
This content originally appeared on DEV Community 👩💻👨💻 and was authored by Asiqur Rahman
Prerequisites: Python fundamentals
Versions: Python 3.10, python-dotenv 0.21.0, openai 0.23.0
Read Time: 60 minutes
Introduction
Artificial Intelligence (AI) is becoming the next big technology to harness. From smart fridges to self-driving cars, AI is implemented in almost everything you can think of. So let's get ahead of the pack and learn how we can leverage the power of AI with Python and OpenAI.
In this tutorial, we'll learn how to create a blog generator with GPT-3, an AI model provided by OpenAI. The generator will read a topic to talk about as the input, and GPT-3 will return us a paragraph about that topic as the output.
So AI will be "writing" stuff for us. Say goodbye to writer's block!
But wait, hold on! Artificial intelligence?! AI models?! This must be complicated to code. 😵

Nope, it's easier than you think. It takes around 25 lines of Python code!
The final result will look something like this:
Who knows, maybe this entire project was written by the generator we're about to create. 👀
What is GPT-3?
GPT-3 is an AI model released by OpenAI in 2020. An AI model is a program trained on a bunch of data to perform a specific task. In this case, GPT-3 was trained to speak like a human and predict what comes next given the context of a sentence, with its training dataset being 45 terabytes of text (!) from the internet.
For reference, if you had to keep writing until your paper hits 45 terabytes in size, you would have to write 22,500,000,000 pages worth of plain text.
Since GPT-3 was trained on internet data, it knows what the internet knows (not everything of course). This means that if we were to give GPT-3 a sentence, it would be able to predict what comes next in that sentence with high accuracy, based on all the text that was used to train it.
Now we know what we'll be working with, let's build the program!
Setting Up
OpenAI Account
Before we do anything, we need an OpenAI account. We'll need this account access to an API key that we can use to work with GPT-3.
API (Application Programming Interface) is a way for two computers to communicate with each other. Think of it like two friends texting back and forth. An API key is a code we receive to access the API. Think of it like an important password, so don’t share it with others!
Go to www.openai.com and sign up for an OpenAI account.
After you've created an account, click on your profile picture on the top right, then click "View API keys" to access your API key. You should see this page and it should look like:

Now that we know where the API key is located, let's keep it in mind for later.
With the API key, we get access to GPT-3 and \$18 worth of free credit. Meaning that we can use GPT-3 for free until we go over the \$18, which is more than enough to complete this project.
Python Setup
For this project, we'll need Python 3 and pip (package installer) installed.
Assuming that we have those two installed, let's open up the code editor of our choice (we recommend VS Code) and create a new file called blog_generator.py.
Note: You can name this file anything except for openai.py, since the name will clash with a package we'll be installing.
Beginning the Project
At the core of this project, all we'll be doing is sending data with instructions to a server owned by OpenAI, then receiving a response back from that server and displaying it.
Install openai
We'll be interacting with GPT-3 model using a python package called openai. This package consists of methods that can connect to the internet and grant us access to the GPT-3 model hosted by OpenAI, the company.
To install openai, all we have to do is run the following command in our terminal:
pip install openai
We can now use this package by importing it into our blog_generator.py file like so:
import openai
Authorize API Key
Before we can work with GPT-3 we need to set our API key in the openai module. Remember, the API key is what gives us access to GPT-3; it authorizes us and says we're allowed to use this API.
We can set our API key by extending a method in the openai module called api_key:
openai.api_key = 'Your_API_Key'
The method will take in the API key as a string. Remember, your API key is located in your OpenAI account.
So far, the code should look like this:
import openai
openai.api_key = 'sk-jAjqdWoqZLGsh7nXf5i8T3BlbkFJ9CYRk' # Fill in your own key
The Core Function
Now that we have access to GPT-3, we can get to the meat of the application, which is creating a function that takes in a prompt as user input and returns a paragraph about that prompt.
That function will look like this:
def generate_blog(paragraph_topic):
response = openai.Completion.create(
model = 'text-davinci-002',
prompt = 'Write a paragraph about the following topic. ' + paragraph_topic,
max_tokens = 400,
temperature = 0.3
)
retrieve_blog = response.choices[0].text
return retrieve_blog
Let's break down this function and see what's going on here.
