
This content originally appeared on DEV Community 👩💻👨💻 and was authored by Kunal Desai
Discord is becoming a popular platform for open source projects and companies to manage their developer communities. These Discord servers are where developers can go to get their questions answered quickly. Some support channels are extremely busy with the same questions being asked and answered over and over again. I figured that answering these questions might be something that GPT-3 could do really well! So I decided to spend a couple hours to build the bot - this article talks about how the bot was built. If you want to add the Discord bot to your server, use this URL. I’d also like to thank writethrough.io for helping me write this article.
The Tech Stack?
I decided to use Python to build this bot since neural nets are involved and Python has great libraries like PyTorch for neural nets. I also used the discord.py library to make it easy to interact with the Discord API. To deploy the bot, I created a small GCP Compute Engine instance, Prisma, PostgresDB, and Pinecone.
Setting up the Discord Bot
The first thing I needed to do to create this bot was to create a Discord account and application. You can do that here. Under Settings on the left navbar, click Bot and then hit Add Bot.
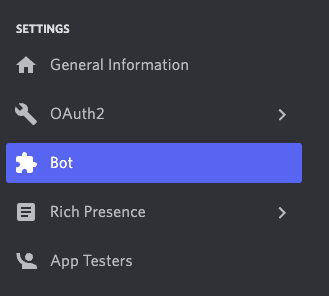
Set the name and icon of your bot to something fun! Next, you’ll need to generate a token for your bot by hitting Reset Token. Save this token somewhere private because we’ll need it in a bit. Additionally, you’ll need to turn on the Message Content Intent for your Discord bot which is further down the Bot page.

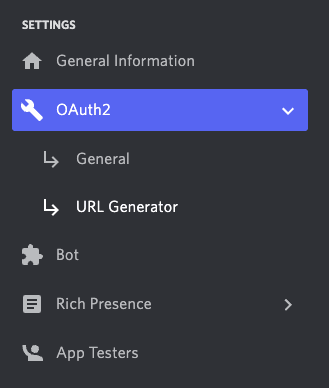
This will allow your bot to read the contents inside the messages. Finally, you’re going to add the Discord bot to your Discord server so you can start testing things. Go back to the Settings on the left navbar, click OAuth2 and click URL Generator in the submenu.
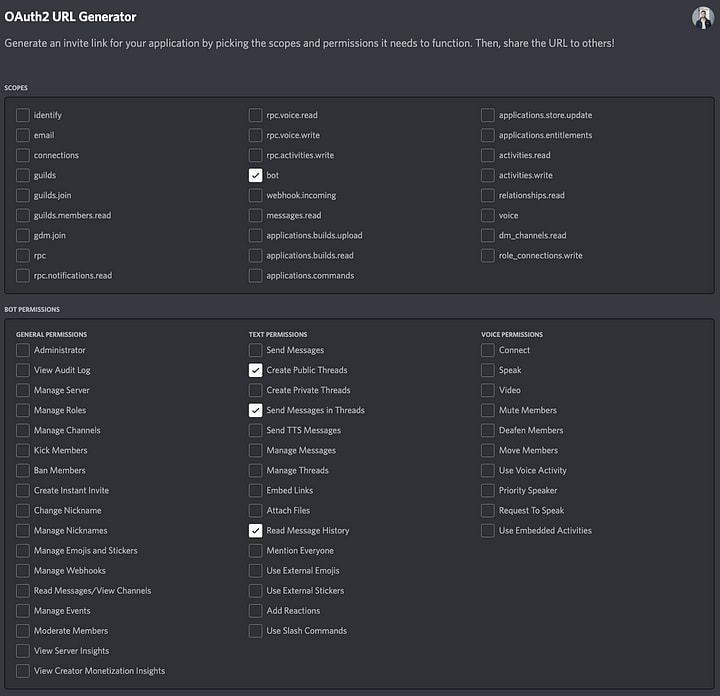
In this step, we’re generating the URL that’s going to allow anyone to add the bot to any server with the correct permissions. We’re going to add the bot scope and Send Messages, Create Public Threads, and Read Message History bot permissions. On the bottom of the page, it will have generated a URL, copy that URL and navigate to it. Follow the steps to add your bot to your server.
Setting up the environment for our Python Bot
The next thing we need to do is to set up the functionality for our bot! We’ll set up our Python bot with some good software hygiene. The only pre-requisites are that you have Python and pip installed.
First, install virtualenv package with python -m pip install virtualenv. This package will help us create a virtual environment with a Python instance that’s local to our repository. That way our environment is reproducible and we don’t mess with the system Python.
