
This content originally appeared on Level Up Coding - Medium and was authored by Felix Gutierrez
Learning how to use AWS CLI and boto3 for data ingestion in AWS
Introduction
Nowadays many organizations use Amazon S3 as a primary storage destination for a wide variety of files (including AWS service logs). One of the benefits of storing data in S3 buckets, is that you can ingest it and then access it in any number of ways. One popular option for data ingestion to S3 is by writing scripts using Python, and then querying that data using Amazon Athena, a serverless query engine for data on S3.
In this tutorial we will get to know how these technologies can be used together in order to create data ingestion processes running in the cloud. We will extract data from an API, then we will store those tables in S# buckets using boto3, and then we will analyze that data within Amazon Athena.
In the first step of our ETL pipeline, we will do the ET part by extracting some US stocks market data from Yahoo Finance by using the pandas data reader package, then we will upload those extractions converted to pandas dataframes into an S3 bucket.
First things first, let’s get to know what the technologies involved in our extraction part.
Amazon S3: According to www.amazon.com Amazon Simple Storage Service or as it is popularly known S3 “is an object storage service offering industry-leading scalability, data availability, security, and performance. Customers of all sizes and industries can store and protect any amount of data for virtually any use case, such as data lakes, cloud-native applications, and mobile apps. With cost-effective storage classes and easy-to-use management features, you can optimize costs, organize data, and configure fine-tuned access controls to meet specific business, organizational, and compliance requirements.
Its uses go from building scalable and reliable data lakes as well as running cloud-native applications, to backing up and archiving critical data at a very low cost.
Its versatility also resides in the possibility to integrate it with some other cutting-edge technologies like Python, specifically speaking about boto3, this library allows developers to manage (create, update and delete) AWS resources directly from the command line, or even better include these configurations in Python scripts.
The following is a really good resource from Real Python in order to start learning about boto3 from scratch:
Python, Boto3, and AWS S3: Demystified - Real Python
Finally, according to www.amazon.com, “Amazon Athena is a serverless, interactive analytics service built on open-source frameworks, supporting open-table and file formats. Athena provides a simplified, flexible way to analyze petabytes of data where it lives. Analyze data or build applications from an Amazon Simple Storage Service (S3) data lake and 25+ data sources, including on-premises data sources or other cloud systems using SQL or Python. Athena is built on open-source Trino and Presto engines and Apache Spark frameworks, with no provisioning or configuration effort required.”
Without further ado, let’s get into the subject and start building an environment to extract data and then load and analyze it in the cloud.
Extracting data from API
As mentioned before we will be extracting data from pandas-datareader that enable developers to extract financial data from different internet sources as a pandas dataframe.
First we will need to install aws cli in our environment, library will enable us to have access from a Jupyter Notebook, for example, to the objects that we store in Amazon S3.
In order to install it just write from your terminalsudo apt install awscli
Finally you will run aws --versionto check that aws cli is successfully installed and aws configure in order to set up your aws user credentials in your home directory:

There is a very good article that shows how to completely configure aws cli and then configure more of its features:
Create an AWS S3 Bucket using AWS CLI
Then you will need to install the boto3 library into your environment by running pip install boto3 or pip3 install boto3 if you are in linux.
There are plenty of resources in Medium regarding how to use boto3 to manage S3 buckets, the following is one of them:
Introduction to Python’s Boto3
Maybe you would need first open a Jupyter Notebook and then import boto3, if you follow along boto3 documentation, the first step is to list your buckets:
import boto3
s3 = boto3.client('s3')
response = s3.list_buckets()
There you will receive a response as a JSON, then listing existing buckets in your AWS account is as simple as:
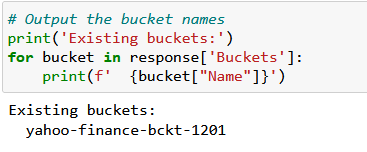
But if you don’t have any buckets, you will need to create them through your AWS account if self or through the aws cli, AWS documentation is clear enough on this matter:
Uploading, downloading, and working with objects in Amazon S3
Once you have set up your AWS bucket you can start doing remote requests to your AWS resources using aws cli or boto3. You will find the code to work with these in my GitHub repo.
