
This content originally appeared on Level Up Coding - Medium and was authored by Changsin Lee
Why does good software go bad? What can you do to prevent its regression?
· A Tale of Two Bugs
· What is Regression Testing?
· Why the Product Regresses
· Why Regression Testing Is Difficult
· Two Approaches to Regression Testing
∘ The Staged Method
∘ The Selection Method
· Regression Testing Best Practices
· References
The lifecycle of software ends with a release to production. It would have been a fairy tale ending if the software lived happily ever after. Alas, in reality, the product regresses one way or another, requiring the product team to pull resources together to either fix the bugs or update features. The purpose of the article is to find out common causes of regression and effective ways to manage regression testing.
A Tale of Two Bugs
Suppose that you can make a choice between two types of bugs. One is the dreaded blue screen of death in Windows as you can see above. The other is a website error of various kinds like the image below.
No one wants to encounter a bug of any kind but if you are forced to choose between the two types, which one would you choose? Think about it for a minute.
Your choice might be different from mine but I would rather choose a service error than a Windows bug because when the OS crashes, there is nothing you can do about it, except reboot and (hopefully) login again.
Now if you are a developer, you have to choose between an OS bug or a web server error, I think the choice should be clear. As stressful as it is to develop and maintain it, debugging, and fixing a web server error is far easier than doing it for an OS. Why? Because the code that is responsible for the bug is easily accessible to a web server developer. The OS code, on the other hand, is beyond reach for the developers, except through periodic OS updates. Knowing the difference between these two types of errors will become an important point when choosing the right strategy for regression testing.
What is Regression Testing?
The definition of regression testing says, “re-running functional and non-functional tests to ensure that previously developed and tested software still performs after a change.” (Wikipedia) It sounds simple, but does that mean running the same set of tests against the same software?
I do not mean to be philosophical but nothing stays the same. Just think about how the Windows operating system evolved over time from Windows 3.1, XP, Vista. 7, 8, 10, and 11. The Windows OS now is very different from Windows before.

How about test cases and tools? Do you think they changed over time? You bet! As the software is updated, new tests must be added and the original test cases have to be modified as well.
Why the Product Regresses
Whether it is an OS crash or a web service failure, all bugs are bad. The unfortunate fact is that many of these bugs are preventable if regression tests were run. Simply put, regression tests are tests designed to ensure all previous functions and features still work. Managing and running regression tests, however, is difficult for at least four reasons.
First and foremost, the product changes. All software changes. Any complex software contains some bugs that must be fixed or modified to meet the new demands of the customers. Or a new feature is added to attract a new group of users. The only software that does not change is an obsolete one. Even if the software itself does not change, its dependencies are updated which would be equivalent to pulling the carpet (the software) under its feet.
Second, the requirements change. After a program is released, a lot of things can happen. The demographic of the users' shifts, the expected market demand is not there, new regulations might be implemented, etc. These changes invariably lead to re-examining the requirements of the software. Thus we have a need to change the expectations of existing test cases.

Third, the data changes. Even if a program does not handle any database itself, data can come in different forms. Other than database data, user inputs, parameters from another service, sensor data from devices, files, and streams are all data forms the program must handle. The data often go through dramatic changes depending on the time, date, season, and location. As the data changes or migrates, the software as well as the regression tests are up for a change.
Fourth, the hardware changes. More space, faster speed, better resolutions, or new form factors are all different reasons to upgrade hardware. With the hardware changes, the firmware and the software need to be updated as well and the regression tests are in tow.

Why Regression Testing Is Difficult
All these changes create two problems for regression testing. First, test cases and tools need to be constantly updated. The problem is that these test cases and tools are not owned by an individual or a team. Unless a separate sustained engineering team maintains them, all stakeholders (PM, dev, and test) of a feature team need to be involved.
Second, whenever any change occurs, all regression test cases should be executed to ensure that there is no regression. If the number of test cases is not big and all automated, running a full test pass is not an issue. In general, however, a full test pass requires a huge investment in resources and time.
