
This content originally appeared on DEV Community 👩💻👨💻 and was authored by Pedro F Marquez
NodeJS is an excellent tool to quickly set up small services like HTTP servers thanks to its ease of integration with other libraries like SSR for web frameworks and NoSQL databases like MongoDB.
However, due to its interpreted nature, JavaScript is not the right tool for memory-intensive tasks. Other compiled languages like Golang get the upper hand for some tasks, as they are optimized for them. It would be awesome if we could get the best of both worlds, isn't it? Enter WebAssembly.
Brief disclaimer
The example explained in this post -as most WebAssmebly-specific libraries are at this point in time- is based on some experiment libraries, which are subject to changes in the future. This doesn't mean you cannot use them in production, but you should be aware that the APIs of these libraries are not guaranteed to be backward compatible in future releases and extra refactoring work may be needed when updating versions of Go or NodeJS.
Some background
JavaScript is an interpreted language. This means that, due to its dynamic typing nature, the application cannot make assumptions about what type of data will be used at run time: A variable passed to a function could be a string, an object or even a function.
While dynamic typing provides a lot of flexibility to developers, the interpreter executing the code cannot optimize the code ahead of time. This is why JavaScript engines like those used in browsers perform Just-in-time (JIT) optimization.
JIT essentially is a caching strategy over the code and the specific types used in it. As code is interpreted and executed, the JIT compiler will keep track of the types used in the code, convert it to bytecode (low-level instructions) and use this optimized version of the code the next time this code is called.
While JIT performs many other specific improvements, in general, this is its goal: Compile the JavaScript code into optimized instructions. Thanks to JIT compilation, engines like browsers can execute interpreted code at almost native code speeds (the keyword being almost). And here lies the advantage of compiled languages like Go: Their strongly typed nature (among other language-specific characteristics) allows compilers to perform all optimizations ahead of time, resulting in applications that only need to execute bytecode.
WebAssembly
WebAssembly (WASM) is a specification that allows us to write code that can be fully compiled and optimized ahead of time, and use the compiled code in environments where typically interpreted languages are used, like browsers or in server-side interpreted engines.
WASM features
- Fast. WASM-compiled code is almost as fast as natively compiled applications. This allows us to run memory-intensive applications that typically would be impossible to run in low-resources clients like browsers or IoT devices.
- Secure. WASM modules only have access to a linear set of memory, sandboxed from the rest of the application. This reduces the risk of having malicious code accessing data or resources they shouldn't.
- Portable. WASM works as a container (or VM), which allows it to compile bytecode that can be run in multiple architectures: Browsers, mobile devices, and backend servers; as long as it supports the WASM specification, it can execute WASM code.
- Flexible. WASM itself is a compilation target. This means that, potentially, you can use any programming language to write code, and produce bytecode that can run almost everywhere.
WASM limitations
The same isolation and flexibility that provides most of WASM's strengths are the cause of most of its limitations:
- WASM doesn't provide a default memory management (e.g. Garbage Collection) mechanism. This means that, currently, each WASM module needs to be shipped with its memory management code. (This is one of the reasons why Rust shines for WASM modules, as its memory management it's baked into the language)
- Communication between the WASM module and the rest of the application needs to be done in very simple types (bytes, ints and floats). No complex types are supported yet. This is why most WASM compilers also provide some glue-code to map between complex types like strings or arrays. The Web Assembly System Interface (WAS) is an on-progress standard aimed to solve this last limitation; once it's mature it will allow easy interoperation with almost every environment. WASI is already available in some WSAM compilers and runtimes.
The use case: Log tailing
Most WASM examples are simple "Hello World". For this post, I thought it was useful to see a more specific use case, a problem that I've found in the past.
Imagine you have a deployed application that is logging output into a text file. We want to parse each line in this file in real-time, as it is written to it, and send it somewhere to be parsed, displayed and/or stored. Existing tools like Logstash already provide this functionality, but we want to write something ourselves that give us control over the parsing process.
