
This content originally appeared on Level Up Coding - Medium and was authored by Divya Kurothe
Task Part1: Use Ansible playbook to Configure Reverse Proxy i.e. HAProxy and update it’s configuration file automatically on each time new Managed node (Configured With Apache Webserver) join the inventory.
Part 2 : Configure the same setup as part1 over AWS using instance over there.
So let’s us learn about what is HAProxy… HAProxy is a free, very fast and reliable solution offering high availability, load balancing, and proxying for TCP and HTTP-based applications. It is particularly suited for very high traffic web sites and powers quite a number of the world’s most visited ones. We particularly are going to use it for reverse proxy and load balancing between our back-end Apache Webservers.
Now, before we begin we must first learn how to integrate Apache Webserver and HAProxy. If one knows how to use Apache Webserver, HAProxy is just another configuration file away. A typical configuration file of HAProxy looks something as follows:
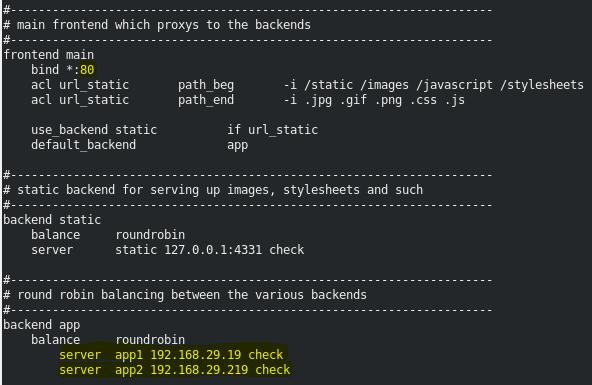
The highlighted parts in the snippets are what one must change. The bind is to tell what port must HAProxy must bind to for its working. And the server is the part where we’ll have to tell HAProxy where our back-end servers are working, also the name by which HAProxy will recognize them i.e. app1 and app2.
But configuring this manually, whenever a new back-end is summoned, will be really really tedious, and hence we require the automating capabilities of Ansible. Hence for us to perform this task we must write an Ansible-playbook so that we can repeat the complete task again and again on just a click of a button or with a single command.
The playbook in our case here can be created pretty easily. So, what’s the challenge? One might ask, the challenge to perform a task like this, where we will have to add n number of lines for every n number of back-end server we add. In a development environment the number webserver can be manageable, but as we move towards test, pre-prod, and finally production environment, the number of webservers get too many for one to manage on their own. Though we can employ a number of people, so that this task can get done, but that will be very costly in terms of cash and time, as humans are significantly slower than a computer. And hence we want our computer to manage this as well, without any human intervention after the computer starts to perform the required job.
So, to help us out with managing the ever changing number of back-end servers, we’ll have to take the help of templates specifically Jinja2… Jinja is a fast, expressive, extensible templating engine. Special placeholders in the template allow writing code similar to Python syntax. But how? As mentioned, special placeholders can allow for us to write code similar to python. Ansible comes pre-loaded with the capabilities to use Jinja(Jinja2) template for dynamically copying content from one place(in controller node) to another(in target node). Hence we can simply apply a for loop while copying our configuration file from the template to it’s original location, and that would be the easiest way to solve our issue…
Below is the playbook we created for this task:
- hosts: proxy
vars:
- s_port: 80
tasks:
- name: installing HaProxy...
package:
name: haproxy
state: present
- name: copying the configuration file...
template:
src: haproxy.j2
dest: /etc/haproxy/haproxy.cfg
notify: restarting haproxy...
- name: starting the service...
service:
name: haproxy
state: started
enabled: yes
register: started
- name: setting up facts...
set_fact:
condition_restart: "{{ started.changed==False }}"
handlers:
- name: restarting haproxy...
service:
name: haproxy
state: restarted
when: condition_restart
- hosts: server
tasks:
- name: installing httpd...
package:
name: httpd
state: present
- name: starting service...
service:
name: httpd
state: started
enabled: yes
- name: copying content...
template:
src: index.j2
dest: /var/www/html/index.html
The playbook has 2 plays. The first works on host proxy where we are going to install HAProxy, configure HAProxy, start or restart the service for HAProxy. For configuring HAProxy we are going to use template module, which is going to turn Jinja2 code into a useable format and then copy it to the required location. The template we used for this looks something as shown below:
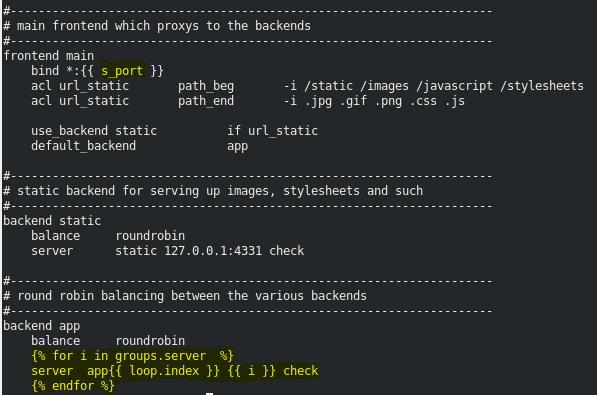
The s_port is a variable whose value is defined from the playbook itself. The second section is Jinja2 for loop through which we are going to print server app<n> <IP> check for every back-end-server we add in our inventory file. The inventory file for this task looks something as follows:
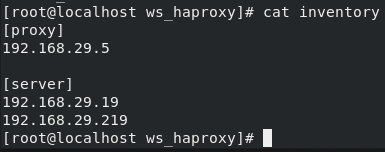
Where proxy is the group of HAProxy server, and server is the group of Apache webserver which we are going to use as our backend server.
The second play works over server as target node, where we are going to download Apache Webserver(HTTPD), use template to change the root documentary so that our webpage is nothing but the IP address of the system itself, and lastly start the service for HTTPD. The template for this play looks like as follows:

Here we are using ansible_facts do fetch the IP and print it to the required location. Let’s test the playbook and check if we get the appropriate results(using curl).
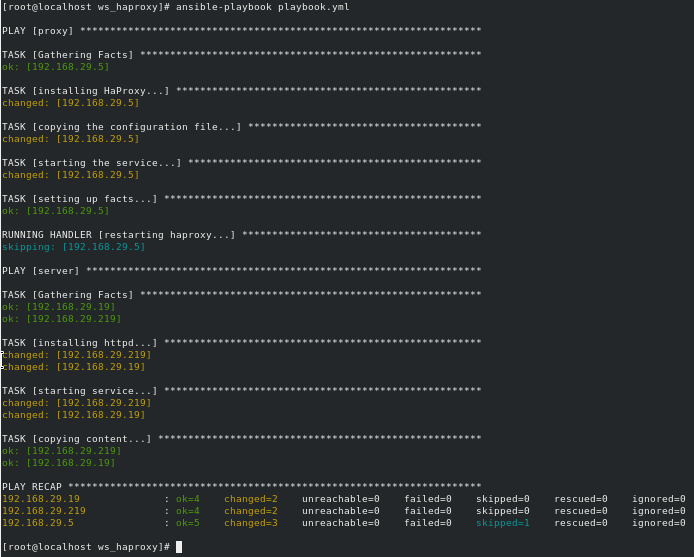
The playbook runs fine, now let’s test the setup using curl command…
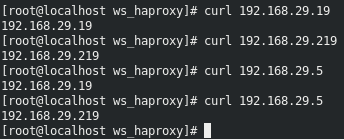
So that’s it our setup function as we’d wanted it to…
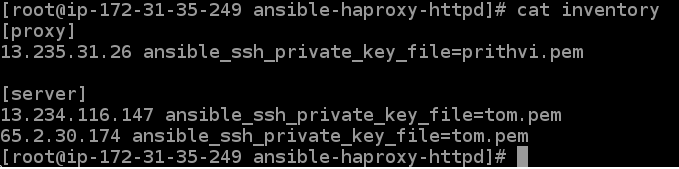
Part2: For this part, the only changes we’ll require to make is to our inventory(to change to appropriate IP sets) and to our ansible.cfg file(for privilege escalation).
The inventory won’t change much, we’ll only need to change the IP addresses to IP addresses of the required systems. Also since we can’t use passwords here, we are going to use private key file for SSH.
And the ansible.cfg will be changed to something like:
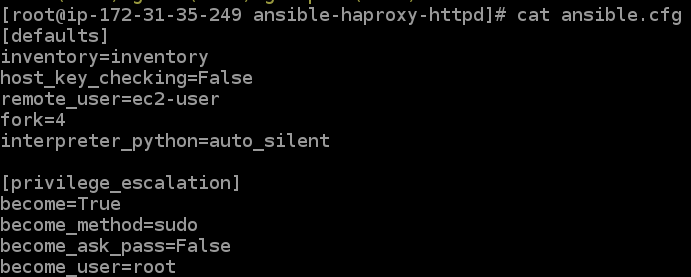
Here we had to change the remote_user to ec2-user as AWS doesn’t allow us to use root directly via SSH, and hence we require the extra [privilege_escalation]section. Now you can either create all the required file by yourself, or you can use GitHub as shown below:
The command you can run to copy the files from GitHub
Now you can use the copied files as a base to build upon.
Also to install Ansible in your ec2 instance(Amazon Linux) you can follow the steps shown below:

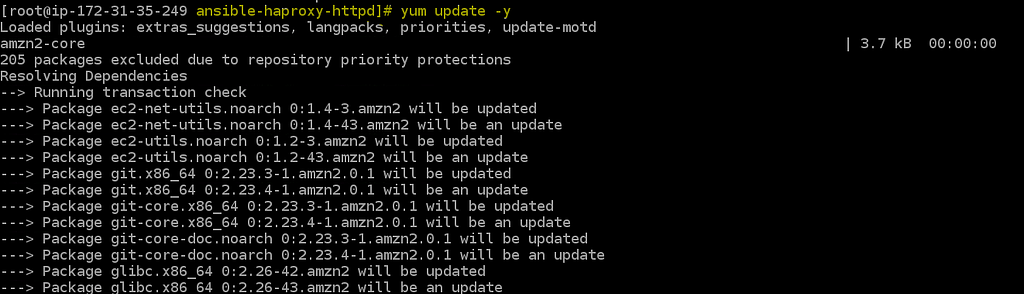

To install Ansible
Side note: Amazon Linux doesn’t support HAProxy, so use RedHat instead.
Now let’s test our playbook and our new Ansible configuration…
Play1 ran successfully
Play2 ran successfully
So the Playbook ran successfully…
Let’s do a curl test now:

This task was completed in collaboration with @Prithviraj Singh and I would like to thank him for his guidance and support.
Configuring Load Balancer(HAProxy) Dynamically With Ansible was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Divya Kurothe
Divya Kurothe | Sciencx (2023-02-17T15:52:38+00:00) Configuring Load Balancer(HAProxy) Dynamically With Ansible. Retrieved from https://www.scien.cx/2023/02/17/configuring-load-balancerhaproxy-dynamically-with-ansible/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.