Two Approaches to Regression Testing
There are two approaches to regression testing depending on the type of software development life cycle the team adopted.
The Staged Method
The first approach is what I call the “staged” approach where you run a set of tests in tiered stages. A typical CI/CD pipeline has three stages: development, testing, and production. They correspond to three different environments in testing. Regression tests are run in all stages of the pipeline. The ideal structure of tests is a pyramid where there are a lot more unit tests than integration tests and end-to-end tests.
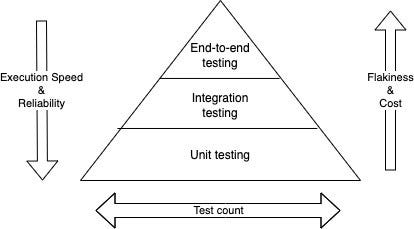
The idea is that all functional issues including edge cases are covered in unit testing. This is ideal because, in unit tests, all dependencies are supposedly “mocked” and thus they can be run very fast and reliably in an isolated environment.
During the integration testing phase, only integration test cases are run, those that check integration with other components. Typically, dependent components are called through API calls. They can and should be smaller in number because integration tests are run in a testing environment with other dependencies and are thus less reliable and time-consuming. You do not want to check functional issues in integration tests.
In the final end-to-end tests, there are even bigger dependencies like the UI or close-to-real service dependencies. The number of test cases needs to be even smaller than integration tests because of high flakiness and unreliability.
In a CI/CD pipeline, all regression tests are run but they are run automatically and in stages so the required resources and time are managed. If they are not automated but staged, then you can still use the same staged approach. If any bug is found in an earlier stage (e.g., the unit testing stage), then only a few selected tests are run and you save the time of running other tests which would be more time- and resource-consuming.
The Selection Method
The second strategy is the “selection” approach where you carefully select only relevant test cases for a code change. Obviously, if you know which test cases are relevant, you should choose the selective approach. The problem is that you cannot always know which ones are relevant. To know which ones are relevant, you need extra information.
A popular approach is to take into code coverage information you ran earlier. The correlation between code coverage and test cases is based on previously run tests. For instance, you can like the number of test cases that a file or a line number has hit. Then if a particular line is changed, you can do a reverse look-up to find a set of test cases that are most likely to be relevant to the introduced code changes.
To optimize test execution, the selection method needs to be implemented in three steps. The first step is the test suite minimization where duplicate and overlapping test cases are removed or consolidated. The second step is the test case selection step as we just described. In the final step, you want to prioritize the selected test cases so that more important test cases are run first.
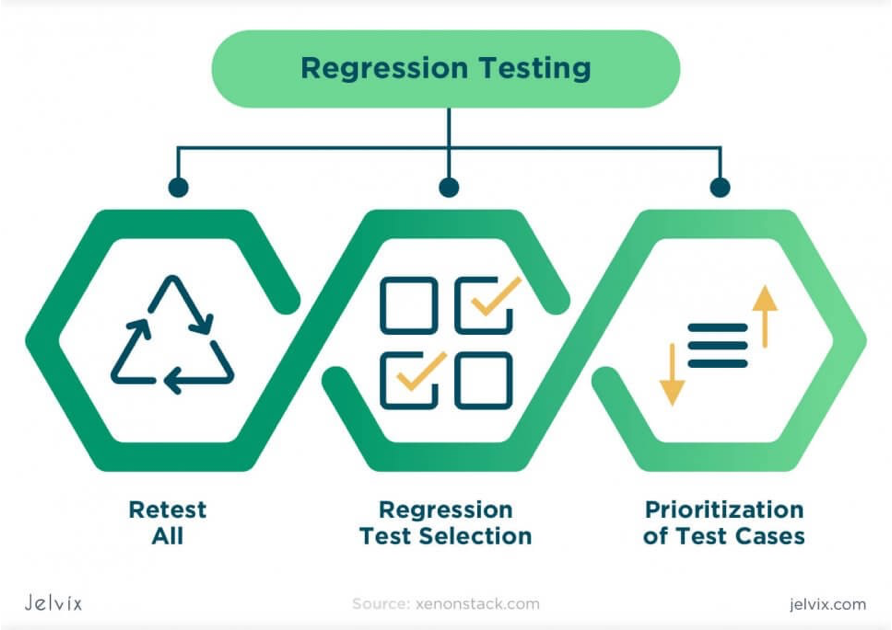
You might ask why the final step of prioritization of test cases is necessary. Isn’t merely selecting test cases enough since the point is to run all relevant test cases for a given code change? You don’t want to miss any important cases, right? The test coverage is important but without prioritization, you might waste time running unimportant test cases before hitting a critical bug. For instance, if the code change involves a change in installation, you want to run relevant setup scenarios first before checking functional issues. If you cannot even install a component, there is no point in running functional tests or checking documents.