First, let's create a simple NodeJS script named logger.js to simulate the creation of this log file:
const fs = require('fs')
const util = require('util')
var logFile = fs.createWriteStream('test.log', { flags: 'a' })
function log() {
// console.log(...arguments);
logFile.write(util.format.apply(null, arguments) + '\n')
}
function randomElement(arr) {
return arr[Math.floor(Math.random() * arr.length)]
}
function randomTime() {
const time = [1000, 100, 3000, 0]
return randomElement(time)
}
function randomLevel() {
const levels = ['WARN', 'INFO', 'ERROR']
return randomElement(levels)
}
let i = 0
function startLogger() {
log(`${randomLevel()} Log number ${i++}`)
setTimeout(() => {
startLogger()
}, randomTime())
}
startLogger()
First, we create a NodeJS ReadStream using fs.createWriteStream to open the test.log file in "append" mode. Then we start recursively looping using setTimeout. This simulates an application that logs text in the file at a variable rate. At each iteration:
- We print some simple text with a random log level from
{'WARN', 'INFO', 'ERROR'}to the log file. - We randomly pick the number of milliseconds from
{1000, 100, 3000, 0}to wait for the next iteration.
Reading the log file in Go
We will write our module in Go. Go offers native WASM compilation without the need of installing other libraries or compilers.
Enabling the output of complex types
As I mentioned before, WASM modules cannot output complex types, so if we want to be able to send out something other than numbers or bytes, we need some "glue" code that takes care of mapping types like strings and slices into bytes. The Go repository offers the very convenient wasm_exec.js, which will allow our WASM module to communicate with the outside world.
The wasm_exec.js script as it is has some limitations:
- It was created to be used on browsers. We can work around this fact by making some small changes to the script to make it compatible with NodeJS. We will define these changes in the next post.
- It doesn't support custom data structures. This makes sense, as our WASM module would have to export some sort of schema so whoever consumes the module knows how to parse the output. However,
wasm_exect.jsdoes support slices and maps, which allows us to marshal our Go-defined structures into objects likemap[string]interface{}.
Our current example differs from other simpler examples in the fact that we will not just output a single result from the WASM module. We want to be able to send parsed logs back to NodeJS as they are appended to the log file.
We could use polling to repeatedly call the WASM module to retrieve the latest logs, but this is not an optimal approach, as it requires fine-tuning to get the logs in real-time without excessive memory consumption.
A better approach is to use a callback: We define a function in NodeJS that can be called from the WASM module every time new logs are parsed and ready to be consumed.
The Go code
First, we create a new Go module:
go mod init wasm-test.com
In the same folder where the go.mod file was created, we create wasm.go.
First, we will define the types of our output. For convenience, we will create a new type called ParsedLogs, which is just an alias for map[string]interface{}.
type ParsedLogs = map[string]interface{}
Now, let's define a function that has only one responsibility: Sending the output back to NodeJS. However, since we want to test that everything works without having to compile and deploy the module, for now, our callback will just print the parsed logs into the console:
func ModuleOutput(parsedLogs ParsedLogs) {
fmt.Println(parsedLogs)
}
type OutputCallback = func(parsedLogs ParsedLogs)
The OutputCallback is another alias we create just for convenience, so we don't have to use the verbose func(parsedLogs ParsedLogs) when we pass our function as a parameter to the main process.
Now, we define two functions: main, which is the entry point to the module, and Execute, which will contain the actual log parsing logic:
func Execute(callbackFn OutputCallback) {
//... call callbackFn to send parsed logs
}
func main() {
Execute(ModuleOutput)
}
Reading the log file
It's time to extend the Execute function to read our log file. For this example, we will hard-code the path to the log file, but you could pass this as a parameter, or retrieve it from a global function defined in NodeJS.
func Execute(callbackFn OutputCallback) {
file, err := os.Open("./test.log")
if err != nil {
log.Fatal(err)
}
defer file.Close()
acc := NewAccumulator()
defer close(acc.out)
go func() {
for {
select {
case str := <-acc.out:
l := parse(str)
callbackFn(l.ToMap())
case <-time.After(2 * time.Second):
acc.Flush()
}
}
}()
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n')
if err != nil {
if err == io.EOF {
time.Sleep(500 * time.Millisecond)
continue
}
log.Fatal(err)
}
acc.Append(line)
}
}
There are a lot of things going on in here, so let's break them down.
