].
Note: You can match the characters not listed within the class by complementing the set using ^ as the first character of the class.
- [^5] will match any character except '5'.
- [5^] will match either a '5' or a '^'.
2. \ - Signals a special sequence (can also be used to escape special characters). the backslash can be followed by various characters to signal various special sequences. It’s also used to escape all the metacharacters so you can still match them in patterns.
3. . - Any character (except newline character).
4. ^ - Starts with / matches the beginning of line.
5. $ - Ends with / matches the end of line.
6. * - Zero or more occurrences of the pattern to its left(>=0).
7. + - One or more occurrences of the pattern to its left(>=0).
8. ? - Zero or one occurrences of the pattern to its left (0>= & <=1).
9. {} - Exactly the specified number of occurrences.10. | - Either or.
11. () - To group sub-patterns.
Greedy Mode:
In python RegEx quantifiers work in a greedy mode. It means that the quantifiers will try to match their preceding elements as much as possible. First the search finds the leftmost match for the pattern, and second it tries to use up as much of the string as possible — i.e. + and * go as far as possible.
The '*', '+', and '?' qualifiers are all greedy; they match as much text as possible. Sometimes this behaviour isn’t desired; if the RE <.*> is matched against '<a> b <c>', it will match the entire string, and not just '<a>'. Adding ? after the qualifier makes it perform the match in non-greedy or minimal fashion; as few characters as possible will be matched. Using the RegEx <.*?> will match only '<a>'.
Special Sequences in RegEx
The power of regular expressions is that they can specify patterns, not just fixed characters. Here are the most basic patterns which match single chars.
\d - Matches any decimal digit; this is equivalent to the class [0-9].
\D - Matches any non-digit character; this is equivalent to the class [^0-9].
\w - Matches any alphanumeric character; this is equivalent to the class [a-zA-Z0-9_].
\W - Matches any non-alphanumeric character; this is equivalent to the class [^a-zA-Z0-9_].
\s - Matches any whitespace character; this is equivalent to the class [\t\n\r\f\v].
\S - Matches any non-whitespace character; this is equivalent to the class [^ \t\n\r\f\v].
\Z - Returns a match if the specified characters are at the end of the string.
Regular expressions can be concatenated to form new regular expressions; if A and B are both regular expressions, then AB is also a regular expression. In general, if a string p matches A and another string q matches B, the string pq will match AB.
Let’s test out our concepts by doing some examples:
1. Grab Numbers from text
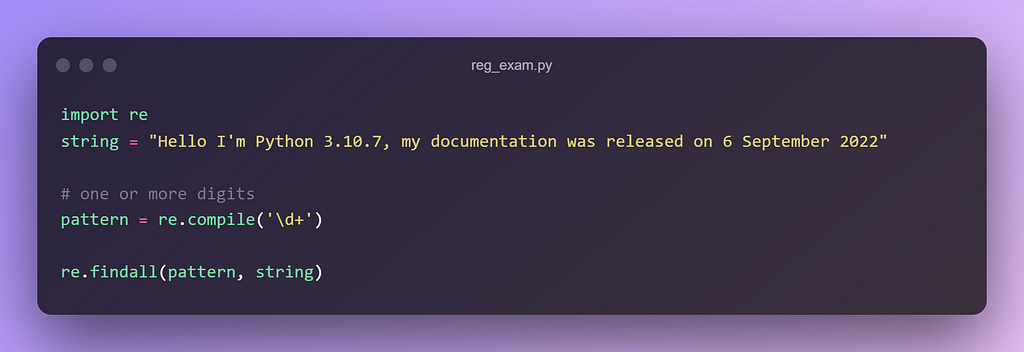
It generates the following output 👇
['3', '10', '7', '6', '2022']
2. Grab Phone Number (US Domestic format XXX-XXX-XXXX)
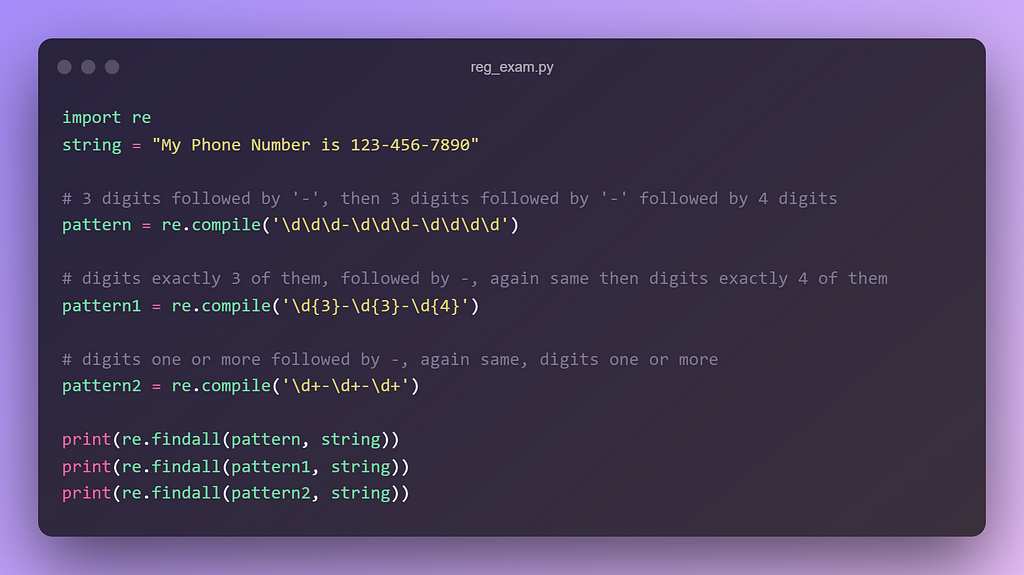
All three returns the same output, but which approach do you think is the best among three? When you know what you are looking for then it’s best practice is to define the exact same pattern so that you have more control over it. Here, pattern & pattern1 gives you more control compared to pattern2 as it can fetch more digits than 3 due to it’s greedy nature.