Between the two methods, the selection method seems preferable since you can reduce test execution resources significantly if you have chosen the right test cases. In reality, however, the selection method does not always work for two reasons. First, the test case correlation table can be built only if you have existing test cases already and have a history. If the code change is completely new, you will not have correlating test cases and thus you have no test case to select from. Second, while you can build test case correlation tables based on code coverage, requirements, similarities, etc., it works relatively well only if the dependency relationship is clear. In other words, if your code change is in one of the components under test that you have test cases, you can select them. But if the changes are in one of the dependencies (e.g., libraries, OS, drivers, etc.), then the relationship is not quite clear and thus there would not have any matching test case.
For these reasons, in many feature teams, regression testing is largely done by test experts who know the domain well and have a wealth of experience in testing the service under test. In recent years, however, there are attempts to replace human experts with machine learning.[2]
Regression Testing Best Practices
In closing, here are the best practices for managing and running regression tests.
- Assign priorities for test cases: When writing a test case, always assign a priority. Doing so will allow filtering test cases when you have only a limited time which happens to be most of the time in production teams. Prioritization also helps in assessing bug severity when triaging.
- Use a staged approach: Regardless of whether your pipeline is CI/CD or not, always prioritize your test cases in such a way that the most relevant and important test cases are run first. Even if you don’t have a pipeline, doing the staged approach will save you a lot of resources and time.
- Create a test case for every bug: For every bug found, make it a habit and an enforced rule in the team to create a regression test case. Do it in every relevant stage. For a sufficient complex service, no product team can have a complete test coverage so bugs found in production are unavoidable. The important thing is to remember always to increase test coverage by creating regression tests for every bug.
The Pilgrim’s Progress by John Bunyan is said to be the most significant Christian fiction of all time. It narrates the journey that Christian makes toward the Celestial City. The progress he makes, however, is marred by numerous setbacks, but eventually, he arrives at his destination.
The article’s title is paying homage to the famous tale of heavenly progression, of course. But more importantly, it is drawing a parallel journey to that of Christian in the Pilgrim’s Progress. If a program were to live beyond the first initial release lifecycle, it needs updates and maintenance as long as it lives. Regression testing is one of the most important methods to provide vital life support.
“Those who do not know history are destined to repeat it.” — George Santayana
References
[1] Kush Bhatnagar (2020), Regression Test Case Selection Using Machine Learning. Analytics Vidhya.
[3] Vipindeep Vangala, et. al. (2009), Test Case Comparison and Clustering using Program Profiles and Static Execution. Microsoft Research.
Level Up Coding
Thanks for being a part of our community! Before you go:
- 👏 Clap for the story and follow the author 👉
- 📰 View more content in the Level Up Coding publication
- 🔔 Follow us: Twitter | LinkedIn | Newsletter
🚀👉 Join the Level Up talent collective and find an amazing job
The Program’s Regress was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Changsin Lee
Changsin Lee | Sciencx (2022-11-28T00:33:23+00:00) The Program’s Regress. Retrieved from https://www.scien.cx/2022/11/28/the-programs-regress/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.