Why python -m pip install virtualenv and not just pip install virtualenv? The former ensures that we install virtualenv in the correct Python installation.
Once virtualenv is installed, we’ll create our project folder and virtual environment with mkdir discord-bot , cd discord-bot, and python -m virtualenv venv. This will create a folder in our project directory called venv. To activate the virtual environment, run source venv/bin/activate. Now, if you type which python, it should point to an installation of Python inside discord-bot/venv/bin/.
Reading messages from your Discord server
Now, create the bot.py file where we will write the code for the Discord bot. First, we’ll install the discord Python client with pip install discord.py. Next, we’ll set up the scaffolding for our Discord bot in bot.py:
import discord
class Client(discord.Client):
async def on_ready(self):
print(f'{self.user} has connected to Discord!')
async def on_message(self, message: discord.Message):
print(message.content)
intents = discord.Intents.default()
intents.message_content = True
client = Client(intents=intents)
client.run('<TOKEN_HERE>')
Replace <TOKEN_HERE> with your Discord bot token from the steps above. This code creates the Discord bot and prints the contents of the Discord message whenever a message is sent in your Discord server. Give it a shot! Run python bot.py to run your bot, then start sending some Discord messages and watch the logs of your bot.
Saving Discord Messages to a Database
Next, we’ll need to start saving our messages to a database so that we can query for them later. For this step, we’re going to use a Postgres database and interact with it using the Python Prisma Client. If you haven’t heard of Prisma, I’d highly recommend checking it out for Node.js projects! It’s amazing. The community has built a version for Python and I wanted to try it out.
Run pip install prisma to get the Python Prisma CLI and library. Next, create a schema.prisma file with the contents:
generator client {
provider = "prisma-client-py"
interface = "sync"
recursive_type_depth = 5
}
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
model DiscordMessage {
id String @id @default(cuid())
channelId String
guildId String
discordId String @unique
isThread Boolean
content String
position Int
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
}
The important part here is the model section which specifies a table in our Postgres database (which we’re about to set up!). If you’re on MacOS, here is a good guide on starting an instance of Postgres: https://www.robinwieruch.de/postgres-sql-macos-setup/.
Once you’ve gotten your Postgres database set up, you’ll need to identify your DATABASE_URL. It’ll usually be something along the lines of postgresql://<username>@localhost:5432/discord (where username is usually the output of whoami when typed in the terminal). Create the discord database by running psql <DATABASE_URL> and typing in CREATE DATABASE discord.
Next, we’re going to set up our Prisma Python client by running prisma generate --schema=schema.prisma. Additionally, we’re going to migrate our database to include the schema defined in schema.prisma by running DATABASE_URL=<DATABASE_URL> prisma migrate dev.
Now that the database is set up properly and we’ve generated our Python client to interact with the database, lets actually save the messages to a database:
import discord
from prisma import Prisma
db = Prisma()
db.connect()
class Client(discord.Client):
async def on_ready(self):
print(f'{self.user} has connected to Discord!')
async def on_message(self, message: discord.Message):
is_thread = message.channel.type == discord.ChannelType.public_thread
discord_message = db.discordmessage.create(data={
'channelId': str(message.channel.id),
'guildId': str(message.guild.id),
'discordId': str(message.id),
'isThread': is_thread,
'content': message.content,
'position': message.channel.message_count if is_thread else message.channel.position or 0,
})
intents = discord.Intents.default()
intents.message_content = True
client = Client(intents=intents)
client.run('<TOKEN_HERE>')
Run the bot with DATABASE_URL=<DATABASE_URL> python bot.py. It’ll become clear why these fields are necessary later down the tutorial. You can verify that the messages are being saved correctly by hopping into a psql session and querying the "DiscordMessage" table.
Using AI to Answer Questions
This step, in my opinion, is the most exciting step. We’re going to take the messages, and if they’re a question, then respond to them automatically if our AI can. OpenAI provides a GPT-3 model called Davinci which can help us answer questions given a prompt. I’d encourage you to play around with it so you can get a better understanding of it: https://beta.openai.com/playground.
The first thing we’re going to do is integrate OpenAI into our bot. You’ll need to create an OpenAI account and generate an API key here: https://beta.openai.com/account/api-keys. Remember to keep it a secret!