First, we defined a function called generate_blog(). There's a single parameter called paragraph_topic, which will be the topic used to generate the paragraph:
def generate_blog(paragraph_topic):
# The code inside
And let's go inside the function. Here's the first part:
def generate_blog(paragraph_topic):
response = openai.Completion.create(
model = 'text-davinci-002',
prompt = 'Write a paragraph about the following topic. ' + paragraph_topic,
max_tokens = 400,
temperature = 0.3
)
This is the bulk of our function and where we use GPT-3. We created a variable called response to store the response generated by the output of the Completion.create() method call in our openai module.
GPT-3 has different endpoints for specific purposes, but for our goal, we'll use the completion endpoint. The completion endpoint will generate text depending on the provided prompt. You can read about the different endpoints in the documentation.
Now that we have access to the completion endpoint, we need to specify a few things, The first one being:
model: The model parameter will take in the model we want to use. GPT-3 has four models that we can use:
text-davinci-002text-curie-001text-babbage-001text-ada-001
These models perform the same task but at a different power level. More power equals better and more coherent responses, with text-davinci-002 being the most powerful and text-babbage-001 being the least. You can think of it like a car vs. a bike. They both perform the same task of taking you from one place to another, but the car will perform better. You can read more about the models in the documentation.
prompt = 'Write a paragraph about the following topic. ' + paragraph_topic,
prompt: This is where we design the main instructions for GPT-3. This parameter will take in our paragraph_topic argument, but before that, we can tell GPT-3 what to do with that argument. Currently, we are instructing GPT-3 to Write a paragraph about the following topic. GPT-3 will try its best to follow this instruction and return us a paragraph.
GPT-3 is very flexible; if the initial string is changed to Write a blog outline about the following topic, it will give us an outline instead of a normal paragraph. You can later play around with this by telling the model exactly what it should generate and seeing what interesting responses you get.
max_tokens = 400
tokens: The token number decides how long the response is going to be. A larger token number will produce a longer response. By setting a specific number, we're saying that the response can't go past this token size. The way tokens are counted towards a response is a bit complex, but you can read this article by OpenAI that explains how token size is calculated.
Roughly 75 words is about 100 tokens. A paragraph has 300 words on average. So, 400 tokens is about the length of a normal paragraph. The model text-davinci-002 has a token limit of 4,000.
temperature = 0.3
temperature: Temperature determines the randomness of a response. A higher temperature will produce a more creative response, while a lower temperature will produce a more well-defined response.
-
0: The same response every time. -
1: A different response every time, even if it's the same prompt.
There are plenty of other fields that we can specify to fine-tune the model even more, which you can read in the documentation, but for now, these are the four fields we need to concern ourselves with.
Now that we have our model setup, we can run our function, and the following things will happen:
- First, the
openaimodule will take our API key, along with the fields we specified in theresponsevariable, and make a request to the completion endpoint. - OpenAI will then verify that we're allowed to use GPT-3 by verifying our API key.
- After verification, GPT-3 will use the specified fields to produce a response.
- The produced response will be returned back in the form of an object and stored in the
responsevariable.
That returned object will look like this:
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": "\n\nPython is a programming language with many features, such as an intuitive syntax and powerful data structures. It was created in the late 1980s by Guido van Rossum, with the goal of providing a simple yet powerful scripting language. Python has since become one of the most popular programming languages, with a wide range of applications in fields such as web development, scientific computing, and artificial intelligence."
}
],
"created": 1664302504,
"id": "cmpl-5v9OiMOjRyoyypRQWAdpyAtjtgVev",
"model": "text-davinci-002",
"object": "text_completion",
"usage": {
"completion_tokens": 80,
"prompt_tokens": 19,
"total_tokens": 99
}
}
We’re provided with tons of information about the response, but the only thing we care about is the text field containing generated text.
We can access the value in the text field like so:
retrieve_blog = response.choices[0].text
Finally, we return the retrieve_blog variable which holds the paragraph we just dug out of the dictionary.
return retrieve_blog
Whoah! Let's take a moment and breathe. That was a lot we just covered. Let's give ourselves a pat on the back as we're 90% done with the application.
We can test to see if our code works so far by printing out the generate_blog() function we just created, giving it a topic to write about, and seeing the response we get.
print(generate_blog('Why NYC is better than your city.'))
Here's the complete code so far:
import openai
openai.api_key = 'sk-jAjqdWoqZLGsh7nXf5i8T3BlbkFJ9CYRk' # Fill in your own key
def generate_blog(paragraph_topic):
response = openai.Completion.create(
model = 'text-davinci-002',
prompt = 'Write a paragraph about the following topic. ' + paragraph_topic,
max_tokens = 400,
temperature = 0.3
)
retrieve_blog = response.choices[0].text
return retrieve_blog
print(generate_blog('Why NYC is better than your city.'))
