
This content originally appeared on Bits and Pieces - Medium and was authored by Fernando Doglio
6 best practices for designing and implementing microservices

Microservices are sometimes depicted as the magical silver bullet that solves every architectural problem. And while they’re very nice and I personally tend to favor them, there is no “magic” involved in their design. They don’t add solutions out of the box and they definitely don’t solve every problem.
However, if implemented properly, they do give you a set of tools that you can leverage to create highly scalable and resilient architectures.
So in this article, I want to cover some of the most commonly missed best practices to make sure that the next time you try to use microservices, you get the most out of them.
Let’s get going!
Decentralized data management
If we want to be purists when it comes to designing our microservices, we should aim at a scenario where each service has its own database. This way you ensure scalability and keep microservices from affecting other services’ data storage layer.
That said, I hate purists, and you should too if I may say so myself.
You see, real-world problems are hardly ever solved with “pure” solutions. Instead, you should aim for a reasonable compromise.
In other words, yes, the idea is that each microservice should be able to interact with its data layer without affecting or being affected by others. However, duplicating data for the sake of purism isn’t a good design decision either. Instead, try to group their data layers based on concerns. If multiple services share the same data model or need a common source of information, keep them all together.
💡 This is where an open source toolchain like Bit can help, letting your teams share reusable types across multiple microservices to reduce the amount of code that needs to be written, and thus work together more efficiently.
To learn more about sharing types between teams:
Sharing Types Between Your Frontend and Backend Applications