['123-456-7890']
['123-456-7890']
['123-456-7890']
That’s the beauty of RegEx there are many ways to do a thing. You just need to think 🧠!!!
3. Grab emails from text
Let’s generate some really genuine emails here 👻
Optimus_prime@gmail.com
Harry.Potter@hogwarts.ac.in
Bond_007@bond.net
temp1234@fake.in
temp-1234@fake.in
Our immediate intuition will be 👉 Some characters (one or more), followed by @ then some domain, & we’ll end up generating something like this 👇
‘\w+@\w+.\w+’
will this work? As discussed above \w grabs alphanumeric characters so it won’t be able to detect any ‘-’ or ‘.’
['Optimus_prime@gmail.com',
'Potter@hogwarts.ac',
'Bond_007@bond.net',
'temp1234@fake.in',
'1234@fake.in']
So let’s customize our pattern so that it grabs the complete email address
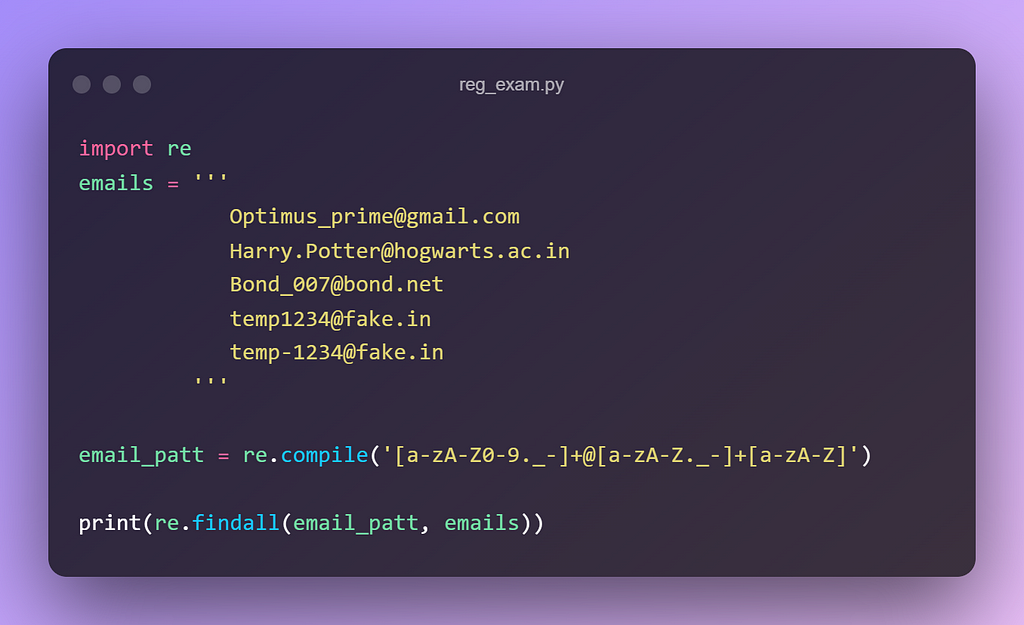
Now we get the following results:
['Optimus_prime@gmail.com', 'Harry.Potter@hogwarts.ac.in', 'Bond_007@bond.net', 'temp1234@fake.in', 'temp-1234@fake.in']
These were some very basic yet very frequently used concepts in dealing with NLP problems. For finding one pattern there can be multiple RegEx expressions and there is a lot more. We just scratched the surface of it.
You can checkout the RegEx repository here, where i’ll update the notebooks with more examples.
Congratulations 👏!!! Now we know something about RegEx & I hope this Ex will be very useful 😝.
I will try to bring up more Machine learning/Data science concepts and will try to break down fancy-sounding terms and concepts into simpler ones.
I hope you enjoyed this article! You can follow me Afaque Umer for more such articles.
Thanks for reading 🙏
Keep learning 🧠 Keep Sharing 🤝 Stay Awesome 🤘
RegEx — The only Ex you need to Remember !! was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Afaque Umer
Afaque Umer | Sciencx (2022-10-06T14:52:19+00:00) RegEx — The only Ex you need to Remember !!. Retrieved from https://www.scien.cx/2022/10/06/regex-the-only-ex-you-need-to-remember/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.