
This content originally appeared on DEV Community 👩💻👨💻 and was authored by Vladyslav Budichenko
Overview
Web scraping is a powerful tool for extracting information from websites. With web scraping, you can gather data from websites and use it for a variety of purposes, such as data analysis, machine learning, and research. The process of web scraping involves making HTTP requests to a website, parsing the HTML content, and extracting the desired information.
Go is a popular programming language that is well-suited for web scraping due to its efficiency, scalability, and built-in libraries. In this article, we will explore the process of web scraping using Go and learn the best programming practices for extracting information from websites.
Whether you are a seasoned developer or a beginner, this article will provide you with the knowledge and resources you need to get started with web scraping using Go. So let's dive in and learn how to extract information from websites with Go!
If you don't want to read more similar tutorials subscribe to the newsletter in TheDevBook.
Now let's take a look at scraping.

Trustpilot page overview for scraping
Before we start writing code to extract information from a website, it is important to understand the structure of the page we are going to parse.
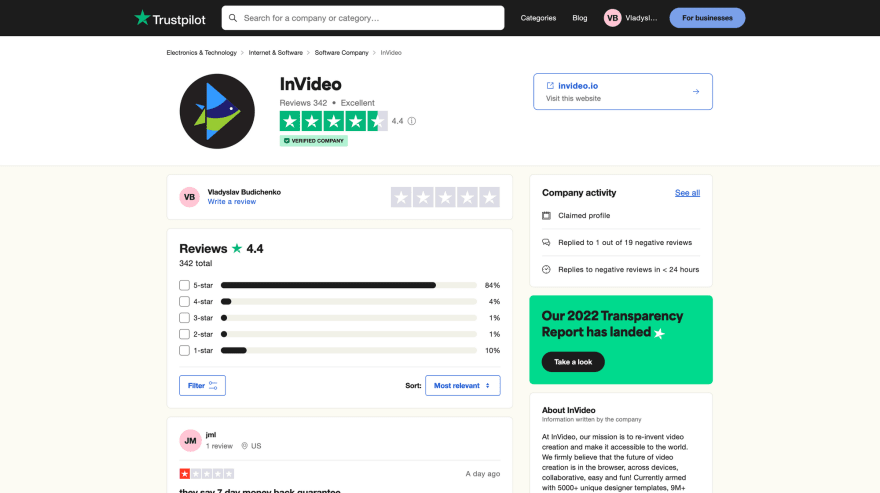
The HTML source code of a website defines the structure, layout, and content of the page. To inspect the HTML source code of a website, right-click anywhere on the page and select "Inspect" (both Chrome and Firefox).

This will open development tools with all the HTML code that makes up the page.

Once we have the HTML source code, we need to identify the information we want to extract. The basics of the HTML is not a goal of the article, but for more information there are good explanation from Mozilla or W3Schools.
From the page structure we can see, that each review that card is a div element with classes styles_cardWrapper__LcCPA and styles_reviewCard__9HxJJ. That means we can extract the card by using a queries, like jQuery to extract the particular block. After that we can extract the text, that contains in the block and save it as a review data.
Generally, by understanding the HTML structure and using HTML selectors, we can extract the information we want from a website. In the next sections, we will learn how to write Go code to make HTTP requests, parse HTML, and extract data.
Scraping tools in Go
There are several different libraries, that are commonly used for web scraping in Go:
- net/http - standard library in Go that provides the ability to make HTTP requests and receive HTTP responses. It is a low-level library, which means that it requires a bit more code to use than some other libraries, but it is also very flexible and can be used for any type of HTTP request.
- github.com/gocolly/colly - popular and widely-used library for web scraping in Go. It provides a higher-level API than net/http and makes it easier to extract information from websites. It also provides features such as concurrency, automatic request retries, and support for cookies and sessions.
- github.com/PuerkitoBio/goquery - library that provides a convenient and concise way to query HTML and XML documents. It provides a jQuery-like API for selecting elements and extracting data, making it a popular choice for web scraping in Go.
- github.com/yhat/scrape - library that provides a convenient and flexible way to extract information from websites. It provides a high-level API that makes it easy to extract specific elements from a web page, and it also supports custom extractors for more complex scraping tasks.
In the tutorial, we are going to use simple net/http for requesting pages and github.com/PuerkitoBio/goquery to make queries for the HTML document.
Scraping the page
Let's go top-down through the code idea.