If some of them require heavy usage of either reading or writing into your storage solution, look for ways to optimize for this with solutions provided by the database you’re using.
To put it simply, use all your tools at your disposal to solve the problem, instead of simply looking at it from the perspective of your microservices.
API gateway pattern
There are many different patterns to choose from when you’re designing a platform architecture that is based on microservices. And you can use multiple of them depending on what part of the architecture you’re focusing on.
But one in particular that usually tends to be used and helps a lot with the adoption of your API is the API Gateway pattern.
Given how microservices tend to provide granular functionality, it’s usually the responsibility of the client to determine which endpoints to use and when to use them.
If the API is simple and there aren’t many things you can do with it, then this pattern is not such a big deal. But think of the API of a giant like Netflix. They’re constantly adding new features or changing endpoints because they deprecate old ones. Building a client that maps use cases to API endpoints can be a daunting task, and even worse, the moment they make a change, you have to go running to update your application.
Instead, these platforms use an API gateway, which helps simplify the interaction between clients and services.
Look at the following diagram:
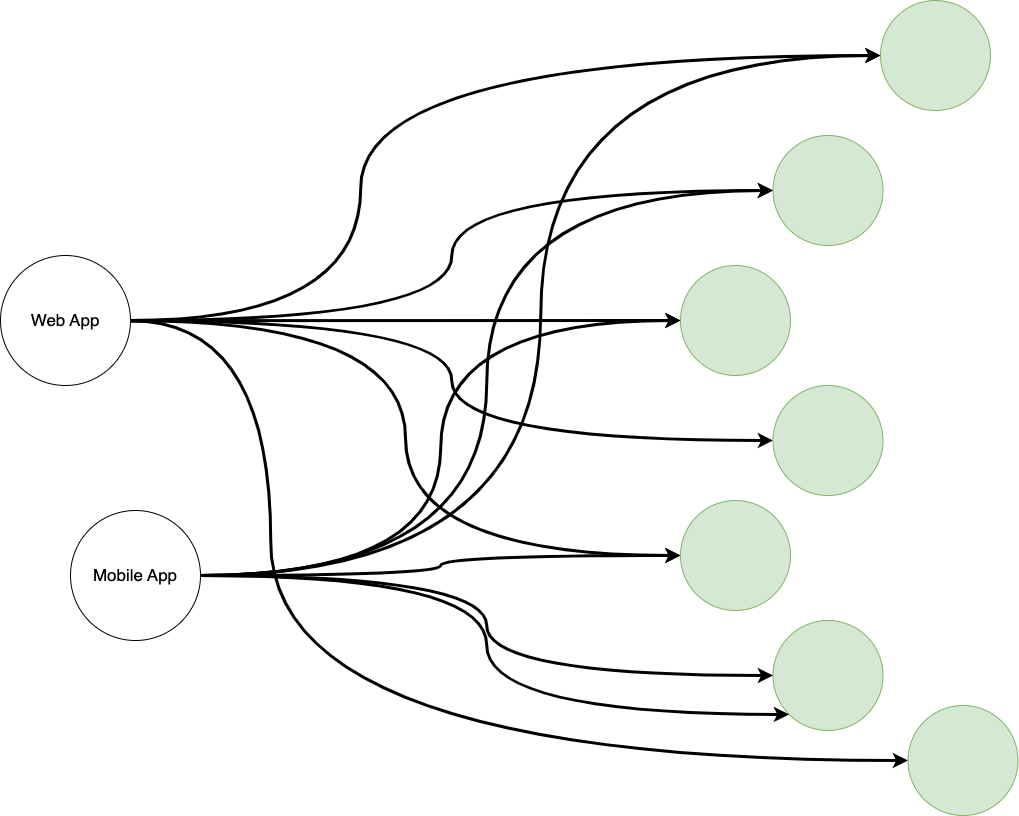
This is an oversimplification, yes, but you have many services on the right used by two different types of clients on the left. If one of these services changes or is deprecated, the whole client ecosystem would collapse.
Instead, the following approach solves this problem:
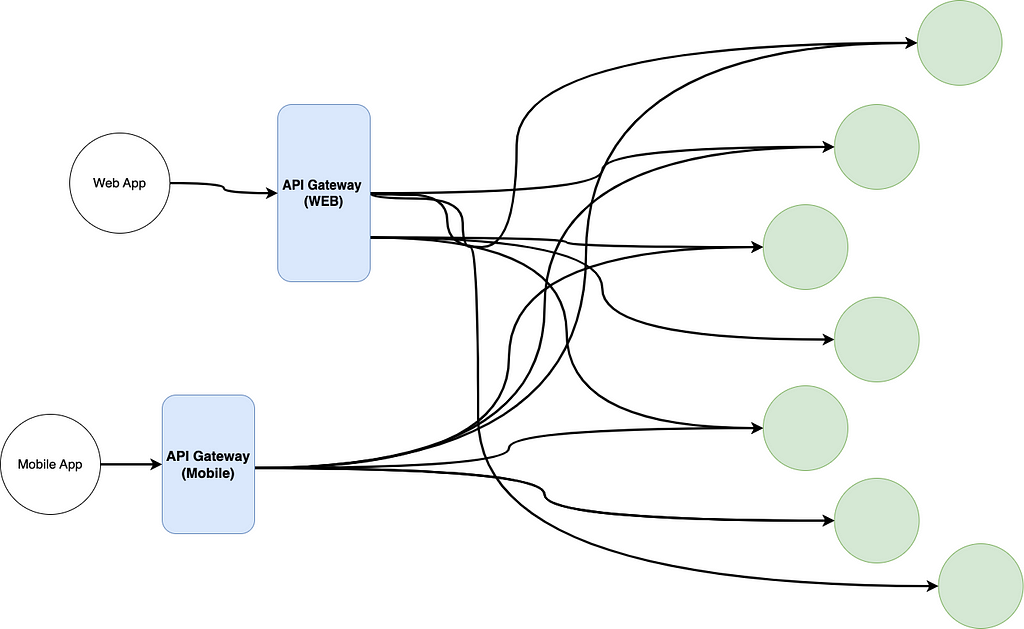
The entangled mess of connections is still there, but from the POV of the client applications, the interaction is completely transformed. If tomorrow you need to change the APIs, as long as you update the connection between the gateways and your services, the clients don’t have to know about it.
This is one of those “must-implement” patterns if you’re building a mid-sized platform (or bigger).
