
This content originally appeared on Level Up Coding - Medium and was authored by Federico Lelli
If you’re like me you probably don’t want to repeat yourself and you like to automate things so you can focus on what matters. While there’s plenty of tools and recipes to help you with so many common tasks in the software lifecycle management, release automation is one area where they fall short.
Let’s say you are maintaining a Git repository (optionally hosted on GitHub, GitLab, or some other service) and have CI/CD already in place (using GitHub Actions, GitLab CI, Jenkins, TeamCity, Bamboo, CircleCI etc). If you’re a best practice ninja you may also have defined a branching model that suits your workflow, established SemVer as your versioning scheme and also adopted a commit message convention like Conventional Commits or even defined your own.
You’re just one step away from the release management Nirvana! The overall strategy is well defined, but when it comes to managing branches, tags, pull/merge requests, changelogs and releases, you either do it manually, scratching your head trying not to leave anything behind, or automatically with several tools that you stitch together, filling the gaps with some custom code.
Nyx is an extremely flexible tool that lets you put it all together so you can set release management on auto pilot. You can find it here on GitHub. In this post I will show you how get started in minutes regardless of your project stack, size and complexity.

Background and disclaimer
A couple of years ago I wrote a similar post about Semantic Versioning and Release Automation on GitLab. The solution was based on semantic-release because, by the time, it was the most effective tool I found. If you are working on Node projects, that’s probably still the best option you have. However, when looking for a more portable and streamlined solution, it has some drawbacks that I couldn’t overcome with anything else.
I then decided to publish a brand new tool that could be used at scale for any stack, easy to get started with, and powerful enough to cope with the most subtle edge cases. And here it is! So don’t be surprised if I’m the first Nyx fan!
I also wrote another post just like this one on Nyx, but using Gradle, so if you’re using Gradle as your build tool you should probably jump right to that post.
This guide is assuming that:
- Semantic Versioning (SemVer) is used for versioning. As of this writing it’s the only supported scheme in Nyx but future releases may also support Maven and custom schemes
- you have a basic understanding of commit message conventions, the patterns used to embed structured informations into commit messages and read them automatically. If you don’t, Conventional Commits (a.k.a. Angular Convention) is a good place to start and is supported out of the box, although you are free to configure even custom conventions
- you know what a branching model is. If you don’t, you can get started here, where also standard models like GitFlow, OneFlow or GitHubFlow and GitLabFlow are covered
- you are confident with Git, branches and tags. You may optionally have a CI/CD environment in place and while Nyx is not constrained to any, examples are provided for GitHub Actions and GitLab CI
How Nyx works
Nyx splits the entire release process in steps that you can run together or one by one by means of different commands. The steps are: Infer, Make, Mark and Publish and they are all optional but they have chained dependencies: Publish > Mark > Make > Infer, so you can run Infer alone but Make depends on Infer, Mark depends on Make and so on.
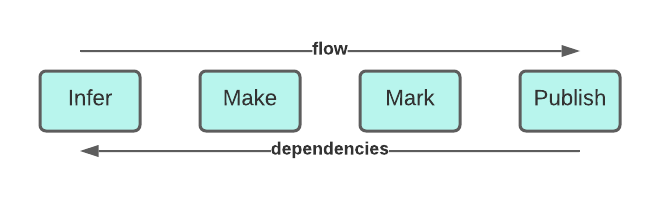
Infer is the first and most important step and it reads the Git commit history to set the project version which may be a new one (if there are significant changes to be released) or the previous one (if no significant changes are encountered). In other words: you always have the correct version set, be it the previous or a new one. The previous version is read from Git tags and, if a new one must be generated, it is computed by bumping the right identifiers on the previous one. The outcome is the project version attribute set to the correct value. Infer stops here and takes no further action, but your external script now can use the project version for any purpose.