First, we need to identify the review internal structure. We checked that it should contain fields like text, date, title, etc, so let's create a Go representation of the Review and all product Reviews structure:
type Review struct {
Text string `json:"text"`
Date string `json:"date"`
Rating string `json:"rating"`
Title string `json:"title"`
Link string `json:"link"`
}
type ProductReviews struct {
ProductName string `json:"product_name"`
Reviews []*Review `json:"reviews"`
}
It is JSON serializable using go json tags.
For the purpose of the article, let's get the particular product invideo.io and extract it with URL constant as a separate section:
const (
scrapingURL = "https://www.trustpilot.com/review/%s"
scrapingPageURL = "https://www.trustpilot.com/review/%s?page=%d"
productName = "invideo.io"
)
Now let's write a main function with a general idea of what we need:
func main() {
log.Printf("Start scraping reviews for %s", productName)
productReviews, err := getProductReviews(productName)
if err != nil {
log.Fatal(err)
}
jsonFile, err := os.Create(fmt.Sprintf("trustpilot_reviews_%s.json", productName))
if err != nil {
log.Fatal(err)
}
defer jsonFile.Close()
jsonEncoder := json.NewEncoder(jsonFile)
err = jsonEncoder.Encode(productReviews)
if err != nil {
log.Fatal(err)
}
log.Printf("Successfully scraped %d reviews for %s", len(productReviews.Reviews), productName)
}
We get all the reviews using getProductReviews function and after that save them into a JSON file. Now we need to create a function to extract all reviews for a particular product. First, we need to get the HTLM page and transform it into a goquery document:
productURL := fmt.Sprintf(scrapingURL, name)
// make a request to the product page
res, err := http.Get(productURL)
if err != nil {
return nil, err
}
defer res.Body.Close()
// transform the HTML document into a goquery document which will allow us to use a jquery-like syntax
doc, err := goquery.NewDocumentFromReader(res.Body)
if err != nil {
return nil, err
}
Note: Trustpilot doesn't block simple requests at the moment of writing the article, but many big services will block such requests, as it's definitely done not via browser user. In such a case we need to use another approach to extracting page URLs, like using scraping tools or headless browsers and proxies.
After extracting the document we can need to prepare a reviews slice, where we want to store all the reviews. As we are going to make requests to Trustpilot in parallel for different pages and slice if not concurrency safe (that means we cannot simply write into it in parallel, as it causes data race conditions), we need a mechanism to synchronize the data. Here, we are going to use channels.
reviews := make([]*Review, 0)
// we synchronize reviews processing with a channel, as we scrape reviews from multiple pages in parallel
reviewsChan := make(chan *Review)
quitChan := make(chan struct{})
// we append reviews in a separate goroutine from reviewsChan
go func() {
for review := range reviewsChan {
reviews = append(reviews, review)
}
close(quitChan)
}()
Now we can use goquery the document we created and extract elements we are interested in, particularly all div elements that contain classes with prefixes styles_reviewCard__ and styles_cardWrapper__. Let's extract all the div and process them:
// to avoid one extra request, we process first page here separately
doc.Find("div").Each(extractReviewFunc(reviewsChan, productURL))
Let's dive deep into the extractReviewFunc function. In the implementation, we filter classes of the page element and identify if it contains necessary prefixes:
classes, exists := s.Attr("class")
if !exists {
return
}
// validate if the div is a review card and a card wrapper (to avoid processing other divs, like advertisement)
isReviewCard := false
isCardWrapper := false
for _, class := range strings.Split(classes, " ") {
if strings.HasPrefix(class, "styles_reviewCard__") {
isReviewCard = true
}
if strings.HasPrefix(class, "styles_cardWrapper__") {
isCardWrapper = true
}
}
if !isReviewCard || !isCardWrapper {
return
}
If it is a review card, we can extract all the necessary information using the element selection and send it to reviewsChan:
// extract review data
dateOfPost := s.Find("time").AttrOr("datetime", "")
textOfReview := s.Find("p[data-service-review-text-typography]").Text()
title := s.Find("h2").Text()
link, _ := s.Find("a[data-review-title-typography]").Attr("href")
if link != "" {
link = productURL + link
}
// we don't transform the data in place, as we want to keep the original data for future analysis
rating := s.Find("img").AttrOr("alt", "")
reviews <- &Review{
Text: textOfReview,
Date: dateOfPost,
Rating: rating,
Title: title,
Link: link,
}
As doc.Find("div").Each takes a func(i int, s *goquery.Selection) as input, and we use external parameters inside the function, particularly reviewsChan and productURL, we need to wrap such a function into another function that can return it. It's a common pattern in Go when we need to create a function with a predefined signature and pass specific parameters to use inside it.
func extractReviewFunc(reviews chan<- *Review, productURL string) func(i int, s *goquery.Selection) {
return func(i int, s *goquery.Selection) {
// our function code here
}
}
The whole function code looks like
func extractReviewFunc(reviews chan<- *Review, productURL string) func(i int, s *goquery.Selection) {
return func(i int, s *goquery.Selection) {
classes, exists := s.Attr("class")
if !exists {
return
}
// validate if the div is a review card and a card wrapper (to avoid processing other divs, like advertisement)