First, we open our log file, making sure we defer its close function:
file, err := os.Open("./test.log")
if err != nil {
log.Fatal(err)
}
defer file.Close()
Then, we create an instance of Accumulator -a structure we haven't defined yet, but will take care of aggregating logs as they are printed-:
acc := NewAccumulator()
defer close(acc.out)
Now, the rest of the code does two things in parallel:
- In a loop, it reads the log file, one line at a time, and sends it to the
Accumulator. - In another loop, it checks the contents of
Accumulator, and if there are processed logs ready to be sent out, it calls the output callback passing with the parsed logs as a parameter.
Counterintuitively, the first loop can be seen at the end of the function:
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n')
if err != nil {
if err == io.EOF {
time.Sleep(500 * time.Millisecond)
continue
}
log.Fatal(err)
}
acc.Append(line)
}
We create a file reader, and inside the infinite loop, we read the file one line at a time. If the file reader reaches the end of the file (which happens when ReadString returns io.EOF as an error), we just pause the process for half a second before checking again if the file has new log entries. This call to time.Sleep is critical, otherwise, the loop would be executed at full-speed, consuming more memory than needed.
When the reader outputs a new line, we just add it to the Accumulator.
We execute the second loop inside a goroutine, which will allow us to have another infinite loop running in parallel.
go func() {
for {
select {
case str := <-acc.out:
l := parse(str)
callbackFn(l.ToMap())
case <-time.After(2 * time.Second):
acc.Flush()
}
}
}()
Inside this loop, we check the Accumulator's attribute out, which is a go channel. If the channel has a new log entry, we process it using the parse function -which we will define next-, and we will send the processed result to the output callback.
We will explain what the second case inside the select block does in the following section.
The accumulator
One thing to notice is that some log entries don't fit in a single line. If we tried to parse each line in the text file in isolation, we wouldn't be able to parse some of them as they are a continuation of the previous line. To solve this challenge, we will accumulate each line into an instance of strings.Builder.
We see that independent log entries contain a log level like WARN or ERROR. This helps us to identify if a line is the beginning of a new log entry or part of the previous line.
The Accumulator struct is basically a wrapper around strings.Builder:
var r, _ = regexp.Compile("(WARN|ERROR|INFO) (.+)")
type Accumulator struct {
sb strings.Builder
out chan string
}
func NewAccumulator() Accumulator {
return Accumulator{sb: strings.Builder{}, out: make(chan string, 10)}
}
func (a *Accumulator) Append(str string) {
if r.MatchString(str) {
a.Flush()
}
a.sb.WriteString(str)
}
func (a *Accumulator) Flush() {
if a.sb.Len() > 0 {
res := a.sb.String()
go func(res string) {
a.out <- res
}(res)
a.sb = strings.Builder{}
}
}
We use the Append function to add a new line to the Accumulator. Inside this function, we check if the log contains the words ERROR, WARN or INFO; if they don't match, we append them to the string builder. However, if they match, we call the Flush function.
The Flush function checks if the string builder is empty. If it's not, it will convert it to a string, and send it to the out go channel. It then clears the string builder by creating a new instance, making it ready to start receiving new lines from the log file.
Now, remember we were also calling Accumulator.Flush in the infinite loop that reads the output of the out channel:
select {
case str := <-acc.out:
l := parse(str)
callbackFn(l.ToMap())
case <-time.After(2 * time.Second):
acc.Flush()
}
This is because the accumulator itself only calls Flush when it receives a new line of text. If we only called Flush inside Append, the Accumulator would wait to output the latest log entry until the log file has new content, which would result in always missing the last entry from the output.
For instance, if our log file only contained the following line:
WARN - Hello
And then a second line is added:
WARN - Hello
ERROR - Something awful happened!
