
This content originally appeared on Level Up Coding - Medium and was authored by The Educative Team

This article was written by Educative’s Co-founder and CEO, Fahim ul Haq.
Twitter has been under the microscope ever since Elon Musk’s acquisition of the company in the fall. Under changing management and with reduced staff, Twitter intends to speed up its timeline service workflow, all while cutting costs. With all the focus on the change in leadership and layoffs, I became more interested in examining Twitter from an engineering perspective.
This post will dive into the proposed changes to Twitter’s system design. If you’re curious about how these changes will help engineers reach those goals, keep reading.
I’ll start by covering Twitter’s current architecture in depth. We’ll cover the timeline service, onboarding, people discovery, ad mixing, the distributed key-value store Manhattan, and their tweet ranking service.
Afterward, we’ll go through the planned changes to the system — what they are and how they’ll help. The biggest and most notable change is a transition to a new timeline mixer called “Home Mixer.” This comes along with updated, more detailed information about other System Design building blocks like:
- Manhattan: Key-value store.
- Gizmoduck: User profile storage service.
- Social Graph: Distributed graph database for mapping social connections.
- Tweety Pie: OOP-object for representing internal data.
Then, we’ll take a look at how these changes will affect Twitter and how else Twitter might improve in the future.
We’ll cover:
- Twitter’s current architecture
- History of Manhattan
- How a tweet recommendation engine works
- Twitter’s new architecture
- Improving system architecture
- Wrap up
Twitter’s current architecture
At the center of it all is the “Timeline mixer.” This service was developed way back when Twitter first made the switch to algorithmically generated timelines, instead of reverse chronological ones.
Old Twitter used to just send a stream of tweets, retweets, and likes with the newest ones at the top. Now, Twitter generates timelines with an algorithmic recommendation service that serves users a totally personalized timeline. A more complicated service, but a better one.
Timeline mixer compiles, or mixes, content from multiple sources to create a holistic timeline. These main content sources are:
- Tweets from a user’s network/or public or promoted posts
- Twitter Spaces
- Twitter Communities
But, if you’ve used Twitter, you’ll know that relevant, ranked tweets aren’t the only thing that shows up on your timeline. The timeline service also mixes in content from several other services.
These secondary services are:
- Onboarding
- People discovery
- Ad mixer
Despite the Timeline Mixer being phased out in favor of the new Home Mixer service, the above three smaller services should be largely unchanged. Let’s cover them in more detail.
Onboarding
This service is a unique workflow that introduces new users to the platform. After a user has completed onboarding, nothing from the onboarding service will be used. The core intent for onboarding is to establish users with a base social network. Without anyone to follow or any mutual accounts, Twitter won’t really click for a user.
Facebook has a similar onboarding service. They found that for the majority of users, 20 friends was the critical mass. After a user had at least 20 friends, they could return to the platform and have a positive experience. Fewer than 20 friends and a user would probably bounce after creating their account.
People discovery
Back in 2010, Twitter unveiled its first iteration of the people discovery service. It was called “Suggestions for you…” and Twitter was ahead of the curve for social networks that aim to grow their users’ connections.
Unlike the onboarding service, people discovery is an ongoing process. After a user reaches the critical mass of connections, a larger network still increases engagement with the platform.
Twitter’s account suggestions are based on algorithms that personalize the service. Here are some connections that they consider:
- Contacts: If you’ve uploaded your contact list to Twitter, the platform will suggest those that have Twitter accounts. Additionally, Twitter will suggest accounts that you appear as a contact in.
- Location: Twitter makes geologically based suggestions based on the city or country that you live in.
- Engagement: Twitter will suggest accounts based on your activity, interests, and extended network (people that are followed by people you follow).
- Promotion: Certain accounts can be promoted through paid ads.
Twitter’s people suggestion service was one of the first in the field, and when Facebook went after Twitter in 2016 and 2017, it was one of the services that it aimed to recreate. But that wasn’t the only service that Facebook wanted to recreate. Twitter piloted the approach of treating celebrity accounts or certain celebrity tweets as public. These tweets could be mixed into timelines to increase variety and engagement.