isReviewCard := false
isCardWrapper := false
for _, class := range strings.Split(classes, " ") {
if strings.HasPrefix(class, "styles_reviewCard__") {
isReviewCard = true
}
if strings.HasPrefix(class, "styles_cardWrapper__") {
isCardWrapper = true
}
}
if !isReviewCard || !isCardWrapper {
return
}
// extract review data
dateOfPost := s.Find("time").AttrOr("datetime", "")
textOfReview := s.Find("p[data-service-review-text-typography]").Text()
title := s.Find("h2").Text()
link, _ := s.Find("a[data-review-title-typography]").Attr("href")
if link != "" {
link = productURL + link
}
// we don't transform the data in place, as we want to keep the original data for future analysis
rating := s.Find("img").AttrOr("alt", "")
reviews <- &Review{
Text: textOfReview,
Date: dateOfPost,
Rating: rating,
Title: title,
Link: link,
}
}
}
Now we need only extract the number of pages and run the same logic for other pages with reviews, as they have the same HTML structure. For that we need to process a pagination link element:
// we need to find a link to last page and extract the number of pages for the product
doc.Find("a[name='pagination-button-last']").Each(extractReviewsOverPagesFunc(reviewsChan, name))
For extractReviewsOverPagesFunc we use a similar approach, as we did for extractReviewFunc. We extract a href attribute of our a element and using regular expressions to get to the last page of the product.
href, exists := s.Attr("href")
if !exists {
return
}
// we need to find a link to pages and extract the number of pages for the product
match, err := regexp.MatchString("page=\\d+", href)
if err != nil || !match {
return
}
re := regexp.MustCompile("\\d+")
lastPage := re.FindString(href)
lastPageInt, err := strconv.Atoi(lastPage)
if err != nil {
log.Printf("Cannot parse last page %s: %s\n", lastPage, err)
return
}
When we know the number of pages we need to process, we can do that in parallel using wait groups to wait while all goroutines finish.
// scrape all pages in parallel
wg := &sync.WaitGroup{}
for i := 2; i <= lastPageInt; i++ {
wg.Add(1)
go func(pageNumber int) {
defer wg.Done()
pageReviews, err := getPageProductReviews(name, pageNumber)
if err != nil {
log.Printf("Cannot get page %d product reviews: %s", pageNumber, err)
return
}
for _, review := range pageReviews {
reviews <- review
}
}(i)
}
wg.Wait()
We start from the second page, as the first one (the current page, from where we extracted the last page) was already processed.
The getPageProductReviews is a similar function, as getProductReviews but we don't extract a last link to get all pages:
func getPageProductReviews(name string, page int) ([]*Review, error) {
log.Printf("Start scraping page %d for %s", page, name)
// productURL is used to construct a link to the review. It's pure, without query params
productURL := fmt.Sprintf(scrapingURL, name)
// actual request URL for scraping a page
productRequestURL := fmt.Sprintf(scrapingPageURL, name, page)
res, err := http.Get(productRequestURL)
if err != nil {
return nil, err
}
defer res.Body.Close()
doc, err := goquery.NewDocumentFromReader(res.Body)
if err != nil {
return nil, err
}
reviews := make([]*Review, 0)
reviewsChan := make(chan *Review)
quitChan := make(chan struct{})
go func() {
for review := range reviewsChan {
reviews = append(reviews, review)
}
close(quitChan)
}()
// extract reviews from the page
doc.Find("div").Each(extractReviewFunc(reviewsChan, productURL))
close(reviewsChan)
<-quitChan
return reviews, nil
}
As we can notice, there is one thing we didn't mention in the function getPageProductReviews yet, particularly the channels synchronization part:
close(reviewsChan)
<-quitChan
After running all goroutines, we close the reviewsChan, as we won't write into it anymore and wait until we process all the reviews and save them into reviews slice.
Basically, that's it. We now can extract reviews and dump them into a JSON object for future analysis. The final code can be found on GitHub.
Let's run it and check the data. After execution, there is a new file trustpilot_reviews_invideo.io.json. There is a bunch of data, and it looks like
{
"product_name": "invideo.io",
"reviews": [
{
"text": "excellent application, a bit expensive for my economic situation but if you have the money it is an application that will help you in a simple way in editing videos",
"date": "2023-01-26T01:10:22.000Z",
"rating": "",
"title": "excellent application",
"link": "https://www.trustpilot.com/review/invideo.io/reviews/63d1b6de9b64b1bdaf432bef"
},
...
]
}
Conclusion
In this article, we have covered the basics of web scraping and how to parse Trustpilot reviews using Go. We've discovered how to check the HTML structure of a particular website, identify the necessary elements we need to extract the data, and explored some of the most popular libraries for web scraping in Go.
As we move forward, I encourage you to continue learning and experimenting with web scraping. This is a powerful and valuable skill, and there are endless opportunities to apply it in your work and personal projects, like lead generation, trends analysis, generally gathering databases for data analysis, etc.
If you want to not miss other similar articles, sign up for the newsletter in TheDevBook.

This content originally appeared on DEV Community 👩💻👨💻 and was authored by Vladyslav Budichenko
Vladyslav Budichenko | Sciencx (2023-02-04T22:25:37+00:00) Learn how to scrape Trustpilot reviews using Go. Retrieved from https://www.scien.cx/2023/02/04/learn-how-to-scrape-trustpilot-reviews-using-go/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.