And boom, after 2-3 seconds, it should spit out a paragraph like this:

Try running the code a couple more times; the output should be different every time! 🤯
Multiple Paragraphs
Right now, if we run our code, we'll only be able to generate one paragraph worth of text. Remember, we're trying to create a blog generator, and a blog has multiple sections, with each paragraph having a different topic.
Let's add some additional code to generate as many paragraphs as we want, with each paragraph discussing a different topic:
keep_writing = True
while keep_writing:
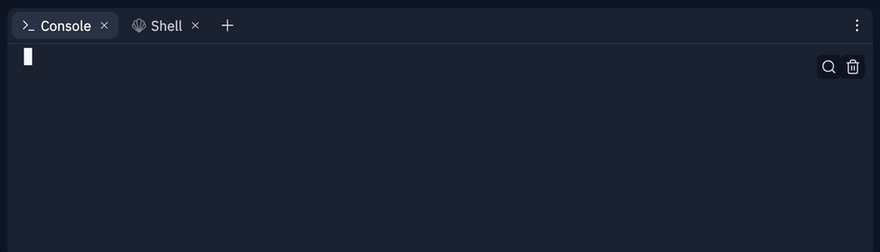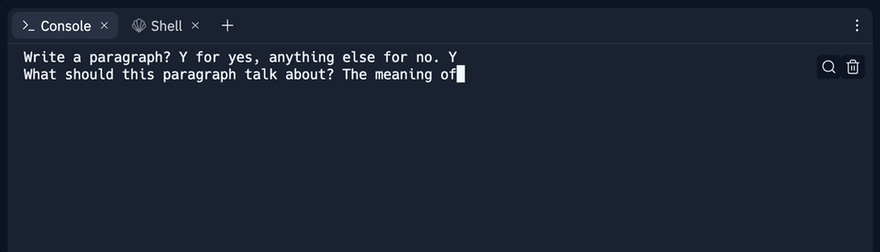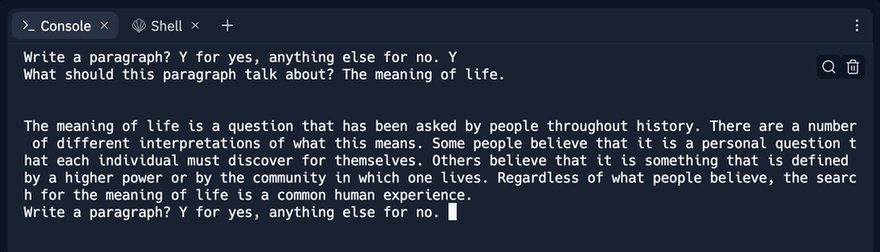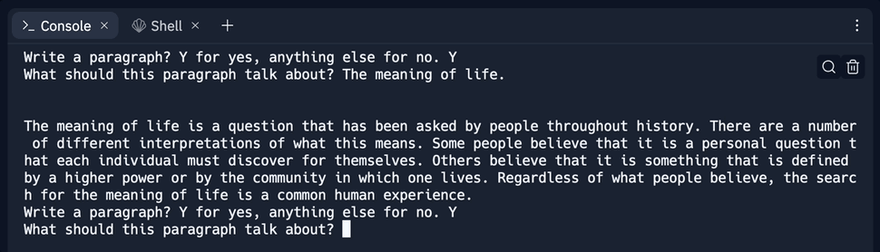
answer = input('Write a paragraph? Y for yes, anything else for no. ')
if (answer == 'Y'):
paragraph_topic = input('What should this paragraph talk about? ')
print(generate_blog(paragraph_topic))
else:
keep_writing = False
First, we defined a variable called keep_writing, to use as a boolean value for the following while loop.
In the while loop, we created an answer variable that will take in an input from the user using the built-in input() function.
We then created an if statement that will either continue the loop or stop the loop.
- If the input from the user is
Y, then we will ask the user what topic they want to generate text about, storing that value in a variable calledparagraph_topic. Then we will execute and print thegenerate_blog()function using theparapgraph_topicvariable as its argument. - Else, we will stop the loop by assigning the
keep_writingvariable toFalse.
With that complete, we can now write as many paragraphs as we want by running the program once!