Uploading data to S3
In this section of the ETL process we will use some functions that I wrote in Python, and some others are taken from boto3 documentation to load the data extracted from the API to our S3 bucket.
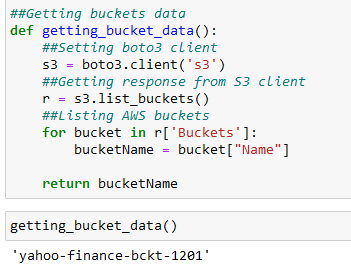
##Getting buckets data
def getting_bucket_data():
##Setting boto3 client
s3 = boto3.client('s3')
##Getting response from S3 client
r = s3.list_buckets()
##Listing AWS buckets
for bucket in r['Buckets']:
bucketName = bucket["Name"]
return bucketName
The above function would list all the buckets you have in your S3, in my case I just have created one:
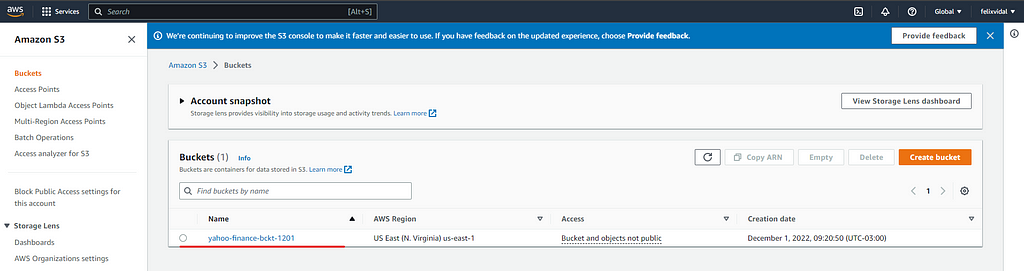
Now let’s look at the data that we just downloaded from the yahoo API and we store it in a local folder called data, you will have the following structure when you have cloned the repo:
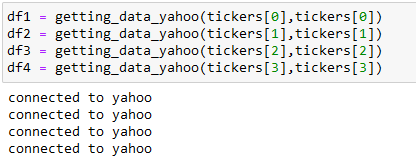
There I used this function to request the data from the API and store it locally on csv files:
def getting_data_yahoo(ticker,file_name,path=data_path):
# yahoo gives only daily historical data
connected = False
while not connected:
try:
df = web.get_data_yahoo(ticker, start=start_time, end=end_time)
connected = True
print('connected to yahoo')
except Exception as e:
print("type error: " + str(e))
time.sleep( 5 )
pass
# use numerical integer index instead of date
df = df.reset_index()
df.to_csv(f'{path}{file_name}.csv',index=False)
According to the function, we need to pass a ticker name (defined into a list in the notebook), and a file name that will have the output csv files as parameters of the function.