Ad mixer
Much like how a Timeline mixer ranks and orders hydrated candidate tweets, an Ad mixer populates a timeline with relevant ads. As Twitter grew and developed more promoted services, its monolithic ad-serving architecture quickly became outdated. We’ll briefly cover Twitter’s current ad funnel and the workflow for ad mixing.
Through trial and error, Twitter engineers were able to build a reusable and cohesive ad service capable of all “general purpose tech ad functions.” Twitter identifies these functions as:
- Candidate selection: Given user data, identify ad candidates that are interested in bidding. This helps ads stay relevant to the user and gives advertisers the ability to only target relevant demographics.
- Candidate ranking: Given user attributes, score and rank the ad candidates based on relevance to the user.
- Callback and analytics: Twitter enforces contracts that enable them to collect performance data and analytics on all services responsible for ad serving.
Twitter’s ad service is built around these three functions:
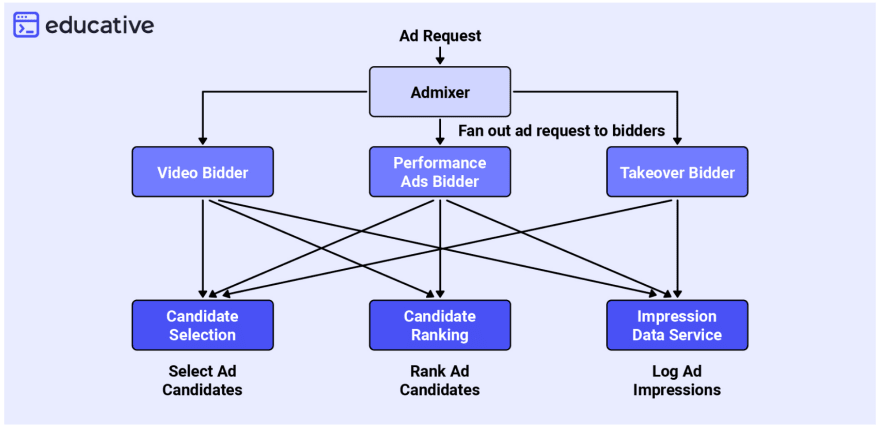
You can see the three most common use cases represented at the very bottom of this workflow. This microservice architecture allows for a diversification of concerns and enables the servers that were once allocated to running the monolithic architecture to be leaner, faster, and more reliable.
Let’s shine a light on a couple of other key players in Twitter’s current system.
History of Manhattan
We’ll start with Manhattan, Twitter’s in-house distributed key-value store. Manhattan is responsible for storing tweets, accounts, direct messages, and more. They developed it after having scalability issues with Cassandra. Cassandra is an open-source NoSQL database with many servers that handle large volumes of data.
Since the very nature of Twitter is built around the idea of tweets being served in real-time, a low-latency database is paramount to its success.
Twitter built Manhattan specifically to address requirements like reliability, availability, low latency, and scalability, but also extensibility, operability, and developer productivity. By providing a large-scale database that is built for the future, Twitter can ensure that developers will be able to store and retrieve whatever data they need without having to worry about it.
Manhattan is separated into four main layers. From top to bottom, they are:
- Interfaces: How a customer interacts with the system.
- Storage services: Additional, developer-centric features like Batch Hadoop importing, Strong Consistency service, and Timeseries Counters service.
- Core: The most critical aspect of the system, it allows for adaptability as well as handling all sorts of conflicts.
- Storage engines: One of the lowest levels of storage, this informs how data is kept on a disc and the data structures used to store information in memory.
