
This content originally appeared on DEV Community 👩💻👨💻 and was authored by Vikas Solegaonkar
Search is a growing necessity for all applications. As data accumulates at a high volume and velocity, it is important that the rest of our data pipeline is capable of extracting the right information and insights from this data. Search is one of the primary tools for that.
Despite the multimedia revolution, a lot of data we collect is in the form of text. This can be social media feeds, web crawler extracts, consumer reviews, medical reports, streaming geo-location updates, and many more. Gone are the days of searches based on a case-sensitive exact string match. We need a system that can manage text at scale to process this data. We need to run superfast fuzzy queries on the text.
RediSearch provides a wonderful solution for that. We can process streaming as well as static data. Besides fuzzy text search, RediSearch enables complex search on numeric and geolocation data. And, of course, we can take the basic tag searches for granted.
This blog covers the core concepts of RediSearch, along with code snippets to demonstrate the concept.
Core concepts
Syntax alone is not enough. To make the best use of any tool, it helps if we understand how it works under the hood. For that, let us start off with some core concepts.
Inverted Index
RediSearch is based on the concept of an inverted index. It maintains an inverted index for everything that appears in the data. That means for every indexed entity we add to the RedisDB, RediSearch extracts all the individual values and adds entries into the index structure. These entries contain inverted mapping that maps the searchable value to the original key. Thus, we can map any entity in the data to the key for that object in the Redis DB.
Efficient search has two steps. The first step is to identify the value that the user is trying to search for. Having identified the value, the second step is to get the key that refers to the object containing the value we identified. An inverted index helps us with the second step. Once we identify the value that the user wants to search for, we can jump to the key without any delay. Let us now check the first step.
Trie – Secret behind the speed
Trie (digital search tree/prefix tree) is a data structure that can enable fast retrieval on large data sets. The term “trie” comes from the phrase ‘Information Re*trie*val’. In simple words, trie organizes text data into a tree built out of the prefixes. What does that mean?
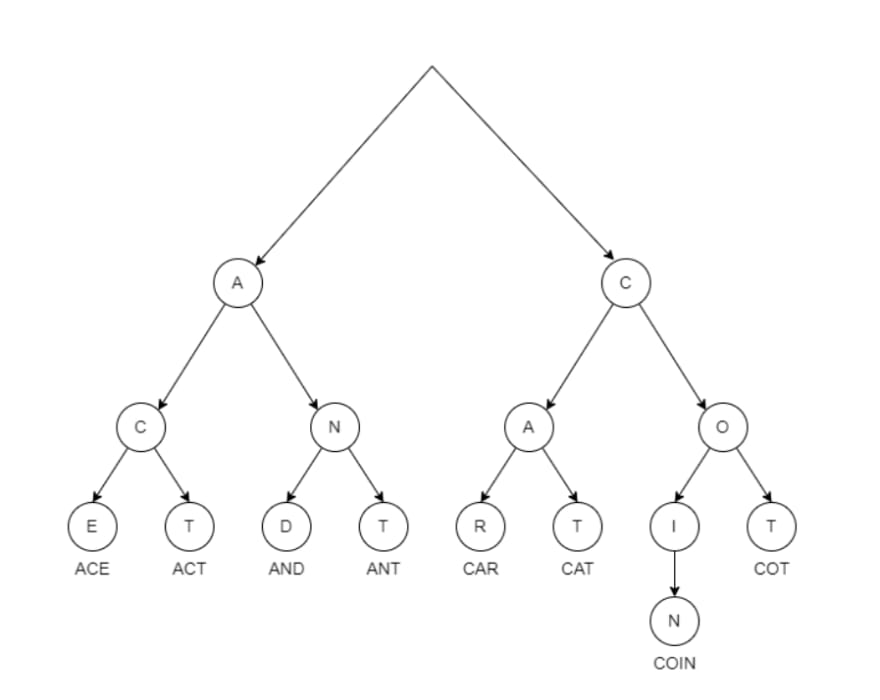
As the name suggests, a prefix tree builds a tree of prefixes. Now, what does that mean? Any string can be considered a sequence of prefixes. If we index text corpus using such a prefix tree, we can locate any node using direct traversal into the tree – not by counting or scanning. Because of this, the time complexity of locating any word is independent of the volume of data. At the same time, the complexity of absorbing new data is low as well.