Rate Limit
Since we're using a while loop, we have the potential to be rate limited.
Rate limit is the number of API calls an app or user can make within a given time period.
This is normally done to protect the API from abuse or DoS attacks.
For GPT-3, the rate limit is 20 requests per minute. As long as we don't run the function that fast, we'll be fine. But in a rare case that it does occur, GPT-3 will stop producing responses and make us wait a minute to produce another response.
Credit Limit
By this point, if you have been playing with the API nonstop, there's a chance that you might have exceeded the $18 limit. The following error is thrown when that happens:
openai.error.RateLimitError:
You exceeded your current quota, please check your plan and billing details.
If that's the case, go to OpenAI's Billing overview page and create a paid account.
Let's take another breather. We're almost done!
Securing Our App
Let's think about this for a minute. We created this amazing application and want to share it with the world, right? Well, when we deploy it to the web or share it with our friends, they'll be able to see every piece of code in the program. That's where the issue lies!
At the beginning of this article, we created an account with OpenAI and were assigned an API key. Remember, this API key is what gives us access to GPT-3. Since GPT-3 is a paid service, the API key is also used to track usage and charge us accordingly. So what happens when someone knows our API key? They'll be able to use the service with our key, and we'll be the one charged, potentially thousands of dollars!
In order to protect ourselves, we need to hide the API key in our code but still be able to use it. Let's see how we can do that.
Install python-dotenv
python-dotenv is a package that allows us to create and use environment variables without having to set them in the operating system manually.
Environment variables are variables whose values are set outside the program, typically in the operating system.
We can install python-dotenv by running the following command in the terminal:
pip install python-dotenv
.env File
Then in our project's root directory, create a file called .env. This file will hold our environment variable.
Open up the .env file and create a variable like so:
API_KEY=<Your_API_Key>
The variable will take in our API key without any quotation marks or spaces. Remember to name this variable as API_KEY only.
Python File
Now that we have our environment variable set, let's open up the blog_generator.py file, and paste this code under import openai.
from dotenv import dotenv_values
config = dotenv_values(".env")
First, we've imported a method called dotenv_values from the module.
The dotenv_values() will take in the path to the .env file and return us a dictionary with all the variables in the .env file. We then created a config variable to hold that dictionary.
Now, all we have to do is replace the exposed API key with the environment variable in the config dictionary like so:
openai.api_key = config['API_KEY']
That's it! Our API key is now safe and hidden from the main code.
Note: If you want to push your code to GitHub, you don't want to push the .env file as well. In the root directory of your project, create a file called .gitignore, and in the Git ignore file, type in .env. This will prevent the file from being tracked by Git and ultimately pushed to GitHub.
With all that set and done, we’re finished! The code should now look like this!
blog_generator.py file:
# Generate a Blog with OpenAI 📝
import openai
from dotenv import dotenv_values
config = dotenv_values('.env')
openai.api_key = config['API_KEY']
def generate_blog(paragraph_topic):
response = openai.Completion.create(
model = 'text-davinci-002',
prompt = 'Write a paragraph about the following topic. ' + paragraph_topic,
max_tokens = 400,
temperature = 0.3
)
retrieve_blog = response.choices[0].text
return retrieve_blog
keep_writing = True
while keep_writing:
answer = input('Write a paragraph? Y for yes, anything else for no. ')
if (answer == 'Y'):
paragraph_topic = input('What should this paragraph talk about? ')
print(generate_blog(paragraph_topic))
else:
keep_writing = False
.env file:
API_KEY=sk-jAjqdWoqZLGsh7nXf5i8T3BlbkFJ9CYRk
Finish Line
Congrats, you just created a blog generator with OpenAI and Python! Throughout the project, we learned how to use GPT-3 to generate a paragraph, use a while loop to create multiple paragraphs, and secure our app with a .env file. 🙌
AI is expanding rapidly, and the first few to utilize it properly through services like GPT-3 will become the inovators in the field. Hope this project helps you understand it a bit more.
And lastly, we would love to see what you build with this tutorial! Tag @codedex_io and @openai on Twitter if you make something cool!
More Resources
This content originally appeared on DEV Community 👩💻👨💻 and was authored by Asiqur Rahman
Asiqur Rahman | Sciencx (2022-10-19T20:06:42+00:00) Generate a Blog with OpenAI. Retrieved from https://www.scien.cx/2022/10/19/generate-a-blog-with-openai/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.