The first line will be sent to NodeJS when the second one is appended. But the second line itself would remain inside the Accumulator. If the process stops sending logs completely, the NodeJS code would never see the second line.
However, since our code is calling Flush every 2 seconds after not receiving new processed logs, the second entry will be processed and sent back to NodeJS.
Parsing the logs
The code used to parse the logs is pretty straightforward. It addresses the simple formatting of the log entries in our example, but you can easily extend it to parse more complex patterns:
We create a simple Log structure, which has a function ToMap, which returns an instance of ParsedLogs -the alias we previously defined for map[string]interface{}-.
type Log struct {
Level string
Msg string
}
func (l Log) ToMap() ParsedLogs {
m := make(map[string]interface{})
m["level"] = l.Level
m["msg"] = l.Msg
return m
}
Then, we finally define the parse function which we called in our goroutine. This function uses Regex to parse the log level from the entry and the text that follows it. It creates an instance of Log and fills its attributes with the values parsed from the Regex.
func parse(str string) Log {
log := Log{}
if !r.MatchString(str) {
log.Msg = str
return log
}
groups := r.FindStringSubmatch(str)
log.Level = groups[1]
log.Msg = groups[2]
return log
}
Technically we didn't need to define a new structure, as we can easily output a map[string]interface{} directly. However, the extra abstraction gives us a placeholder if we needed to perform extra parsing logic.
Now, we can test our code works by running logger.js and wasm.go in parallel:
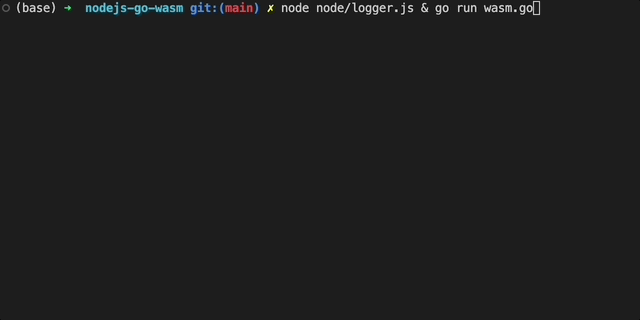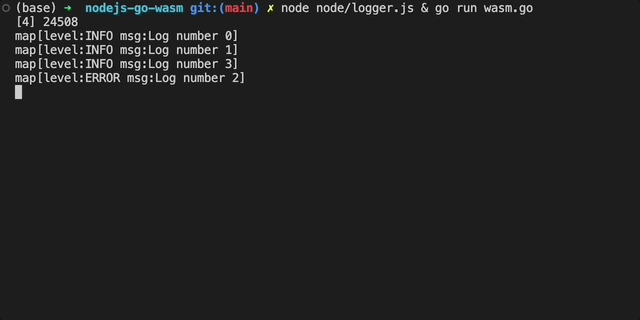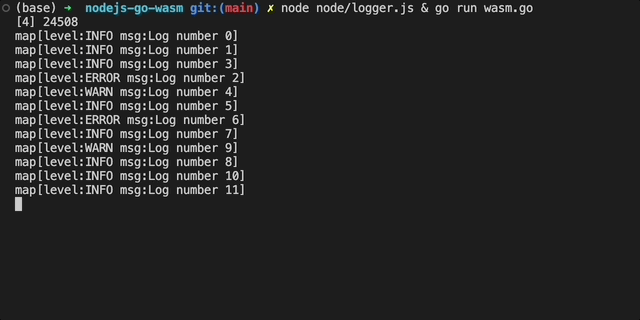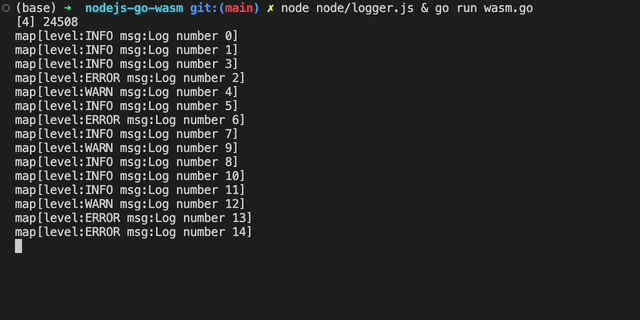
Now it's time to update our Go code to be compiled as a WASM module.
