
This content originally appeared on Bits and Pieces - Medium and was authored by dbaltor
Instead of size, think about the flow

A flow-based process delivers information on a regular cadence in small batches.
Don Reinertsen
Many organisations and teams have been struggling to get their microservices boundaries right. Either too small or too large microservices will bring to their teams a completely different set of problems, but with the same undesirable outcome: the inability to release software faster and frequently, and with fewer problems.
Microservices are supposed to be quickly evolved and frequently released software that run as independently scalable and available distributed processes.
To achieve such an ambitious goal, we really need to decouple them as much as possible across multiple dimensions:
- Product decoupling — dictates whether a team handles every aspect of a single product produced by the organisation, including feedback from users. Don Reinertsen carefully explains in his groundbreaking book, The Principles of Product Development — FLOW, why invisible and unmanaged queues are the underlying root cause of poor product development performance.
- Design decoupling — influences how easily and frequently teams can code, test, deploy and release their services without excessive coordination across different teams
- Runtime decoupling — controls how chatty and independently executable services will be, hugely impacting their performance, scalability and availability.
- Infrastructure decoupling — drives all sorts of QoS such as performance, availability, and scalability.
Once decoupled in this way, you can isolate components within your codebase and define them as independent entities that can be developed and tested separately. Using a tool like Bit, you can then version, document, test, and shared them via a central registry. Know more here and here.
Team autonomy
The best way we have found to date to make teams, and hence their microservices, really autonomous is to align them “to a flow of work from (usually) a segment of the business domain” which Matthew Skelton and Manuel Pais have called Stream-aligned teams in their best-seller Team Topologies.
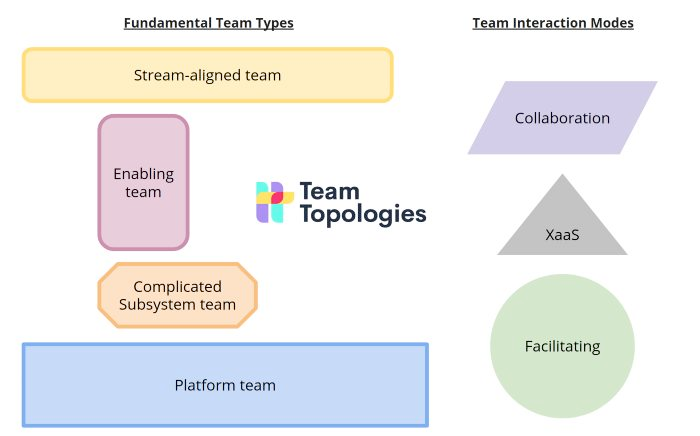
As Nick Tune and Scott Millett described in their great book Designing Autonomous Teams and Services, high-performance teams share two essential characteristics:
Product strategy autonomy which enables them to work closely with customers, continuously discovering what is valuable to customers by conducting user research and experiments on an ongoing basis.
Architectural autonomy which enables them to build high-speed engineering capability so they can deliver business value frequently with minimal coordination overhead.
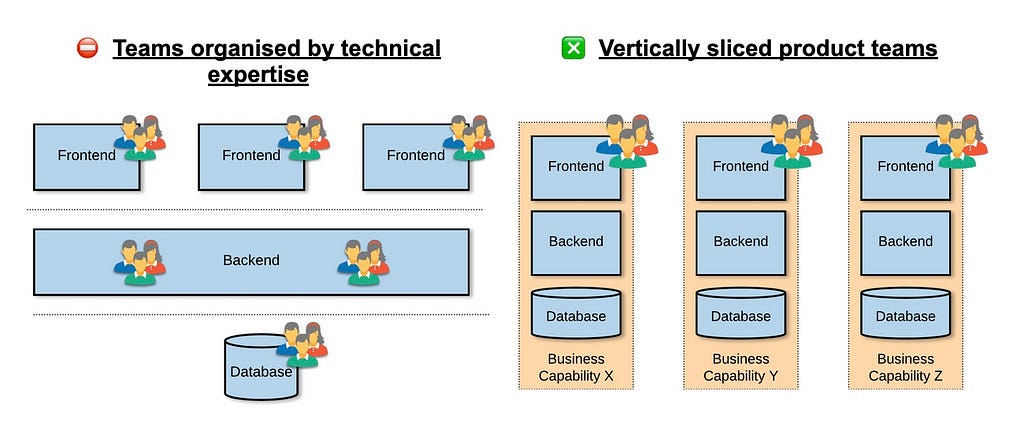
The upper bound
Eric Evans, in his seminal blue book, showed us how to design applications by modelling the Business Domain. For complex domains, it is a mistake to think that we can create a single domain model for the entire company. We need to split it into Subdomains which are sub-parts of the overall business domain.
A successful model, large or small, has to be logically consistent without contradictions. A Domain-Driven Design Bounded Context delimits the applicability of a particular model so that team members have a clear understanding of what has to be consistent and how it relates to other teams (contexts).
Bounded Contexts set boundaries in terms of team organisation and physical manifestations such as codebases and database schemas. They help teams keep the model strictly consistent within these bounds without being distracted or confused by external issues.
Sidenote: Bounded Contexts and Subdomains
Chris Richardson has been using in his talks the notion of SUBDOMAIN instead of BOUNDED CONTEXT to define the same idea of an upper limit to microservices’ size. This actually works perfectly fine and I also find SUBDOMAIN easier to grasp than BOUNDED CONTEXT. However, I’ll stick with BOUNDED CONTEXT in this article as I think it reinforces the idea that the some Domain Entities may surface in different microservices and, even though representing the same concept, they’re most likely going to exhibit a completely different set of attributes for being in different contexts. A classical example is Product in Catalog and Fulfilment contexts.