Here is the code to integrate OpenAI’s GPT-3 Completion model:
import discord
from prisma import Prisma
import openai
openai.api_key = "<API_KEY>"
COMPLETIONS_MODEL = "text-davinci-002"
COMPLETIONS_API_PARAMS = {
# We use temperature of 0.0 because it gives the most predictable, factual answer.
"temperature": 0.0,
"max_tokens": 300,
"model": COMPLETIONS_MODEL,
}
END_PROMPT = "Answer the question as truthfully as possible, if you don't know the answer, say I don't know"
db = Prisma()
db.connect()
class Client(discord.Client):
async def on_ready(self):
print(f'{self.user} has connected to Discord!')
async def on_message(self, message: discord.Message):
is_thread = message.channel.type == discord.ChannelType.public_thread
discord_message = db.discordmessage.create(data={
'channelId': str(message.channel.id),
'guildId': str(message.guild.id),
'discordId': str(message.id),
'isThread': is_thread,
'content': message.content,
'position': message.channel.message_count if is_thread else message.channel.position or 0,
})
if not is_thread:
prompt = f"{END_PROMPT}\n{message.content}"
response = openai.Completion.create(
prompt=prompt,
**COMPLETIONS_API_PARAMS,
)
answer = response["choices"][0]["text"].strip(" \n")
print(prompt)
print(answer)
if "I don't know" in answer:
return
thread = await message.create_thread(name=f"Answer to {message.content}")
await thread.send(answer)
intents = discord.Intents.default()
intents.message_content = True
client = Client(intents=intents)
client.run('<TOKEN_HERE>')
This code takes every message that’s not in a thread and attempts to use GPT-3 to answer the question. It adds “Answer the question as truthfully as possible, if you don’t know the answer, say I don’t know” before each message and then asks GPT-3 to complete the answer. If GPT-3 doesn’t know the answer, then the bot will stay silent, otherwise it will create a thread and respond with the answer.
Great! Now we have a silent bot that does nothing since GPT-3 doesn’t know anything about your Discord server and the types of questions that have been asked or answered in the past. It will always respond with “I don’t know.” Now is the fun part - we’re going to add context to the GPT-3 prompt so that the AI can actually give us some useful answers to our questions.
The biggest question we have to answer is: how do we find out what context is relevant to include in the GPT-3 prompt? We can’t include all of it - GPT-3 has a 4000 token limit. One way to decide what context is relevant is by turning the question into a vector, converting all other messages in the database to a vector and then pulling the top 10 similar messages. If you’re curious about text embeddings, this wikipedia article is a good place to learn: https://en.wikipedia.org/wiki/Word_embedding.
First, we need to turn our messages into an embedding. For that, we’re going to use the CLIP model. CLIP is a model that can help turn text or images into the same latent space so that text and images can be compared - it’s really exciting technology! In this tutorial, we’re just going to use it for text embeddings. The CLIP GitHub repo is a great place to learn more: https://github.com/openai/CLIP
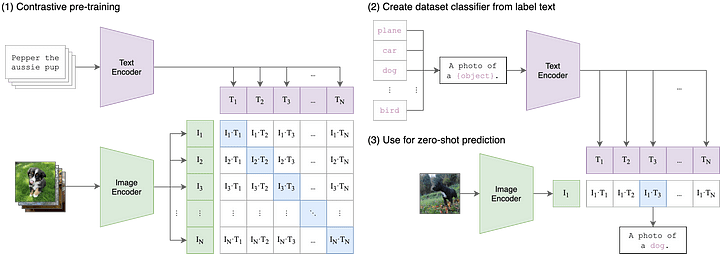
Let’s integrate CLIP into our bot so that we can generate embeddings for every message.
from typing import List
import discord
from prisma import Prisma
import torch
import clip
import openai
openai.api_key = "<API_KEY>"
COMPLETIONS_MODEL = "text-davinci-002"
COMPLETIONS_API_PARAMS = {
# We use temperature of 0.0 because it gives the most predictable, factual answer.
"temperature": 0.0,
"max_tokens": 300,
"model": COMPLETIONS_MODEL,
}
END_PROMPT = "Answer the question as truthfully as possible, if you don't know the answer, say I don't know"
db = Prisma()
db.connect()
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
def generate_clip_embedding(text) -> List[torch.FloatType]:
tokens = clip.tokenize([text])
with torch.no_grad():
text_features = model.encode_text(tokens)
return text_features.cpu().detach().numpy().tolist()[0]
class Client(discord.Client):
async def on_ready(self):
print(f'{self.user} has connected to Discord!')