It’s worth noting that many other tools only give you the version at the end of the entire process when it’s basically useless from a build script perspective (even after artifacts have been pushed to repositories) so you can’t intercept the version for use by your custom tasks (i.e. to embed it in documentation or other files). With those tools you can’t even add any verification in between so once you run the release task you have no other chance to control what is going to be published. With some tools it’s even worse as you don’t even know if they are going to give you a version to use (like when there are no new changes) so you end up running them twice: the first one as a smoke run, just to see if a new version is available, the second one (that you need to run conditionally) to actually use it.
With Nyx, instead, you are free to just run Infer and use the version number wherever you need it and even use its internal findings to customize the whole process. You always have a version, which may be the previous one or a new one. Even when you don’t need to issue a new release you have a version that you can use internally (i.e. for testing).
Make is the step where a changelog can be generated by rendering a customizable Handlebars template using the information from the release scope.
Mark can optionally commit pending changes (i.e. if you want to add the changelog file to your release before sealing it), tag the latest commit with the new release name and push changes to remote repositories.
Publish can finally issue the new release to remote services (i.e. GitHub Releases, GitLab Releases) to make it available to the audience. The changelog generated by Make can also be used as the release description.
With these granular tasks you can build any incremental release process without ever losing consistency, even when suspending the process and resuming it at any time later. After running Infer at the very beginning of your build script you can use the version and other findings for any other task and then, if you wish, you can finalize the release with Mark and Publish.
This is accomplished thanks to another very powerful feature exposed by Nyx: the State object. The State is where Nyx stores all of its internal information and is also available for you to read its details on the release scope and resolved configuration values. The State is created and updated by all the above tasks.
Get started
Nyx binaries are available for any platform and can be dowloaded from the latest release page. Pick the one that meets your platform and download it locally.
The rest of this guide assumes you’re running on Linux, the Nyx executable has been renamed tonyx(without the platform name), and the executable is available within the systemPATH.
Consider that all configuration options can be defined by different means, including configuration files (or even a combination of, both as.jsonor.yaml), command line arguments and environment variables. In this guide we’ll use a mix of command line arguments and configuration files.
To get started, open a shell and move into your Git project folder, then run:
$ nyx --info
Version: '1.3.0'
You can run the above command safely as it doesn’t change a thing in your repository. This is because by default only the Infer command is executed, in facts the above command is equivalent to:
$ nyx --info infer
Version: '1.3.0'
When you will be ready you can run Nyx with other commands instead of infer, likemake,mark andpublish, all described above.
The--info option only increases the output verbosity to see the version that Nyx inferred from the repository (1.3.0 in this case).
Now run it again like:
$ nyx --state-file=nyx-state.json
There’s no console output now as we are using the default verbosity, but a new nyx-state.json file has been created, containing structured informations on the findings about the Git repository. If you use the .yaml extension the content output will change to the YAML format.
The state file is documented here and if you take a look at its content you will see there’s plenty of informations in there. You can use the contents from this file to access all the findings on your repository in a structured way (i.e. from other tools and scripts).
Before we go on, consider runningnyx --helpto get a full synopsis or take a look at the configuration reference.
Configuration using presets
Let’s get started with a huge time saver: configuration presets. Presets are not to be confused with defaults as they are rather streamlined working configurations that you can use out of the box or as baselines where you can override any option to better suit your needs.
Let’s see how powerful and simple they are and start with a simple configuration file named.nyx.json in the Git repository folder. This file name is loaded by default by Nyx but you can change the name and path using the --configuration-filecommand line argument. Again, changing the extension to.yaml allows you to write the configuration in YAML instead of JSON.