The syscall/js module
We will import the go module "syscall/js", which is defined in its docs as follows:
Package js gives access to the WebAssembly host environment when using the js/wasm architecture. Its API is based on JavaScript semantics.
This package is EXPERIMENTAL. Its current scope is only to allow tests to run, but not yet to provide a comprehensive API for users. It is exempt from the Go compatibility promise.
In essence, this library allows us to communicate with the NodeJS code that will execute our WASM module.
From syscall/js we can get references to global variables inside NodeJS. Then, we can define a function in NodeJS like this:
globalThis.logCallback = () => {
/* ... */
}
And then, inside our Go code, we can get a reference to that function as follows:
func ModuleOutput(parsedLogs ParsedLogs) {
logCallback := js.Global().Get("logCallback")
logCallback.Invoke(parsedLogs)
}
One thing you will notice is that syscall/js is only available for the WASM architecture. If we now try to run our Go module with go run, we will see an error message like the following:
package command-line-arguments
imports syscall/js: build constraints exclude all Go files in /usr/local/go/src/syscall/js
As soon as we import syscall/js, the compiler constraints the type of architectures this module can be built fo.
This is the reason why we didn't call js.Global() directly inside Execute; it decouples most of the code from WASM-specific dependencies, which makes them easier to reuse in non-WASM applications.
If we want to execute our code now, we will have to compile it into WebAssmebly bytecode; this can be done with the following command:
GOOS=js GOARCH=wasm go build -o app.wasm
By setting the GOARCH environment variable to wasm, the module now will compile successfully. In addition, the GOOS=js environment variable lets the compiler know we will use this WASM module in JavaScript.
If the go build command completes successfully, you should see a new file named app.wasm in the root folder. This is the WASM module we will import in NodeJS.
In the next blog post we will explore the second part of this process: Importing the compiled WASM module inside a NodeJS app.
Conclusion
With the current capabilities of NodeJS and Golang, it is now possible to use WebAssembly as a way to create code modules that perform almost as well as native code does, and enable functionality that historically has been prohibitive in terms of memory and execution time in interpreted languages like JavaScript.
We have seen that Golang offers compilation support for WASM out of the box. In this example we used native Go features like Go channels and goroutines, making the point that those can operate well in the context of WebAssembly.
One important thing to notice before we end is that executing WASM in NodeJS -instead of a browser like more common examples do- gives us access to host-specific libraries like fs to read files and to a memory runtime. All these things are not directly available in the browser's JavaScript engines, which means the WASM module we created in this example would not run there.
However, there are other, more fleshed-out, libraries like wasmer-go that provides a runtime and help us navigate around these limitations. The wasmer-go documentation provides a good summary of these challenges:
The major problem is that, whilst the Go compiler supports WebAssembly, it does not support WASI (WebAssembly System Interface). It generates an ABI that is deeply tied to JavaScript, and one needs to use the wasm_exec.js file provided by the Go toolchain, which doesn't work outside a JavaScript host.
Then, it is important to point out that our example only works in NodeJS. The compiled WASM module cannot be used in other WASM-enabled environments. Regardless, we can take the same code and use tools like wasmer-go or tinygo and this limitation can be worked around.
WebAssembly has a promising future as a standard to modularize interoperable code. We can expect that future improvements around the specification (especially with WASI) will open the door to using WASM for creating embeddable containers of functionality that can be imported in almost any environment from the browser and backend servers to edge-computing devices like those in IoT.
This content originally appeared on DEV Community 👩💻👨💻 and was authored by Pedro F Marquez
Pedro F Marquez | Sciencx (2023-02-13T18:01:00+00:00) Running Go code inside a NodeJS app with WASM (Part 1/2, 2023). Retrieved from https://www.scien.cx/2023/02/13/running-go-code-inside-a-nodejs-app-with-wasm-part-1-2-2023/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.