
This content originally appeared on Level Up Coding - Medium and was authored by Yeyu Huang
Use these mature tools to accelerate your modeling process

Automated machine learning, also known as automated ML or AutoML, streamlines the iteration process involved in developing machine learning models. By automating these processes, data scientists, analysts, and developers can construct ML models more quickly and productively, without sacrificing quality. Their enhanced efficiency and scalability make automated machine learning a valuable tool for any organization seeking to harness the power of machine learning.
Python has a growing ecosystem of open-source AutoML libraries. This article outlines the most popular and practical AutoML libraries by now, including many enterprise-level application tools.
1. PyCaret
PyCaret is an open-source, low-code machine learning library in Python that automates machine learning workflows. It is also an end-to-end machine learning and model management tool, which can exponentially accelerate the experiment cycle and improve development efficiency.

Compared with other open-source machine learning libraries, PyCaret has obvious low-code characteristics. It can use only a few lines of code to complete the work that originally required hundreds of lines of code, especially for the intensive experiments and iteration process, which can be greatly accelerated. Actually, PyCaret is packaged from multiple machine learning libraries and frameworks, including the well-known scikit-learn, XGBoost, LightGBM, CatBoost, spaCy, Optuna, Hyperopt and Ray, etc.
The typical machine learning workflow using Pycaret can be coded as below:
import pandas as pd
train_set = pd.read_csv('train_set.csv')
test_set = pd.read_csv('test_set.csv')
# init setup
from pycaret.classification import *
exp_name = setup(train_set, target = 'target_column')
# modeling
best_model = compare_models()
# analyze best model
evaluate_model(best_model)
# predict
predict = predict_model(best_model, data = test_set)
# save
save_model(best_model, 'my_saved_model')
Here are its resources:
2. H2O AutoML
H2O AutoML is another well-known automated machine-learning library that can help us train and tune many models in a short time.
H2O’s core implementation is written in Java. Its algorithms are developed on the distributed framework of Map/Reduce, leveraging the Java Fork/Join framework for multi-threading. Data is read in parallel and distributed across the cluster, and stored in memory in a compressed column format.

The design concept of H2O AutoML is to automate as much as possible. Users only need to give a dataset and a very small number of parameters to start modeling and tuning and try to find the best model in a certain amount of time or other constraints.
import h2o
from h2o.automl import H2OAutoML
# init
h2o.init()
aml = H2OAutoML(max_models =25,
balance_classes=True,
seed = 1)
# modeling and training
aml.train(training_frame = X, y = 'y')
lb = aml.leaderboard
# generate best model
best_model = aml.get_best_model()
print(best_model)
The official documentation can be found here.
3. FLAML
FLAML is a lightweight Python automated machine learning library launched by Microsoft, which can automatically, efficiently, and cost-effectively find accurate machine learning models. FLAML also has a .NET implementation from ML.NE model generator in Visual Studio 2022.
FLAML can quickly find high-quality models with low computational cost. It supports both classical machine learning models and deep neural networks.

The typical machine learning workflow using FLAML can be coded as below:
from flaml import AutoML
automl = AutoML()
automl.fit(X_train, y_train, task=”classification”)
The official documentation of FLAML can be found here, and the GitHub page is here.
4. Auto-sklearn
As can be seen from the name, Auto-sklearn is an automated machine learning toolkit based on sklearn. It utilizes methods like Bayesian optimization, meta-learning, and ensemble learning to automate modeling and tuning.

The way of use is very similar to sklearn, and those who are familiar with sklearn can quickly skill on it without additional learning. The sample code is as follows:
import autosklearn.classification
cls = autosklearn.classification.AutoSklearnClassifier()
cls.fit(X_train, y_train)
predictions = cls.predict(X_test)
The official documentation of Auto-sklearn can be found here, and the GitHub page is here.
5. TPOT
The TPOT library is based on scikit-learn, which uses Genetic Programming (GP) to efficiently discover the best model pipeline for a given dataset.

TPOT uses genetic programming to automatically design and optimize a series of data transformations which is mostly about feature engineering processing and machine learning models, and strives to maximize the performance of a given supervised learning dataset.
The flowchart of its process is as follows:
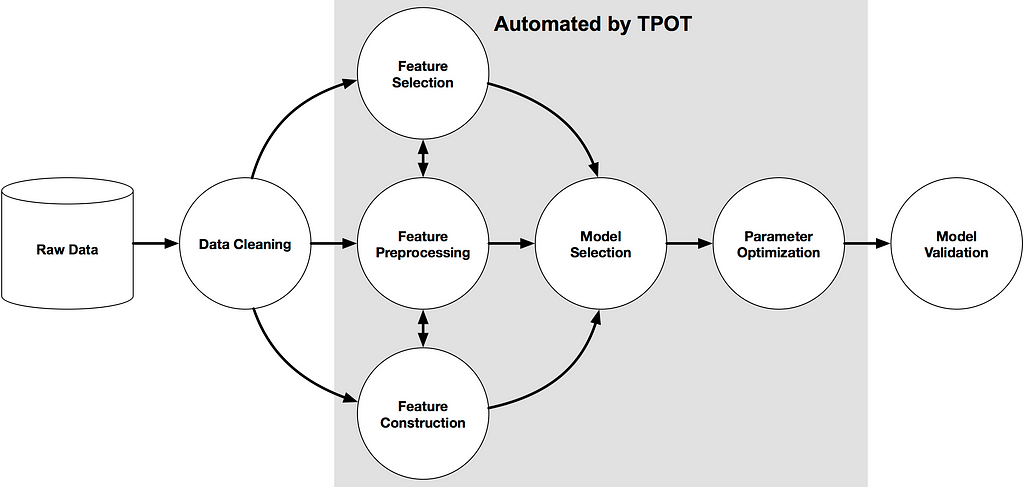
The entire modeling and tuning process is also very simple, and the entire process can be completed with the following 2 lines of code:
model = TPOTClassifier(generations=5, population_size=50, cv=cv, scoring='accuracy', verbosity=2, random_state=1, n_jobs=-1)
model.fit(X, y)
The official documentation of TPOT can be found here, and the GitHub page is here.
6. AutoKeras
AutoKeras is an automated modeling library that focuses on searching the architecture and hyperparameters of deep learning models, and selecting the best deep learning models as soon as possible. The API interface of Auto-Keras is exactly the same as scikit-learn, so it is easy to use.
It provides the classification and regression of text, images, and structured data. For advanced users, Autokeras can automatically tune the model.