To use the extended preset make the.nyx.jsonfile look like this:
{
"preset":"extended"
}It’s that simple! The extended preset is not the only one available but it can give you a taste of what you get with just one line of configuration:
- two commit message conventions are configured: Conventional Commits and gitmoji. Conventional Commits has priority so Nyx will try to match commits against gitmoji only when they are not matched by Conventional Commits. When commits are matched against a convention their type is inferred to categorise them into different sections of the changelog and also determine which version identifier should be bumped to generate the new version, if needed. Only those commits that are supposed to bump a version identifier are considered as significant
- eight release types, covering a broad range of branching models, including: mainline (official or regular releases from the main or master branch using only core version identifiers like x.y.z); integration and maturity (a.k.a. preview releases, from the develop, development, integration, latest, alpha, beta etc branches using pre-release versioning like x.y.z-prerelease.n), feature, fix and hotfix (from feat/XXX, feature/XXX, fix/XXX, hotfix/XXX branches), maintenance (a.k.a. post-releases) and release (from x.y.z, rel/x.y.x or release/x.y.x, with support for version range checks) and internal (the fallback used when no other type is matched, creating internal releases like x.y.z-internal.n-timestamp.20220101)
- two services (GitHub and GitLab) that can read authentication tokens (like Personal Access Tokens) from the GITHUB_TOKEN and GITLAB_TOKEN environment variables, respectively, in case you need to use them
- the CHANGELOG.md file is generated in the root project directory, with four sections for each release: Added, Fixed, Removed, Security, each one collecting commits of specific types
Going in detail on all this would be too much for a post like this but you can still jump on the configuration reference or see below for more. Nonetheless we can outline a few things:
- if a new release is produced, the release type that is matched for that version is where you can configure if Git operations like committing new changes, tagging and pushing to remotes have to be performed
- for those wondering if a version prefix is supported (i.e. v1.2.3 or rel1.2.3 instead of simply 1.2.3) the answer is yes, please see the reference
- some release types are configured for linear increases of version numbers (like mainline, using only core version identifiers like x.y.z) while others (like integration and maturity, using extra identifiers like x.y.z-prerelease.n) use the pre-release increments, also called collapsed versioning in Nyx, and again, this is something you can control for each release type
- the internal release type is not meant to apply any tags or be published but still generates a version number (with extra identifiers to make it explicit, like x.y.z-internal.n-timestamp.20220101) for you to complete the build. You should always have a fallback release type for internal releases (that doesn’t actually publish or push anything but keeps your build process consistent even in this case)
- Nyx has no predefined set of release types (like standard, pre-release, maintenance) and each one is completely configurable from scratch, giving you complete freedom of choice. The same applies to branch names, that you can fully configure
- when using extra identifiers (i.e. for pre-releases) you can define as many as you want, optionally assigning them dynamic values (or using auto increments) and you are not limited to one
Overriding preset values
What if a preset is almost what you needed, but not a perfect fit? Don’t worry, you don’t need to give up on presets and write a whole new configuration. You can start from the preset and override the values you need. Let me show you this modified version of the.nyx.json file with a few changes:
{
"preset":"extended"
"changelog":{
"path":"build/CHANGELOG.md"
},
"releaseTypes":{
"publicationServices":[
"github"
],
"items":{
"mainline":{
...
"description": "{{#fileContent}}build/CHANGELOG.md{{/fileContent}}"
"gitCommit":"true"
}
}
},
"services":{
"github": {
"type": "GITHUB",
"options": {
"AUTHENTICATION_TOKEN": "{{#environmentVariable}}GH_TOKEN{{/environmentVariable}}",
"REPOSITORY_NAME": "myrepo",
"REPOSITORY_OWNER": "jdoe"
}
}
}
}As you can see, we are still using the extended preset but the other options here have priority on that, so they can add new options or override existing ones.
One remark here: when using multiple configuration methods or customizing presets, complex configuration options (like commitMessageConventions, releaseTypes, services, for example) must be inherited or overridden as a whole. Overriding single values and inheriting others is not supported for this type of configuration option so when they are re-declared at one configuration level, all inherited values from those configuration methods with lower precedence, including presets, are suppressed.
Here we have changed the destination file of the changelog, which is now build/CHANGELOG.md instead of CHANGELOG.md.
Then we override the mainline release type, enabling the git commit of pending changes in case of new versions ("gitCommit" = "true") and using the contents of the changelog file for the release description that will be published to GitHub Releases. If we want to publish to GitLab Releases we can have it like this:
{
"preset":"extended"
"changelog":{
"path":"build/CHANGELOG.md"
},
"releaseTypes":{
"publicationServices":[
"gitlab"
],
"items":{
"mainline":{
...