async def on_message(self, message: discord.Message):
is_thread = message.channel.type == discord.ChannelType.public_thread
discord_message = db.discordmessage.create(data={
'channelId': str(message.channel.id),
'guildId': str(message.guild.id),
'discordId': str(message.id),
'isThread': is_thread,
'content': message.content,
'position': message.channel.message_count if is_thread else message.channel.position or 0,
})
clip_embedding = list(
map(str, generate_clip_embedding(message.content)))
if not is_thread:
prompt = f"{END_PROMPT}\n{message.content}"
response = openai.Completion.create(
prompt=prompt,
**COMPLETIONS_API_PARAMS,
)
answer = response["choices"][0]["text"].strip(" \n")
print(prompt)
print(answer)
if "I don't know" in answer:
return
thread = await message.create_thread(name=f"Answer to {message.content}")
await thread.send(answer)
intents = discord.Intents.default()
intents.message_content = True
client = Client(intents=intents)
client.run('<TOKEN_HERE>')
Now that we’ve generated the CLIP embeddings, we need to store it somewhere. Our goal is to be able to get the top 10 closest messages to the current message, so we have to store it somewhere where that query will be really fast. Unfortunately, a Postgres database is not going to be the best storage option to calculate top 10 closest embeddings to a vector. Luckily, there are some great solutions out there like Pinecone.
To get started with Pinecone, follow the Quickstart instructions here. Here is how we integrate Pinecone in our bot:
import discord
from prisma import Prisma
import pinecone
import torch
import clip
import openai
openai.api_key = "<API_KEY>"
COMPLETIONS_MODEL = "text-davinci-002"
COMPLETIONS_API_PARAMS = {
# We use temperature of 0.0 because it gives the most predictable, factual answer.
"temperature": 0.0,
"max_tokens": 300,
"model": COMPLETIONS_MODEL,
}
END_PROMPT = "Answer the question as truthfully as possible, if you don't know the answer, say I don't know"
db = Prisma()
db.connect()
pinecone.init(api_key="<API_KEY>",
environment="us-west1-gcp")
pinecone_index = pinecone.Index("message-embedding")
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
def generate_clip_embedding(text) -> List[torch.FloatType]:
tokens = clip.tokenize([text])
with torch.no_grad():
text_features = model.encode_text(tokens)
return text_features.cpu().detach().numpy().tolist()[0]
class Client(discord.Client):
async def on_ready(self):
print(f'{self.user} has connected to Discord!')
async def on_message(self, message: discord.Message):
is_thread = message.channel.type == discord.ChannelType.public_thread
discord_message = db.discordmessage.create(data={
'channelId': str(message.channel.id),
'guildId': str(message.guild.id),
'discordId': str(message.id),
'isThread': is_thread,
'content': message.content,
'position': message.channel.message_count if is_thread else message.channel.position or 0,
})
clip_embedding = list(
map(str, generate_clip_embedding(message.content)))
pinecone_index.upsert([(discord_message.id, clip_embedding, {
'guildId': str(message.guild.id), 'id': discord_message.id})])
if not is_thread:
prompt = f"{END_PROMPT}\n{message.content}"
response = openai.Completion.create(
prompt=prompt,
**COMPLETIONS_API_PARAMS,
)
answer = response["choices"][0]["text"].strip(" \n")
print(prompt)
print(answer)
if "I don't know" in answer:
return
thread = await message.create_thread(name=f"Answer to {message.content}")
await thread.send(answer)
intents = discord.Intents.default()
intents.message_content = True
client = Client(intents=intents)
client.run('<TOKEN_HERE>')
In this tutorial, we created a Pinecone index called message-embedding and upload all of our embeddings to that index. Notice that we also upload the guildId and an id as metadata to our index. We do that so we can filter by the guildId when searching for similar embeddings (we wouldn’t want to pull messages from other servers/guilds). The id is stored so that we have a mapping of vector to id in our Postgres database. It’ll help us get the actual text of the similar messages.
Next, we need to add the similar messages to our prompt.
import discord
from prisma import Prisma
import pinecone
import torch
import clip
import openai
openai.api_key = "<API_KEY>"
COMPLETIONS_MODEL = "text-davinci-002"
COMPLETIONS_API_PARAMS = {
# We use temperature of 0.0 because it gives the most predictable, factual answer.
"temperature": 0.0,
"max_tokens": 300,
"model": COMPLETIONS_MODEL,
}
END_PROMPT = "Answer the question as truthfully as possible, if you don't know the answer, say I don't know"
db = Prisma()
db.connect()
pinecone.init(api_key="<API_KEY>",
environment="us-west1-gcp")
pinecone_index = pinecone.Index("message-embedding")
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
def generate_clip_embedding(text) -> List[torch.FloatType]:
tokens = clip.tokenize([text])
with torch.no_grad():
text_features = model.encode_text(tokens)
return text_features.cpu().detach().numpy().tolist()[0]
class Client(discord.Client):
async def on_ready(self):
print(f'{self.user} has connected to Discord!')