That enables scalable and superfast searches on large volumes of data.
RediSearch takes this a step further. The tree need not be implemented with single characters directly extracted from the raw text. We can be smarter when we build the prefix tree. It can be built using a lemma extracted from the text. When we create such a smart index, we can implement superfast fuzzy search on a huge volume of data. That is the secret behind the efficiency of RediSearch text queries. For more information on implementing fuzzy search, refer to this Wikipedia article.
Tag Index
The tag search is meant to be faster than a full-featured text search. We use tag index when we know the field contains the specific text we query directly. We use it on fields where we do not require a fuzzy search. Tag search can afford a simpler index.
Numeric Index
RediSearch defines a special index structure for numeric data. Numeric queries are often based on a computational range. An index based on distinct values cannot help such queries. We need something better. Instead of treating each number as an independent entity, we should index them in a way that recognizes numbers in relation to their values.
RediSearch achieves this by creating a Numeric index based on binary range trees. Such index groups together numbers that are closer to each other. Thus, in the numeric index tree, such groups are stored on “range nodes” instead of having one number per node. This is easier said than done. How do we identify the size of a node? How do we define the threshold of closeness for numbers that can be packed into one node? RediSearch has an adaptive algorithm that implements such grouping and classification of numbers into groups.
Geo Index
Over the years, mobile phones/IoT devices and their geo-location have become a significant component of data flowing into our database. With an increased load of geospatial data, the performance of geospatial queries is an important component of database performance. Naturally, RediSearch does its best to address this domain.
RediSearch has geo-indexing based on the closeness between points. This closeness is identified based on the distance calculated by the geospatial queries. The points are then collected into range trees that enable fast search and grouping.
Scoring
A search query may return several results. We do not want to overwhelm the client with tons of data. It makes sense to order the data based on some score so that the client can choose to take what is more relevant than the rest of the result set. Scoring is different from sorting. Sorting is simply based on the absolute value of the content of the field. The score is a measure of the relevance of each value of the search result.
Such scores can be calculated using predefined functions in RediSearch or custom functions that boost the score of part of the result.
Setup
Let us now work on setting up the database and tools required for using Redis.
Installing Redis
Don’t install!
Gone are the days when we developed and tested our code with databases installed on our laptops. Welcome to the cloud. All you need is a few clicks, and the free database instance is ready for you. Why clutter your laptop?
- Jump to the Redis cloud. If you don’t have an account, create one in less than a minute.
- Signup with Google/GitHub if you don’t want to remember too many passwords.
- Once you log in, click on Create subscription. Then accept all the defaults to create a new free subscription based on AWS, hosted in the us-east-1 region.
- Once you have the subscription, click “New database” to create a database instance.
- Again, accept all the defaults and click on “Activate database”.