"description": "{{#fileContent}}build/CHANGELOG.md{{/fileContent}}"
"gitCommit":"true"
}
}
},
"services":{
"gitlab": {
"type": "GITLAB",
"options": {
"AUTHENTICATION_TOKEN": "{{#environmentVariable}}GL_TOKEN{{/environmentVariable}}",
"REPOSITORY_NAME": "myrepo",
"REPOSITORY_OWNER": "jdoe"
}
}
}
}Remember the two services (GitHub and GitLab) configured by the preset above? At that stage they are an helper but they are not active yet (this is peculiar for services) so in order to actually publish releases we enable the service with "publicationServices": [ "github" ] or "publicationServices": [ "gitlab" ].
Then, in the services.github or services.gitlab section we set the repository name (myrepo) and owner (jdoe) and change the name of the environment variable to read the security token from (GH_TOKEN or GL_TOKEN). Regardless the name you use for the variable, the important thing to note is that you can avoid hardcoding your credentials into configuration files and, instead, read them dynamically from the environment where you can store them as secrets that you can configure as local environment variables or on CI/CD platforms.
On GitHub you can create a new Personal Access Token using these instructions and then make it available as an environment variable as an encrypted secret to your CI/CD pipeline. Even easier than that (but working only on the CI/CD environment), you can just use the automatically generated secrets.GITHUB_TOKEN, still from the secrets context.
On GitLab you can create a new Personal Access Token using these instructions and then make it available as an environment variable to your CI/CD pipeline.
Regardless the platform, make sure that the token you use has enough permissions for the operations you need to perform with it (like publishing releases).
Templates
Wondering what that syntax is for the release description and the AUTHENTICATION_TOKEN? Those are Mustache templates. that you can use for many configuration options in order to make your configuration dynamic and adaptive.
Nyx provides a functions library (Mustache lambdas) for you to use both in rendering contents (like changelogs) or reading values (like in configurations) and that lets you unleash a lot of extra power.
You can still hardcode simple values wherever templates are allowed, but using these functions often gives you extra value in terms of security and flexibility.
Git remote credentials
If any of your release types is configured to push local changes to remote repositories (some in the extended preset do) and your remote repository is write protected, you need to pass you credentials to Nyx as with this configuration snippet:
{
"git":{
"remotes":{
"origin":{
"user":"jdoe",
"password":"{{#environmentVariable}}PAT{{/environmentVariable}}"
}
}
}
}In this case we are configuring the credentials for the origin remote repository, hardcoding jdoe as the user name and reading the password from the PAT environment variable.
Because of the way the Git API works, you always need to pass both the user and password even when you’re using an OAuth or Personal Access Token. However you may need to pass them in different ways depending on the target service:
- when configuring a GitHub remote repository pass the token as the user name and an empty string as the password
- when configuring a GitLab remote repository pass the fixed string PRIVATE-TOKEN as the user name and the token as the password
Time to run
Ready? Let’s run this! You don’t feel confident yet? You can still use the dryRun flag so Nyx won’t change anything in your environment.
You have plenty of examples here to show how Nyx behaves based on branches and release types but let’s have a quick introduction here anyway.
Let’s say you are running the build script in the main or master branch, where you have a previous commit tagged as 2.3.4 and other commits since then, indicating that both the minor and patch identifiers have to be bumped (according to Conventional Commits):
$ nyx --info
Version: '2.4.0'
Version 2.4.0 is generated because the minor identifier is more significant than patch. If no significant commit is found, version 2.3.4 is still used from the previous tags.
What if we run in the alpha branch that we have just created off the main branch, where 2.3.4 was a tag on a previous commit, and then we added other commits meant to bump the minor and patch identifiers? Here it is:
$ nyx --info
Version: '2.4.0-alpha.1'
Then after another minor commit?
$ nyx --info
Version: '2.4.0-alpha.2'
And when we merge back to main?
$ nyx --info
Version: '2.4.0'
This is the beauty of collapsed versioning, used for pre-releases, and it happens because the alpha branch was configured with this scheme.
If you also run the publish task you will end up with your release published to the configured service, with its description taken from the changelog.