Autonomous teams
This might be a benefit, a good practice or even a result of dealing with microservices, but it’s something you and your company should be aiming for.
The beauty of microservices is that they can be as independent as you want. This in turn lets each team focus solely on their goals and objectives. If the overall plan is well organized and the functionalities for each service is properly defined, then building each individual part in isolation will keep their code bases and internal logic decoupled from that of the other many services.
In other words, each microservice should be developed and maintained by a separate, cross-functional team.
Of course, this also allows for parallel development of the services which as a result, would reduce overall development times.
Circuit breaker pattern
Once you have enough microservices, all talking to each other, you run into the risk of facing a cascading failure scenario the moment one of your services runs into a fatal error.
In other words, the stability of your entire platform is determined by the stability of your weakest service. And this is a place where you don’t want to be.
Your aim should be to develop microservices that can withstand the critical failure of those it depends on. I know, it sounds too good to be true, but all I’m saying is that if you have the following scenario, and you have a critical failure on Server 1, the rest of the platform should keep working.
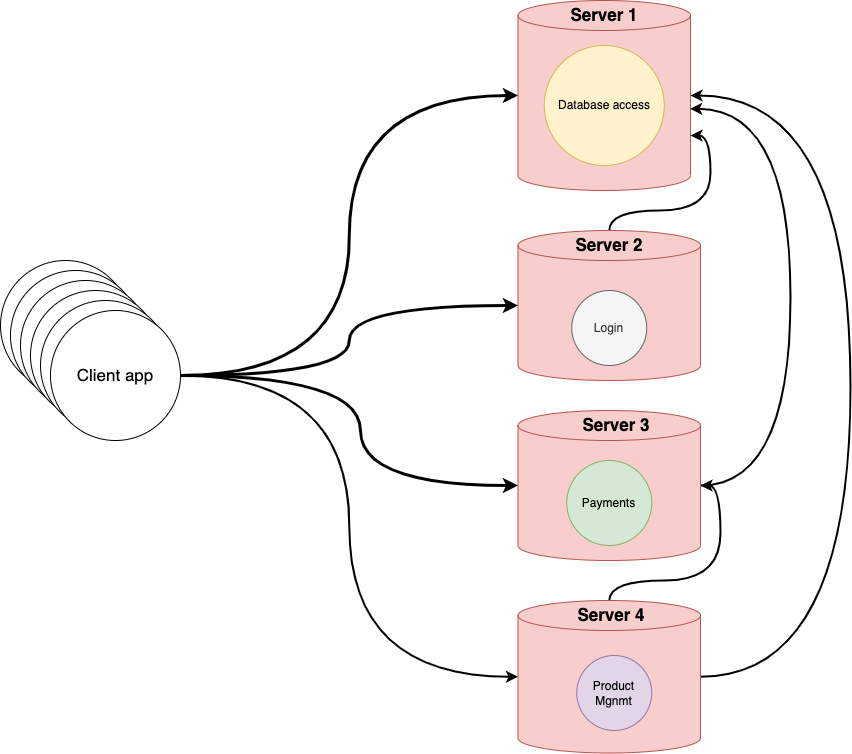
How is the platform going to work without a database? That’s a good question.
And the answer is that it doesn’t have to. All it has to do is respond with the proper error message. Every time you go through the “Product Mgnmt” service, or through the “Payments” service and you try to do something that requires a database, the system should let you know there is a problem.
That’s all there is to it.
Sadly the most common alternative, is that once the database service dies, every other service that depends on it will crash the second they try to access it.
Try to avoid that behavior. If you want to know more about this pattern, check out this article.
Did you like what you read? Consider subscribing to my FREE newsletter where I share my 2 decades’ worth of wisdom in the IT industry with everyone. Join “The Rambling of an old developer” !
Versioning
There are mainly two reasons why you want to pay special attention to versioning when it comes to defining and planning your microservices:
For starters, this gives you the ability to have multiple versions of your services up and running in case there are special upgrades to roll over.
