
This content originally appeared on Level Up Coding - Medium and was authored by Nic Chong
10 tips for optimizing your Firestore database

Tip #1 Choose the right database mode for your use case
When working with Firestore, it’s important to choose the right database mode for your use case. Firestore offers two modes: Native Mode and Datastore Mode. Here’s a brief overview of each mode and when you might want to use it:
Native Mode
This is the newer, more powerful version of Firestore that offers real-time updates and advanced querying capabilities. It uses a NoSQL data model and is well-suited for applications that need to handle high volumes of read and write operations. If you need real-time updates or want to be able to perform more advanced queries on your data, you should consider using the Native Mode.
Datastore Mode
This is a legacy version of Firestore that is based on the Google Cloud Datastore product. It offers strong consistency and transactional support, which makes it a good choice for certain types of workloads, such as those that require strong consistency or need to interact with other Google Cloud services. If you need strong consistency or want to use other Google Cloud services, you might consider using the Datastore Mode.
Here’s a table that summarizes the key differences between the Native Mode and Datastore Mode:
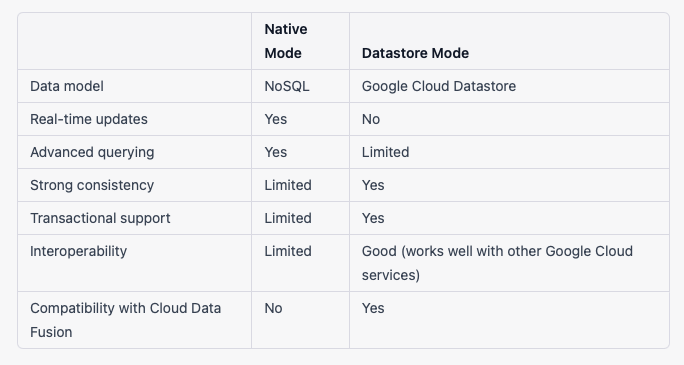
If you’re not sure which database mode to use, you can try both and see which one performs better for your specific use case. You can switch between the Native Mode and Datastore Mode at any time by migrating your data and index definitions and updating your client libraries and security rules.
It’s important to assess the specific needs and requirements of your application when choosing the right database mode. Consider the type of data you will be storing, the volume of read and write operations you expect to handle, and any other specific requirements you have. You may also want to test the performance and scalability of each mode to see which one performs better for your use case. Keep in mind that each mode has its own trade-offs, and it’s up to you to decide which one is the best fit for your application.
Tip #2 Design an efficient and scalable data structure
Designing an efficient and scalable data structure is crucial for optimizing your Firestore database. A well-designed data structure can improve performance, reduce the amount of data you need to store and retrieve, and make it easier to work with your data. Here are some tips for designing an efficient and scalable data structure:
- Use nested data structures when possible: Firestore supports nested data structures, which can make it easier to organize and retrieve related data. For example, if you have a collection of users and each user has a list of favorite products, you could store the favorites as an array within the user document, like this:
{
"name": "John Smith",
"favorites": [
{ "product_id": "p1", "name": "Product 1" },
{ "product_id": "p2", "name": "Product 2" },
{ "product_id": "p3", "name": "Product 3" }
]
}- Denormalize your data: In traditional relational databases, it’s common to normalize data by breaking it up into smaller, related tables and using joins to retrieve the data. However, this can be inefficient in a NoSQL database like Firestore, as it requires multiple read operations and can increase the amount of data you need to store. Instead, you can denormalize your data by duplicating it across multiple documents and collections. For example, if you have a collection of users and a collection of products, you could store the user’s favorite products as an array within the user document and store the product details within the product collection, like this:
// User document
{
"name": "John Smith",
"favorites": ["p1", "p2", "p3"]
}
// Product documents
{ "product_id": "p1", "name": "Product 1" }
{ "product_id": "p2", "name": "Product 2" }
{ "product_id": "p3", "name": "Product 3" }
- Use arrays sparingly: Arrays can be useful for storing lists of items, but they an also be inefficient to work with in Firestore. Because Firestore has to read the entire array to retrieve a single element, it can be slower to query arrays with a large number of elements. In addition, storing large arrays can increase the size of your documents and the amount of data you need to store and retrieve. To optimize your data structure, you should try to use arrays sparingly and only when they are necessary.
- Use references instead of embedding data: If you need to store a large amount of data within a document, it can be more efficient to use references instead of embedding the data directly. A reference is a special type of field that stores the ID of another document in your database, rather than the entire document itself. When you need to access the data, you can use a query to retrieve the referenced document separately. This can reduce the size of your documents and improve performance, especially for data that is accessed infrequently or is not needed in real-time.
- Consider using subcollections: If you have a large number of related documents that are accessed together, you might consider using subcollections to organize them. A subcollection is a collection within a document, and it can be useful for storing data that is closely related to the parent document. For example, if you have a collection of users and each user has a large number of posts, you could use a subcollection to store the posts within each user document, like this:
{
"name": "John Smith",
"posts": [
{ "title": "Post 1", "body": "..." },
{ "title": "Post 2", "body": "..." },
{ "title": "Post 3", "body": "..." }
]
}By following these tips and taking the time to design an efficient and scalable data structure, you can significantly improve the performance and scalability of your Firestore database.