Under the hood
We said Infer is the most important task but how does it determine the version number? That’s complex but we’ll try to keep it simple. It takes into account:
- the Git commit history
- the configured release type(s)
- the configured commit message convention(s)
Release types are matched on each run based on the name of the current branch against a regular expression and other optional constraint like the workspace status (clean or dirty) or the value of some environment variables. Once the right release type has been selected from the configured ones, it instructs Nyx on:
- which Git actions to take (i.e. commit, tag, push)
- which versioning scheme to use (i.e. linear x.y.x for official releases, collapsed x.y.x-alpha.n for pre-releases) along with optional extra identifiers to add to version numbers (i.e. x.y.z-user.jdoe-timestamp.20220101)
- whether or not the release has to be published using some known service (i.e. GitHub Releases, GitLab Releases) or just stay local
- which tags to consider as previous versions when reading the commit history, so you can avoid false matches
- version range checks (to make sure only versions within specific ranges are issued from the branch). You can even let Nyx infer the version range from the branch name, in case you’re following a pattern
Once the above information is known, Infer inspects the commit history and determines the release scope (the commits to be included in the release) which may or may not contain significant changes, in respect of a new release. Whether or not each commit is significant depends on the configured commit message convention(s) used to inspect each commit message.
If a new release has to be created, it determines with identifiers to bump on the previous version and creates the new version number, otherwise it leaves the previous version unchanged. The identifier being bumped is also determined by the convention in use. Commit conventions are used to collect the intents of commits whose messages comply with a known pattern so that Nyx knows if changes are supposed to issue a new major or minor release, a patch, an hotfix, a pre-release, a maintenance or internal release and so on.
Finally, optional extra identifiers are applied to the version number and range checks are performed to make sure the new version is within the optional range constraints.
More on this topic can be found here.
More on the configuration
As we’ve seen above, presets are powerful and simple to use. The extended preset above brings a lot of configuration options listed here, but Nyx configuration can go way beyond.
You can use YAML and JSON files, or even a combination of them. If they can’t be found at default locations (.nyx.jsonor .nyx.yaml) you can pass their path (or also a remote URL).
By mixing several configuration means you can, for example, inherit some centrally managed organisation-wide settings and then customise them on a project basis, or have different teams share parts of the configuration and so on.
All configuration options can also be passed as command line arguments or even environment variables in order order to meet even the most remote edge cases (i.e. for secure secrets management, compliance in hardened environments, flexibility in CI/CD environments and so on).
The full range of configuration means and their evaluation order is described here while the configuration reference describes all means for each option.
More on commit message conventions and version override
In this guide we are using the Conventional Commits convention as it’s widely used but nothing prevents you from using any other, including some custom convention you may have defined yourself.
Commit message conventions can be configured as anything else in Nyx and more than one can be used so you can even combine them.
Conventions are the way Nyx is able to infer information from the commit history for full automation. Again, they allow each commit to define which version identifiers to bump (if any) in order to compute new version numbers starting from previous ones.
Nonetheless you are always able to override the version to use when you need to completely take over the inference logic or you can do it by just passing the identifier to bump, so that Nyx still reads the previous version from the commit history and goes straight to bumping, without inspecting commits.
Conditional release types
Let’s assume you want your official releases to be issued by the main or master branch only but, in order to grant the build environment consistency, the entire range of tests to be executed, etc, you need them to be issued from the centralised CI/CD environment only, avoiding developers to take loopholes.
In other words you need the official release type to be conditionally matched only on CI/CD environments.
Remember that release types are evaluated in the order they are listed so each item is only evaluated if previous ones were not successfully matched. Also, the rules used to match a release type are based on the current branch name (matched against a regular expression), the workspace status (clean or dirty) or some environment variables.
In this case we can use an environment variable (i.e. CI) to be present in order to match the official release type.
To complete this example, let’s add a fallback release type that mimics the official one but, instead of issuing official releases, it only issues internal releases, properly identified as such.
An example configuration snipped may be:
{
...