Let’s take a quick look at one of the downloaded files:
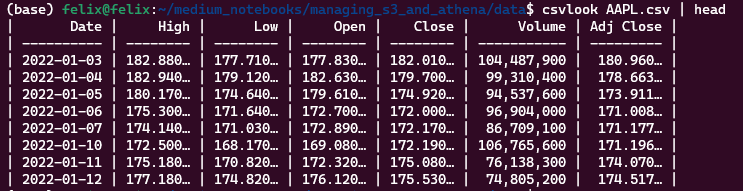
If you want to learn how to use csvlook just look at this article I wrote before:
Data Wrangling in the command line
Then this function taken from boto3 documentation will upload your csv files to your S3 bucket, passing file_name, and bucket_name as parameters:
def upload_files(file_name, bucket, object_name=None):
"""Upload a file to an S3 bucket
:param file_name: File to upload
:param bucket: Bucket to upload to
:param object_name: S3 object name. If not specified then file_name is used
:return: True if file was uploaded, else False
"""
# If S3 object_name was not specified, use file_name
if object_name is None:
object_name = os.path.basename(file_name)
# Upload the file
s3_client = boto3.client('s3')
try:
response = s3_client.upload_file(file_name, bucket, object_name)
except ClientError as e:
logging.error(e)
return False
return True
For the sake of simplicity let’s just load one of the csv files by passing file_name and bucket_name to the function, after that you will need to create a database and tables that will hold that data in Amazon Athena:
upload_file('AAPL.csv',bucketName)Once uploaded you will have the following structure in your bucket:
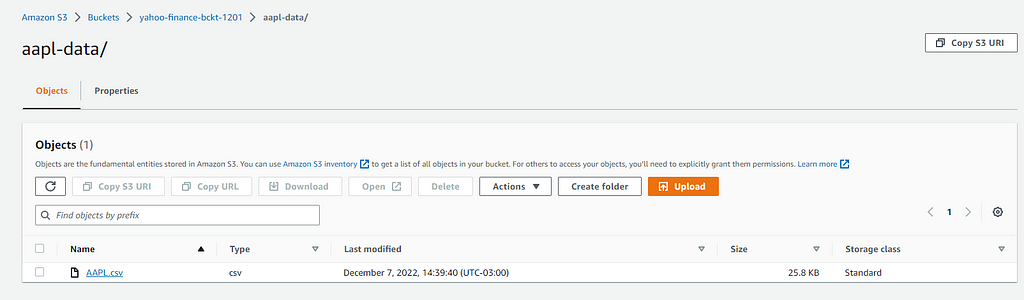
Interpreting data in Athena
In order to manage the data that we stored in S3 we will use Athena, first you will create a database by accessing Athena service in your AWS account:
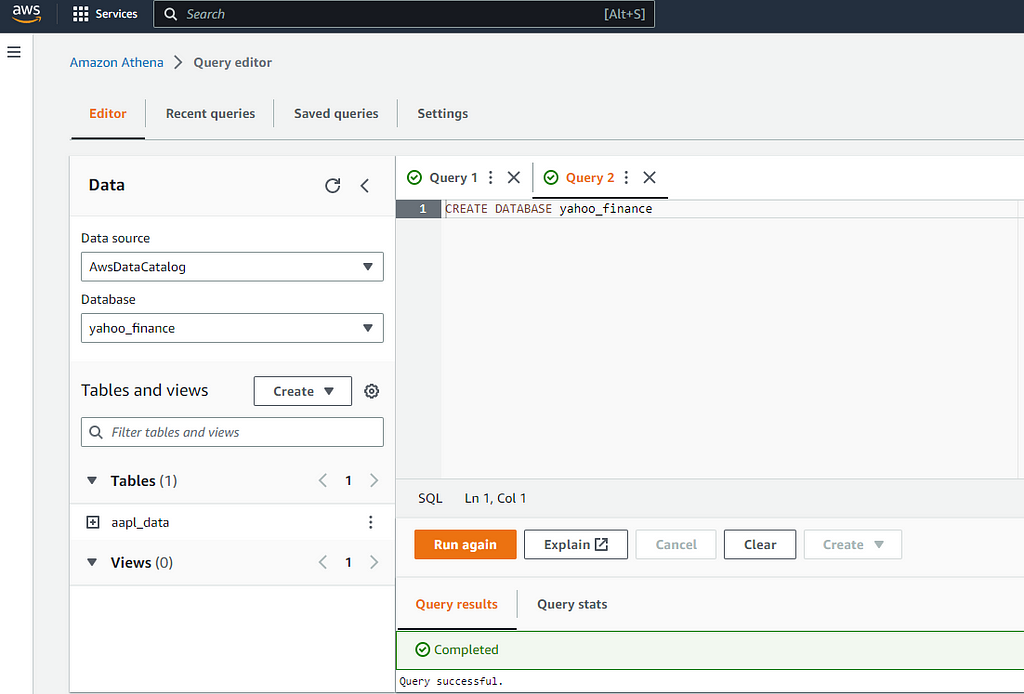
Before you get into this point, I strongly recommend you follow the Getting Started Guide for Athena on AWS official documentation:
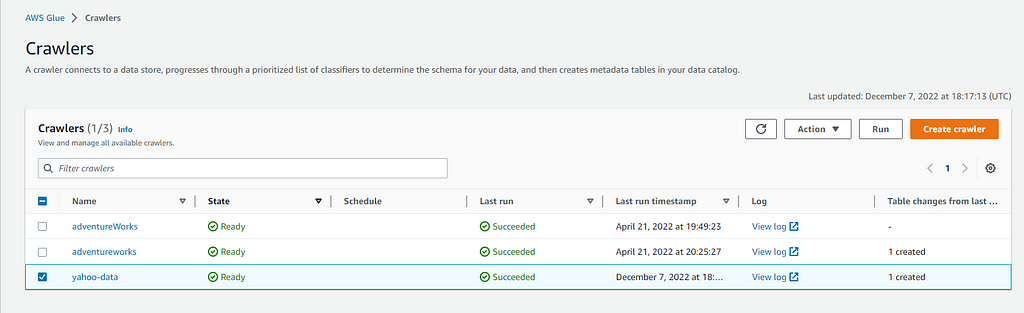
Once you created your database now you’ll need to create some new tables based on sample data stored in S3, the best and easy approach is to create a crawler that will do all the job of loading tha data stored in S3 to your Athena database, follow this tutorial that shows you how to configure your crawler:
Connect CSV Data in S3 Bucket with Athena Database
When your crawler does the job you will have the data in your newly created table:
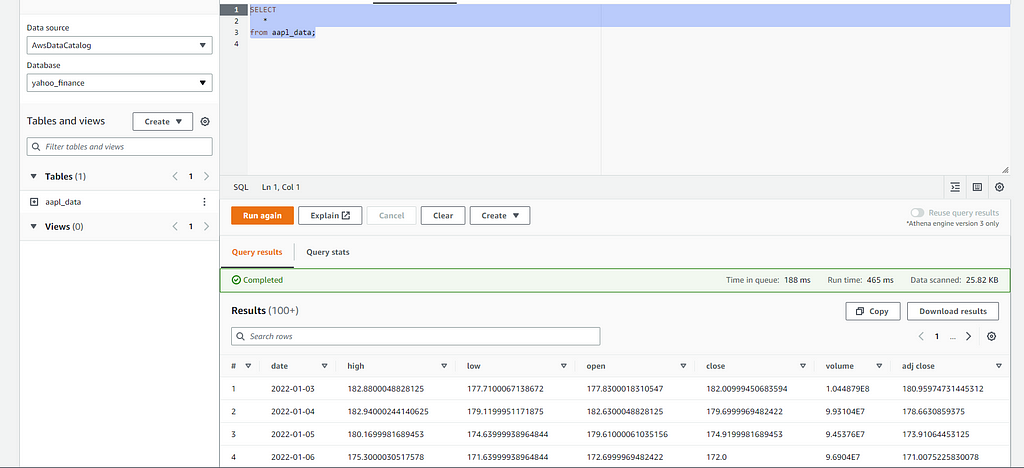
From that point you can start doing some queries over that data in Athena or if desired you can connect that database with your favorite Data Visualization platform like Tableau or Amazon Quicksight in order to generate some metrics and statistics.
Conclusion
Amazon S3 and Athena are both excellent resources that allow developers to create reliable applications in the cloud, based on unstructured and structured data, that can be loaded using python with the boto3 package. Then in Athena you can start running ad-hoc queries using ANSI SQL. Athena also integrates with Amazon Quicksight for easy data visualization and then generate reports or explore data with business intelligence tools.
Some other resources to follow and happy coding in the cloud!!
Loading Data from S3 to AWS Athena was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Felix Gutierrez
Felix Gutierrez | Sciencx (2023-02-03T16:13:35+00:00) Loading Data from S3 to AWS Athena. Retrieved from https://www.scien.cx/2023/02/03/loading-data-from-s3-to-aws-athena/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.