Tip #3 Use composite indexes to support advanced queries
Firestore offers advanced querying capabilities, but in order to use them effectively, you will need to set up composite indexes. A composite index is an index that includes multiple fields, rather than just a single field. It allows you to perform complex queries that filter and sort data based on multiple fields at the same time.
Here’s an example of a simple query that filters data based on a single field:
db.collection("users").where("age", ">", 30).get()This query retrieves all documents from the “users” collection where the “age” field is greater than 30.
To perform a query that filters data based on multiple fields, you will need to set up a composite index. For example, to filter users by age and location, you could use the following query:
db.collection("users").where("age", ">", 30).where("location", "==", "San Francisco").get()To set up a composite index, you will need to specify the fields you want to include and the order in which they should be indexed. For example, to set up an index for the “age” and “location” fields, you might use the following index definition:
{
"fields": [
{ "fieldPath": "age", "order": "ASCENDING" },
{ "fieldPath": "location", "order": "ASCENDING" }
]
}This index definition tells Firestore to create an index that includes both the “age” and “location” fields, and to sort the index entries in ascending order for both fields.
Once you have set up a composite index, you can use it to perform advanced queries that filter and sort data based on multiple fields. This can be especially useful if you have a large dataset and need to perform complex queries to retrieve specific data.
It’s important to note that composite indexes can take up extra space and may impact the performance
Tip #4 Denormalize your data to reduce the need for joins
In a traditional relational database, it’s common to normalize data by breaking it up into smaller, related tables and using joins to retrieve the data. However, this can be inefficient in a NoSQL database like Firestore, as it requires multiple read operations and can increase the amount of data you need to store and retrieve.
To optimize your data structure in Firestore, you can denormalize your data by duplicating it across multiple documents and collections. Denormalization can reduce the need for joins and improve performance, especially for data that is accessed frequently or needs to be retrieved in real-time.
Here’s an example of a normalized data structure that uses two collections, “users” and “posts”, to store user and post data:
// Users collection
{ "user_id": "u1", "name": "John Smith" }
{ "user_id": "u2", "name": "Jane Doe" }
// Posts collection
{ "post_id": "p1", "user_id": "u1", "title": "Post 1", "body": "..." }
{ "post_id": "p2", "user_id": "u1", "title": "Post 2", "body": "..." }
{ "post_id": "p3", "user_id": "u2", "title": "Post 3", "body": "..." }
To retrieve the posts for a specific user, you would need to use a join to combine the data from the “users” and “posts” collections.
To denormalize this data structure, you could store the user’s posts as an array within the user document, like this:
// Users collection
{
"user_id": "u1",
"name": "John Smith",
"posts": [
{ "post_id": "p1", "title": "Post 1", "body": "..." },
{ "post_id": "p2", "title": "Post 2", "body": "..." }
]
}
{
"user_id": "u2",
"name": "Jane Doe",
"posts": [
{ "post_id": "p3", "title": "Post 3", "body": "..." }
]
}
This denormalized data structure allows you to retrieve a user’s posts by simply reading the “posts” array within the user document, rather than performing a join. This can improve performance and reduce the amount of data you need to store and retrieve.
Keep in mind that denormalization has trade-offs and may not be suitable for all data structures. You should carefully consider your specific needs and requirements before deciding whether to denormalize your data.
Tip #5 Use batch operations to improve performance
Firestore allows you to perform batch operations to improve performance and reduce the number of read and write operations you need to perform. A batch operation is a group of write or update operations that are performed together as a single unit. By using batch operations, you can perform multiple operations at once, which can reduce the amount of time and resources required to complete them.
Here’s an example of how you can use a batch operation to update multiple documents at once:
let batch = db.batch();
let doc1 = db.collection("users").doc("u1");
let doc2 = db.collection("users").doc("u2");
batch.update(doc1, { name: "John Smith" });
batch.update(doc2, { name: "Jane Doe" });
batch.commit().then(() => {
console.log("Batch update complete");
});
This code creates a batch object and adds two update operations to it, one for each user document. Then, it uses the commit() method to execute the batch operation and update both documents at the same time.
You can also use batch operations to perform multiple write or delete operations. For example, you might use a batch operation to delete multiple documents at once or to write a large number of documents in a single operation.
Batch operations can significantly improve the performance of your Firestore database, especially for workloads that require a large number of read or write operations. However, it’s important to note that batch operations have certain limitations, such as a maximum size of 500 operations per batch and a maximum rate of one batch per second. To optimize your usage of batch operations, you should consider the specific needs and requirements of your application and test the performance of different batch sizes and frequencies to find the best balance.
It’s also worth noting that batch operations are atomic, which means that they are either completed in full or not completed at all. If an error occurs during the batch operation, none of the operations will be applied, which can be useful for maintaining the consistency of your data.
In summary, batch operations are a powerful tool for optimizing the performance of your Firestore database. By grouping multiple read and write operations together, you can reduce the number of operations you need to perform and improve the overall performance of your application.
Part 2: 10 tips for optimizing your Firestore database
Don’t Miss my upcoming content and case guides:
https://medium.com/@nicchong/subscribe
If you have any questions, I am here to help, waiting for you in the comments section :)
Part 1: 10 tips for optimizing your Firestore database was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Nic Chong
Nic Chong | Sciencx (2023-01-03T13:49:51+00:00) Part 1: 10 tips for optimizing your Firestore database. Retrieved from https://www.scien.cx/2023/01/03/part-1-10-tips-for-optimizing-your-firestore-database/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.