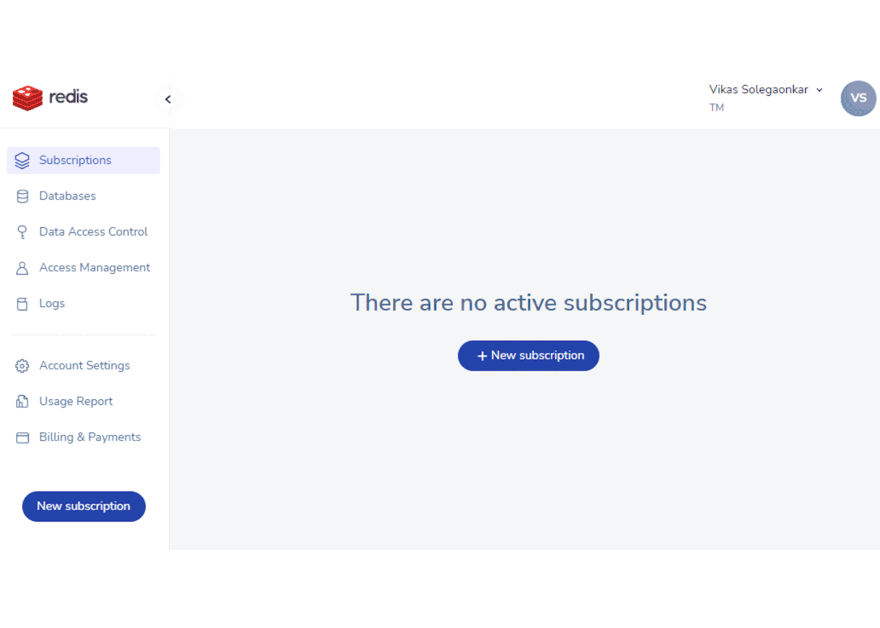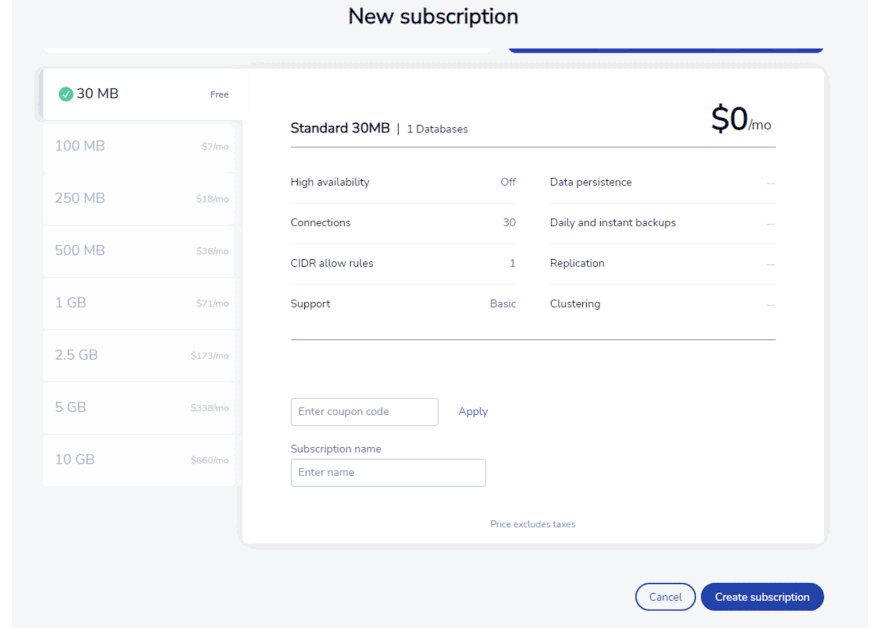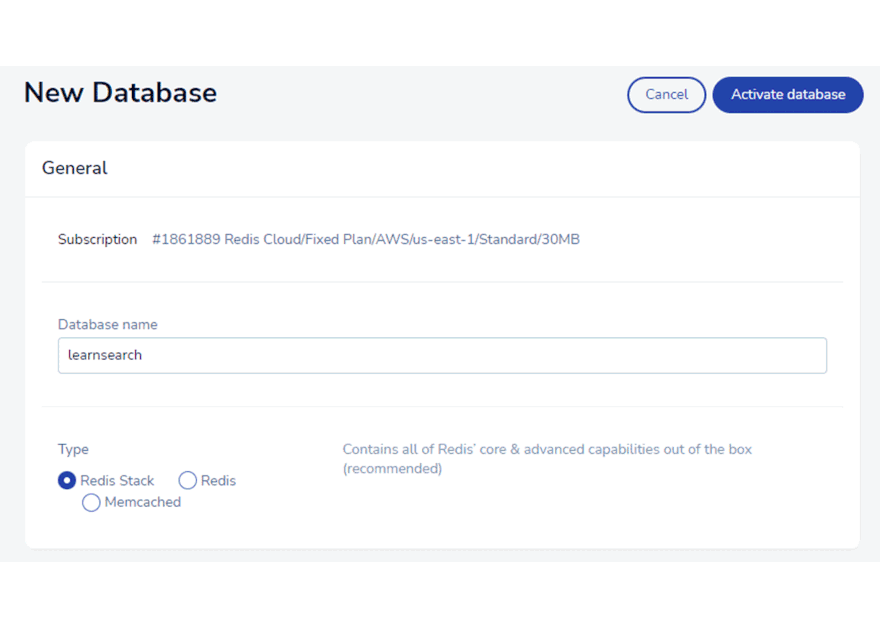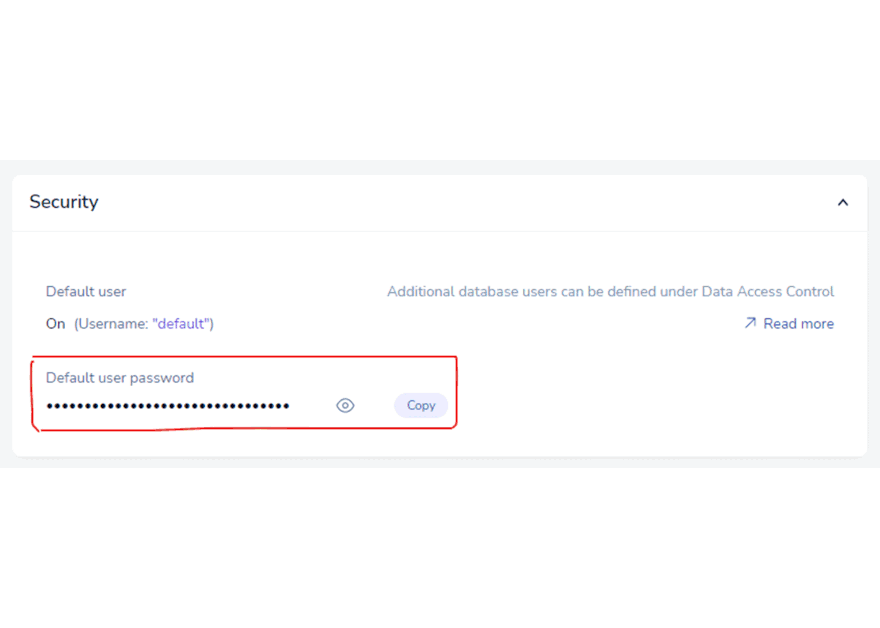
- Give it a few minutes to set up. And there, the database is waiting for you to start learning. Just note the database URL.
- Also, note the database password. Copy to a notepad. Then log out of the web console.
Redis Insights
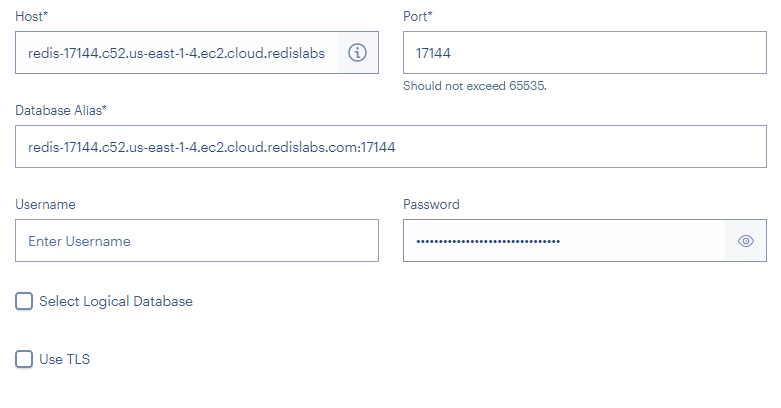
This is a must-have tool for working with Redis. You can download it from this link. The installation and setup are simple. Click ADD REDIS DATABASE to configure a new connection and provide the database details you picked in the above steps.