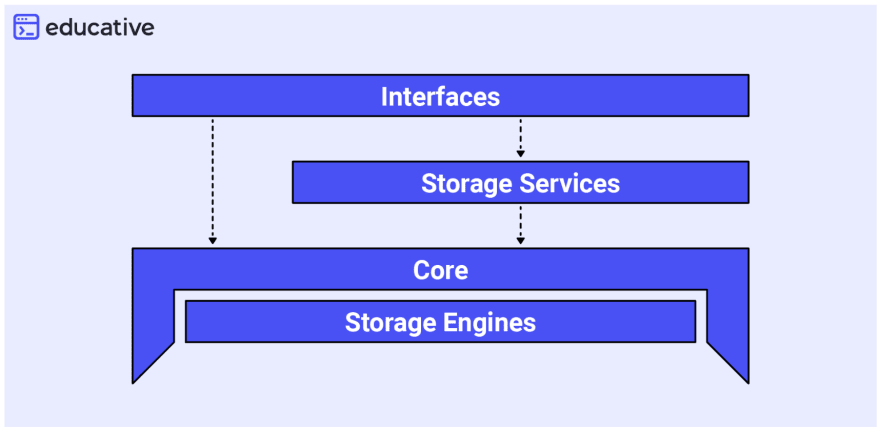
Manhattan is configured to allow other 3rd-party storage engines to be plugged in for future use. They’ve taken advantage of this and now implement RocksDB as a storage engine to store and retrieve data in a particular node.
Twitter’s in-house storage engines are:
- Seadb: Read-only format for batch data from Hadoop.
- SSTable: Log-structured merge tree-based format for write-heavy workloads.
- Btree: Btree format for heavy read and light write workloads.
If you’re interested in learning more about the database, check out Twitter’s engineering blog dedicated to Manhattan.
There, Twitter engineers go much more in-depth about Manhattan, covering why and how they built it.
How a tweet recommendation engine works
A recommendation engine is a real backbone of how these mixing services generate timelines. After content is hydrated, a recommendation engine is able to sort each piece of content into a personalized timeline. This engine determines what tweets, accounts, retweets, and Spaces an individual user is likely to find most interesting. By personalizing timelines, Twitter tries to ensure that users have the best possible experience on the platform.
The Timeline mixer features a recommendation engine, but so does the ad mixer. It’s not just relevant Twitter content that needs to be sorted, but ads too. Every part of content fed to users on Twitter is personalized to maximize user interest and engagement.
Much like other platforms (Facebook, YouTube, Netflix, Spotify, etc.), bringing the right content to the right users can make or break your service. According to Netflix, 80% of the shows watched come from recommendations. All of these recommendations, for any service, are based on your history with content on the platform.
Before breaking down the architecture of a recommendation engine, let us first address the criteria that they are trained on. There are several key metrics that assess tweets:
Positive actions:
- Impressions: this is the total number of accounts that scroll past a tweet.
- Engagement: interactions with a tweet (clicks, likes, retweets, etc.)
- View time: How long a user spent reading the tweet.
Negative actions:
- Hide: Hiding a tweet so that it no longer shows up on your timeline.
- Report: Reporting a tweet as inappropriate.
Certain actions are weighted differently. Each action is logged and then scored in aggregate to rank the tweet. It gets more complicated when we have to consider how the scoring relates to real users. Since Twitter wants to ensure the best experience possible, tweets should be delivered according to users’ own individual interests, hobbies, social networks, and demographic.
It is the job of a recommendation engine to structure and order timelines based on these criteria.
Tweet recommendation system architecture
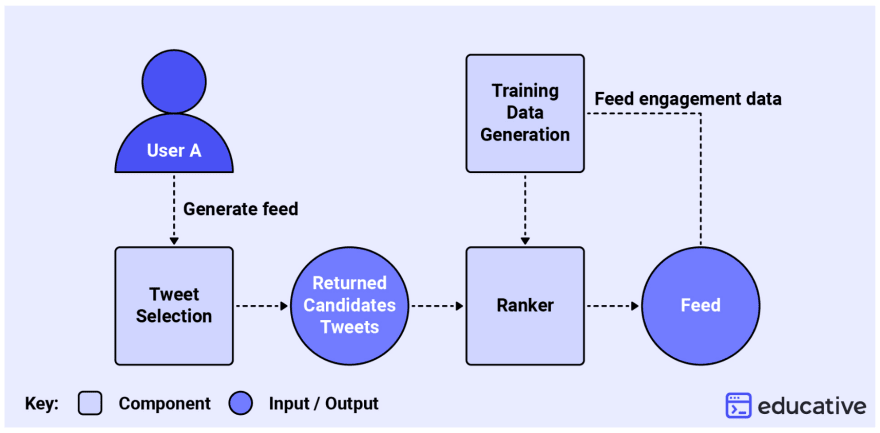
Tweet selection: The first step is to fetch a pool of tweets from the user’s network.