The typical machine learning workflow using AutoKeras can be coded as below:
import autokeras
search = autokeras.StructuredDataClassifier(max_trials=15)
search.fit(x=X_train, y=y_train, verbose=0)
y_pred = search.predict(X_new)
The official documentation of AutoKeras can be found here, and the GitHub page is here.
7. EvalML
EvalML is a library of AutoML tools for building, optimizing, and evaluating machine learning pipelines using domain-specific objective functions. It combines advanced data processing and feature engineering libraries Featuretools and Compose to easily build end-to-end supervised machine learning solutions.

EvalML supports a variety of supervised learning tasks/problems such as regression, classification (binary and multiclass), time series analysis (both time series regression and classification), etc. The process:

The typical machine learning workflow using EvalML can be coded as below:
from evalml.automl import AutoMLSearch
automl = AutoMLSearch(X_train=X_train, y_train=y_train, problem_type="binary", objective="F1")
automl.search()
The official documentation of EvalML can be found here, and the GitHub page is here.
8. AutoGluon
AutoGluon is an open-source autoML framework optimized for deep learning development by AWS. In addition to structured tabular data, it supports image classification, object detection, and natural language processing tasks.

The core features of AutoGluon include:
- Automate finding the best deep learning architectures and hyperparameters.
- Model selection and automatic hyperparameter tuning.
- Automate data pre-processing.
The typical machine learning workflow using AutoGluon can be coded as below:
from autogluon.tabular import TabularDataset, TabularPredictor
train_data = TabularDataset('train.csv')
test_data = TabularDataset('test.csv')
predictor = TabularPredictor(label='class').fit(train_data=train_data)
predictions = predictor.predict(test_data)
The official documentation of EvalML can be found here, and the GitHub page is here.
9. AutoVIML
AutoVIML (Automatic Variables Explainable Machine Learning) is an open-source Python library that trains multiple models and automatically identifies best hyperparameters. It has a lot of built-in data preprocessing and interpretability features:
- Automated data processing and cleaning: Given a dataset, AutoVIML will try to automatically handle missing values, format variables, add variables, etc.
- Feature selection: AutoVIML automatically selects feature variables, which is very useful when our feature dimension is particularly high.

The typical machine learning workflow using AutoVIML can be coded as below:
from autoviml.Auto_ViML import Auto_ViML
#supposed all the necessary datasets are ready
model, features, trainm, testm = Auto_ViML(
train,
target,
test,
sample_submission,
hyper_param="GS",
feature_reduction=True,
scoring_parameter="weighted-f1",
KMeans_Featurizer=False,
Boosting_Flag=False,
Binning_Flag=False,
Add_Poly=False,
Stacking_Flag=False,
Imbalanced_Flag=False,
verbose=0,
)
The official documentation of AutoVIML can be found here, and the GitHub page is here.
10. MLBox
MLBox is an open-source AutoML Python library. Its features can be summarized as:
- Feature selection, missing value imputation, and outlier detection.
- Fast data preprocessing.
- Automatic hyperparameter optimization.
- Automatic model selection for classification and regression.
- Model Prediction and Model Interpretability.

The typical machine learning workflow using MLBox can be coded as below:
import mlbox as mlb
data = mlb.preprocessing.Drift_thresholder().fit_transform(data)
best = mlb.optimisation.Optimiser().evaluate(None, data)
mlb.prediction.Predictor().fit_predict(best, data)
The official documentation of AutoVIML can be found here, and the GitHub page is here.
That’s it.
Hope you can find something useful in this article. Thank you for reading and welcome to discuss with me!
Level Up Coding
Thanks for being a part of our community! Before you go:
- 👏 Clap for the story and follow the author 👉
- 📰 View more content in the Level Up Coding publication
- 🔔 Follow us: Twitter | LinkedIn | Newsletter
🚀👉 Join the Level Up talent collective and find an amazing job
10 Python Libraries For Automated Machine Learning That You Should Think To Use in 2023 was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Yeyu Huang
Yeyu Huang | Sciencx (2023-02-16T13:28:03+00:00) 10 Python Libraries For Automated Machine Learning That You Should Think To Use in 2023. Retrieved from https://www.scien.cx/2023/02/16/10-python-libraries-for-automated-machine-learning-that-you-should-think-to-use-in-2023/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.