"releaseTypes":{
"enabled":[
"mainline",
"internal"
],
"items":{
"mainline":{
"filterTags":"^([0-9]\\d*)\\.([0-9]\\d*)\\.([0-9]\\d*)$",
"gitCommit":"false",
"gitPush":"true",
"gitTag":"true",
"matchBranches":"^(master|main)$",
"matchEnvironmentVariables":{
"CI":"^true$"
},
"publish":"true"
},
"internal":{
"filterTags":"^([0-9]\\d*)\\.([0-9]\\d*)\\.([0-9]\\d*)$",
"gitCommit":"false",
"gitPush":"false",
"gitTag":"false",
"identifiers":[
{
"position":"BUILD",
"qualifier":"internal",
"value":"{{#sanitize}}{{branch}}{{/sanitize}}"
}
],
"matchBranches":"^(master|main)$",
"publish":"false"
}
}
}
}Here the internal type is evaluated only when mainline is not matched first (i.e. because no CI environment variable has been found with value true) and while mainline issues official releases like x.y.x, internal adds the internal qualifier in the build part of the version number, like: x.y.z+branch.main. The internal release type does not commit, tag or push any changes to the repository and doesn’t publish anything, while mainline does.
More on dynamic configuration using templates
Another way to accomplish the same outcome of the previous example is leveraging templates. This way you don’t even need to add an additional release type (but remember, one last fallback release type is suggested in all configurations). It looks like this:
{
...
"releaseTypes":{
"enabled":[
"mainline"
],
"items":{
"mainline":{
"filterTags":"^([0-9]\\d*)\\.([0-9]\\d*)\\.([0-9]\\d*)$",
"gitCommit":"false",
"gitPush":"{{#environmentVariable}}CI{{/environmentVariable}}",
"gitTag":"{{#environmentVariable}}CI{{/environmentVariable}}",
"matchBranches":"^(master|main)$",
"publish":"{{#environmentVariable}}CI{{/environmentVariable}}"
}
}
}
}In this case the configuration is cleaner and the same release type mainline is matched regardless of the environment. However, some of its flags controlling whether or not the Git push and tag operations have to be performed (along with the final publication) get their values dynamically by reading the value of the CI environment variable.
This is possible because the CI environment variable has the value true, when defined, and the mentioned flag are evaluated as booleans.
Using Docker
Nyx is also available as a small footprint Docker image on two public registries:
- Docker Hub (the default)
- GitHub Container Registry
You can pull and run the container as usual, like (using the Docker Hub registry in this example):
$ docker run -it --rm -v /local/path/to/project:/project mooltiverse/nyx:latest --info infer
Version: '1.3.0'
This example is like its command line equivalent:
$ nyx --info infer
Version: '1.3.0'
with one caveat: you need to mount the Git repository directory into the container, using the-v /local/path/to/project:/project flag, otherwise Nyx won’t be able to get access to it. just replace the /local/path/to/projectpath to the actual path to your Git repository folder on the host machine (or a Docker volume name) and that’s it.
You can use all command line arguments and configuration files as usual, and if you’re using environment variables, remember you need to pass them as -eflags.
Also consider running the container using the -u $(id -u):$(id -g)flag (or simply -u $(id -u)) in order to avoid file ownership issues between the container and the host access.
Please jump to the documentation site for more.
Pull/Merge commits
When creating pull or merge requests you often squash the commits belonging to the merge. This is a good practice to avoid cluttering your commit history but from the Nyx point of view it makes the messages of single commits belonging to the merge operation invisible, so are their messages. In other words, if you meant the commits to trigger a release by mean of their commit messages you will see that Nyx doesn’t version the commit coming from the merge request because it just doesn’t see those messages anymore and the commit message convention is unable to detect their intent. This is true unless you set the title of the merge request to be a significant message, in which case Nyx is able to detect the message and trigger the version.
Nyx, the Semantic Release Automation Tool was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Federico Lelli
Federico Lelli | Sciencx (2022-12-16T00:55:54+00:00) Nyx, the Semantic Release Automation Tool. Retrieved from https://www.scien.cx/2022/12/16/nyx-the-semantic-release-automation-tool/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.