Training data generation: As mentioned above, each tweet will be weighted according to the other users’ engagement. This component is responsible for generating positive and negative examples for training the user engagement prediction models.
Ranker: Receives the pool of tweets and predicts the probability of engagement for each one. This component can be used to rank the total engagement prediction for a tweet or even specific granular categories.
Selecting Tweets
After the ranking process is complete, there is still more to do. In order to give users an appropriate timeline that is representative of their Twitter social network, multiple factors need to be considered.
There are several tweet selection schemes that inform how a timeline is structured.
- New tweets: Tweets from a user’s network that were published in the time elapsed from the last login.
- New tweets + unseen tweets: In addition to the recent tweets, unseen tweets should be restored and added to the timeline. It’s highly possible that tweets posted before the last login have increased in engagement and attention and need to be reassessed.
- User returns after a while: In this edge case, say a user’s last login was weeks ago. Tweet selection will be capped to a certain number of candidates.
- Network tweets + interest/popularity-based tweets: Tweets outside of the user’s immediate network should be considered if there is a high possibility of engagement. Several criteria are considered: alignment with the user’s interests, local or global trends, or engagement with the user’s network.
After tweets are fed to the user through the timeline, the system collects data on what the user engages with to serve as training data to inform future recommendations.
There is much more to say about how Twitter’s recommendation engine works. More areas to explore in detail are the features that a feed-based system should incorporate and the types of logical models that are used to rank candidate tweets. I won’t cover that here, but if you’re interested in diving a little deeper into Twitter’s recommendation engine, the Educative course Grokking the Machine Learning Interview covers the exact aspect of Twitter in depth.
Twitter’s new architecture
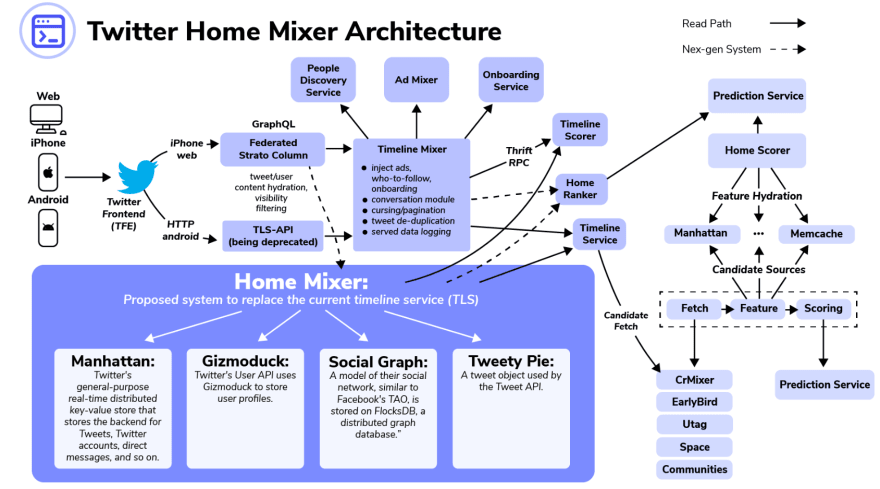
The dotted lines in this diagram represent Twitter’s new proposed read path. The new “Home Mixer” service will be set to replace the Timeline service.
Home Mixer calls on four services:
- Manhattan: As mentioned above, this is Twitter’s in-house key-value store.
- Gizmoduck: This service is responsible for storing all user information in profiles. It is called through Twitter’s User API.