Through versioning, you can let your clients specify the version they want to interact with. If you want to know more about this, check out this article I wrote about API versioning.
The second reason is to properly manage dependencies.
For an environment where you have multiple teams individually working and developing projects that interact with each other (especially if you’re going to accept the parallel deployment of multiple versions), then a versioning management solution should be used.
For example, if you’re doing all Node.js-based microservices, a good solution would be using Bit. You can set it up as your main package and dependencies manager and it will abstract you from all the tools on the workflow.
The extra benefit is that you can share internal components (i.e libraries and functions you create for your use case) with other microservices easily.
Turning the process of creating and managing common code into a breeze. If you want to know more about using Bit to create microservices, check out this tutorial by Gilad Shoham.
Component-Driven Microservices with NodeJS and Bit
Overall, whatever your tech stack is, a good rule of thumb is to ALWAYS allow for an easy versioning strategy for your microservices. Even if your services are only internally used, the strategy will simplify your and everybody’s life in the future.
Service discovery
When building your architecture, if you have many different services, especially if you keep them under dynamic IPs, or they have the tendency to change and be deprecated, a good idea would be to implement a service-discovery solution.
In other words, instead of having to manually keep a hardcoded list of addresses and endpoints inside every service and client that requires it, you’ll let that information be dynamically loaded during start-up.
For this, you usually need a discovery service, something that keeps an updated and centralized map of services (their IPs, methods, etc).
Old technologies, like SOAP used to have this as part of their mandatory process and you would not get it to work without one.
Modern options now have the tendency to ignore this part of the architecture, however, it’s a good idea to implement it if your architecture is complex enough.
There are two options:
- Manual registration. This process implies every time you make a change or add a new service you have to manually update the central registry. This is a good option if you have many services but they either don’t change too much or you don’t have that many services to begin with.
- Self-registration. This one is my personal favorite. In this setup, the only address both services and clients need to know about is that of the registry. When services start up, they’ll connect to it and they’ll send a pre-defined schema with their information (address, list of methods and their signatures). And the clients will do the same, but they will collect the existing data to automatically map their internal logic to the schemas received.
Once registered, the registry itself can also keep track of the state of the services by periodically pooling them. That way you can also be notified if the state of any of them changes (like a service crashing and restarting with a new IP).
Service discovery is certainly not magical, but it does provide a level of automation that is very welcomed once your ecosystem is big enough.
Of course, there are more best practices that I’ve left out, like keeping your code clean, using CI/CD to test and deploy your services, running integration tests to ensure that everything works together, and more.
These best practices have helped me during my almost 2 decades of career to create resilient and scalable architectures that were deployed both, on cloud and on-prem environments.
In the end, the main thing you have to remember is to plan for the worst scenario. Think about what would happen if some of your services crashed during peak hours, or if the number of microservices grew out of proportion, what would you do then?
The answers are above, so make sure to implement some of them.
Build apps with reusable components like Lego
Bit’s open-source tool help 250,000+ devs to build apps with components.
Turn any UI, feature, or page into a reusable component — and share it across your applications. It’s easier to collaborate and build faster.
Split apps into components to make app development easier, and enjoy the best experience for the workflows you want:
→ Micro-Frontends
→ Design System
→ Code-Sharing and reuse
→ Monorepo
Learn more
- How We Build Micro Frontends
- How we Build a Component Design System
- How to reuse React components across your projects
- 5 Ways to Build a React Monorepo
- How to Create a Composable React App with Bit
Building Microservices with Confidence: Key Strategies and Techniques was originally published in Bits and Pieces on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Bits and Pieces - Medium and was authored by Fernando Doglio
Fernando Doglio | Sciencx (2023-02-19T08:02:44+00:00) Building Microservices with Confidence: Key Strategies and Techniques. Retrieved from https://www.scien.cx/2023/02/19/building-microservices-with-confidence-key-strategies-and-techniques/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.