Show me code
Did you have an overdose of theory? Let us now taste some code that can help us apply some concepts. This example focuses on the text search. Redis provides us with a straightforward command line interface, along with useful SDK modules in most common languages.
Below is a JavaScript code that uses Node Redis module to communicate with the Redis Server. Along with the JavaScript code, we can see the corresponding CLI commands. We need a text-rich dataset to save in our database and demonstrate the search functionality. For this, we will use a dump of poems obtained from Kaggle. The JSON chunk can be found on this link.
Code
With the database ready, let us check the code in detail. You can find the complete source code in this GitHub repository. Clone that repository locally. You will need NodeJS to run this code. Once the code is ready, open the file config/default.json. Update the file to include the Redis URL and password we got while creating the database.
Now, a quick view of the JavaScript code. Check out the app.js
Imports
Like any other JavaScript code, we start with the imports
const express = require("express");
const redis = require("redis");
const axios = require("axios");
const md5 = require("md5");
const config = require("config");
Redis Client
Instantiate the client to connect with the Redis database
const client = redis.createClient(config.redis);
client.on("error", (err) => console.log("Redis Client Error", err));
await client.connect().then((e) => console.log("Connected"))
.catch((e) => console.log("Not connected"));
Load Data
Next, we pull the poem data from the internet and load it into the database
var promiseList = list.map((poem, i) =>
Promise.all(Object.keys(poem).map((key) => client.hSet(`poem:${md5(i)}`, key, poem[key])))
);
await Promise.all(promiseList);
Create Index
With the data in our database, we proceed to create the index. This completes the database setup. Note here, that we have some TEXT indexes and some TAG indexes. The poetry age and type have a TAG index, because we do not expect complex queries around them.
await client.ft.create(
"idx:poems",
{
content: redis.SchemaFieldTypes.TEXT,
author: redis.SchemaFieldTypes.TEXT,
title: { type: redis.SchemaFieldTypes.TEXT, sortable: true },
age: redis.SchemaFieldTypes.TAG,
type: redis.SchemaFieldTypes.TAG,
},
{
ON: "HASH",
PREFIX: "poem:",
}
);
The same can be done in Redis CLI using
FT.CREATE idx:poems ON HASH PREFIX 1 poem: SCHEMA content TEXT author TEXT title TEXT SORTABLE age TAG type TAG
Author API
With the database setup, we start with the express server. After instantiating the express app, we create the first API that can search for poems based on the author. Note that it is a regular expression. So, it will fetch any author name that matches the expression. Moreover, the search is case-insensitive.
app.get("/author/:author", function (req, res) {
client.ft.search("idx:poems", `@author: /${req.params.author}/`)
.then((result) => res.send(result.documents));
});
Try invoking the API with http://127.0.0.1:3000/author/william
It will fetch all the poems written by authors with William in their name.
The same can be achieved by the CLI
FT.SEARCH idx:poems "@author:/william/"
Fuzzy Search API
The example shows another search capability, which is the fuzzy search. Note the % sign in the search expression. This signifies the fuzzy search. Now, the search will also match similar words.
app.get("/fuzzy/:text", function (req, res) {
client.ft.search("idx:poems", `%${req.params.text}%`)
.then((result) => res.send(result.documents));
});
Try to invoke the API with http://127.0.0.1:3000/fuzzy/speak
It will fetch poems containing a word similar to speak. The same can be achieved by the CLI
FT.SEARCH idx:poems "%speak%"
More Information
This was just a glimpse of the potential of RediSearch. To understand further details, check out
- Enterprise Redis
- Redis for Developers
This post is in collaboration with Redis
This content originally appeared on DEV Community 👩💻👨💻 and was authored by Vikas Solegaonkar
Vikas Solegaonkar | Sciencx (2022-10-20T05:05:35+00:00) Superfast search with RediSearch. Retrieved from https://www.scien.cx/2022/10/20/superfast-search-with-redisearch/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.