- Social graph: This service is similar to Facebook’s TAO. It maps all of the connections between users’ social networks and is stored on FlocksDB. A social graph exists so that this map can be accessed without the compute-heavy task of trawling a user’s network every time the information is needed.
- Tweety Pie: TweetyPie is essentially Twitter’s object that represents a tweet in the Tweet API. It has properties (timestamp, ID, author, etc.) and methods (quote, delete, flag, etc.).
Improving System Architecture
Now that we’ve had a peek under the hood of Twitter, let’s discuss how these changes will help the platform.
Why low latency matters
Twitter’s beginning as a reverse chronological “wall” of tweets has now morphed into a much more data-intensive system. As mentioned above, the mixing services generate timelines of tweets, ads, and social recommendations based on multiple ranking heuristics. Despite this, Twitter still needs to serve timelines quickly.
Alongside the typical non-functional requirements of a large social media platform (consistency availability, reliability, and scalability), users expect new tweets to be served to their timelines in near real-time. When a breaking news story is developing, a media event is ongoing, or there’s a new meme, people converge on Twitter. The phrase “live-tweet” describes this platform-unique idea of a real-time stream of consciousness covering a relevant topic.
There are several ways that Twitter streamlines this process. Cached tweets can be quickly retrieved from Memcache, but the timeline system even prioritizes content that is proximally close, given a user’s social graph. That said, there is more that Twitter’s new system may be capable of.
How can Twitter serve timelines faster?
The most data-intensive, and budgetarily expensive, service provided by Twitter is building timelines. This cost is the current focus of many Twitter engineers. The old “Timeline mixer” service is being replaced with a significantly faster and simpler “Home Mixer”.
There is very little information publicly available as to how the new system will be faster, but Elon Musk tweeted that the current Timeline mixer is slow because of 1000s of remote procedure calls. In the above diagram of Twitter’s Home Mixer Architecture, you can see that the Timeline Mixer talks to the Timeline Scorer through Thrift remote procedure calls. Thrift is a communication protocol that is known to be fairly slow because of its method of serializing and deserializing data structures.
In the past, I was able to gain 10x or even 20x improvements in speed by removing Thrift and implementing static data structures where memory can be quickly typecast. It’s impossible to say for certain what Twitter’s goals are or how they’ll go about them, but it seems plausible that Twitter’s candidate ranking service, HomeRanker, will be key in achieving a significant increase in speed.
Serving timelines faster allows Twitter to:
- Support significantly more concurrent users without dips in performance.
- Lower computational work reduces operating costs.
Wrap up
I hope you enjoyed this deep dive into Twitter’s changing architecture. Twitter is a complex system, and there is a lot more to it than what we went through in this post. If you’re interested in learning more about how to design Twitter from scratch, check out our most advanced System Design course to date: Grokking Modern System Design Interview for Engineers and Managers. It breaks down all of the key building blocks of modern system design and outlines how to design some of the biggest and most complicated real-world large-scale distributed systems: YouTube, Instagram, Uber, and many more.
As always, happy learning!
Continue learning about System Design on Educative
- Simplify system design interviews with the RESHADED approach
- How to answer my favorite System Design question: Design Spotify
- The top 6 system design interview mistakes to avoid
Start a discussion
Which FAANG company’s architecture intrigues you the most? Was this article helpful? Let us know in the comments below!
Level Up Coding
Thanks for being a part of our community! Before you go:
- 👏 Clap for the story and follow the author 👉
- 📰 View more content in the Level Up Coding publication
- 🔔 Follow us: Twitter | LinkedIn | Newsletter
🚀👉 Join the Level Up talent collective and find an amazing job
What engineers need to know about Twitter’s design, new and old was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by The Educative Team
The Educative Team | Sciencx (2023-01-12T14:26:03+00:00) What engineers need to know about Twitter’s design, new and old. Retrieved from https://www.scien.cx/2023/01/12/what-engineers-need-to-know-about-twitters-design-new-and-old/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.