async def on_message(self, message: discord.Message):
is_thread = message.channel.type == discord.ChannelType.public_thread
discord_message = db.discordmessage.create(data={
'channelId': str(message.channel.id),
'guildId': str(message.guild.id),
'discordId': str(message.id),
'isThread': is_thread,
'content': message.content,
'position': message.channel.message_count if is_thread else message.channel.position or 0,
})
clip_embedding = list(
map(str, generate_clip_embedding(message.content)))
pinecone_index.upsert([(discord_message.id, clip_embedding, {
'guildId': str(message.guild.id), 'id': discord_message.id})])
if not is_thread:
response = pinecone_index.query(vector=clip_embedding, top_k=10, filter={
'guildId': str(message.guild.id)}, include_metadata=True)
prompt = ""
for match in response['matches']:
score = match['score']
is_match_relevant = score < 0.6
if is_match_relevant:
break
id = match['metadata']['id']
if id == discord_message.id:
continue
matching_message = db.discordmessage.find_unique(where={
'id': id})
if matching_message:
prompt += f"* {matching_message.content}\n"
# limit the context in the prompt to 2,000 characters
prompt = prompt[:2000]
prompt += f"\n{END_PROMPT}\n{message.content}"
response = openai.Completion.create(
prompt=prompt,
**COMPLETIONS_API_PARAMS,
)
answer = response["choices"][0]["text"].strip(" \n")
print(prompt)
print(answer)
if "I don't know" in answer:
return
thread = await message.create_thread(name=f"Answer to {message.content}")
await thread.send(answer)
intents = discord.Intents.default()
intents.message_content = True
client = Client(intents=intents)
client.run('<TOKEN_HERE>')
Finally, our Discord bot is able to pull in relevant past context and include it in our prompt. It turns out, this works pretty well! You can see how it works for you by asking a question in Discord and then answering it yourself. Ask the same question again, and the Discord bot should be able to answer it for you!
In the next step, we’re going to productionize our bot. To do that, save your virtualenv dependenceis to a requirements.txt file with pip freeze > requirements.txt. Push your bot.py, requirements.txt, and schema.prisma files to a GitHub repo.
Productionizing the Bot
The final step is to productionize this bot so others can use it. I didn’t find many great options for productionizing a Discord bot, so I ended up going the old fashion route. The first thing you need to do is create a Linux GCP Compute Engine instance. You can follow the docs here to create one: https://cloud.google.com/compute/docs/instances. Next, you’ll need to create your Postgres instance, I used CloudSQL from GCP: https://cloud.google.com/sql/docs/postgres/connect-instance-private-ip.
Once you’ve got those set up, pull the GitHub repo which has the bot.py and requirements.txt file onto your GCP Compute Engine instance. Make sure you have Python installed on the Compute Engine along with pip. Next, run python -m pip install -r requirements.txt to install all the dependencies and run prisma generate --schema=schema.prisma to create the Python client to interact with your DB.
Finally, we’re going to run the bot with a systemd process. Systemd is a process manager in Linux. To use it, first create a systemd service file and put it in /etc/systemd/user/discord-bot.service. The contents of the file are:
[Unit]
Description=Discord Bot
After=network.target
[Service]
Type=simple
Restart=always
RestartSec=5
WorkingDirectory=~/
Environment=DATABASE_URL="<DATABASE_URL>"
ExecStart=python bot.py
[Install]
WantedBy=multi-user.target
Make sure to use your production database URL here. To start the bot, reload the systemd daemon with systemd --user daemon-reload and start the bot with systemd --user start discord-bot. Your bot should be running now! You can tail the logs by running journalctl -f --user -u discord-bot
Conclusion
I hope you enjoyed learning how to build this bot, I definitely did! Subscribe for more content like this and please comment if you have any questions or suggestions on how to improve this tutorial.
This article was written with the help of writethrough.io
This content originally appeared on DEV Community 👩💻👨💻 and was authored by Kunal Desai
Kunal Desai | Sciencx (2022-11-06T22:17:18+00:00) Building a GPT-3 Powered Discord Support Bot. Retrieved from https://www.scien.cx/2022/11/06/building-a-gpt-3-powered-discord-support-bot/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.