Sidenote: Bounded Contexts are not Modules
A BOUNDED CONTEXT provides the logical frame inside of which the model evolves. MODULES are used to organise the elements of a model, so BOUNDED CONTEXT encompasses the MODULE. Modules provide different namespaces but they don’t necessarily communicate an intention to separate contexts. The separate namespaces that modules create within a bounded context actually make it harder to spot accidental model fragmentation.
It’s clear from the previous section that there is a limit to which the size of a microservice can grow without defeating its purpose of enabling fast flow.
A microservice shall not outgrow its Bounded Context.
However, business autonomy is not the only goal we want to achieve. There are other forces we need to balance, for example: cognitive load on development teams as well as lead time: the time that takes for an idea to go through the development process and be made available to users. For instance, if the amount of testing required to release a change/new feature is disproportionately long compared to the coding effort, the microservice has likely become too large.
The lower bound
For complex bounded contexts, a single microservice might be too large and end up being split into smaller services. This poses a question: is there a lower bound to the size of a microservice? Yes, there is indeed.
A microservice shall not be smaller than a Domain-Driven Design Aggregate and the associated Domain Services that operate on the Entities and Value Objects therein.
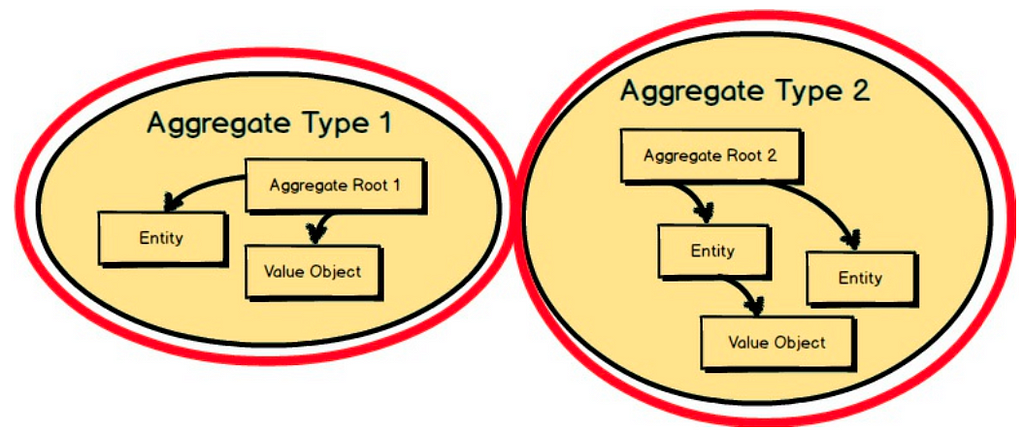
An Aggregate is a group of associated objects which are considered as one unit with regard to data changes. Each Aggregate has one root. The root is an Entity, and it is the only object accessible from outside. The root can hold references to any of the aggregate objects, and the other objects can hold references to each other, but an outside object can hold references only to the root object.
If you find that the change to some business capability requires changes to several microservices then you have likely got your microservices too fine grained, with one (or more) Aggregate(s) spanning across different services.
What is the right size for an aggregate then?
All right! A microservice should consist of no less than an Aggregate, but the attentive reader may ask now: how to define an aggregate size?
As I mentioned, an aggregate represents a cluster of domain objects that must be treated as a single unit. Its Entities and Value Objects must be updated under a single transaction boundary. So we don’t want to spread data that must be kept consistent at all times across different aggregates.
On the other hand, the Aggregate root entity governs the lifetime of all objects within the Aggregate. Because the whole aggregate must be loaded and persisted as a single unit, large aggregates can cause severe performance problems and lock contention.
To handle both concerns properly, we need to embrace eventual consistency across Aggregates. Data integrity and consistency exist only within Aggregates. Across boundaries, updates are to be handled asynchronously whenever possible. I have written here about systems that embrace this asynchronous style of communication.
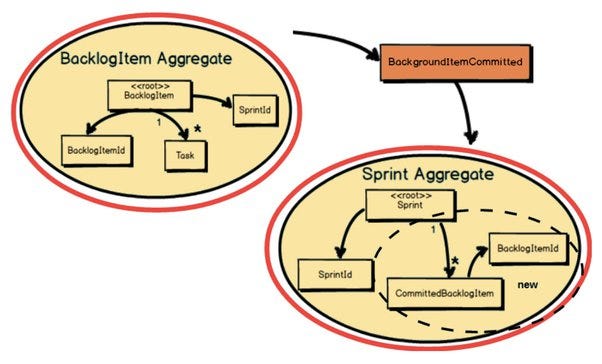
This leaves us with the following set of rules to size Aggregates:
Rule 1: Protect Business Invariants inside Aggregate Boundaries using Transactions
Rule 2: Design Aggregates as Small as Possible without Contradicting the Rule 1
You can read more about these rules in Vaughn Vernon’s insightful book Domain-Driven Design Distilled which I consider the best reference for non-technical people to learn what DDD is about.
Adoption anti-patterns caused by wrong boundaries
I have talked so far about setting service boundaries in the right place, but it’s also useful to see what happens when we get them wrong. I’ll show you some common mistakes made by teams during their journey towards microservices.
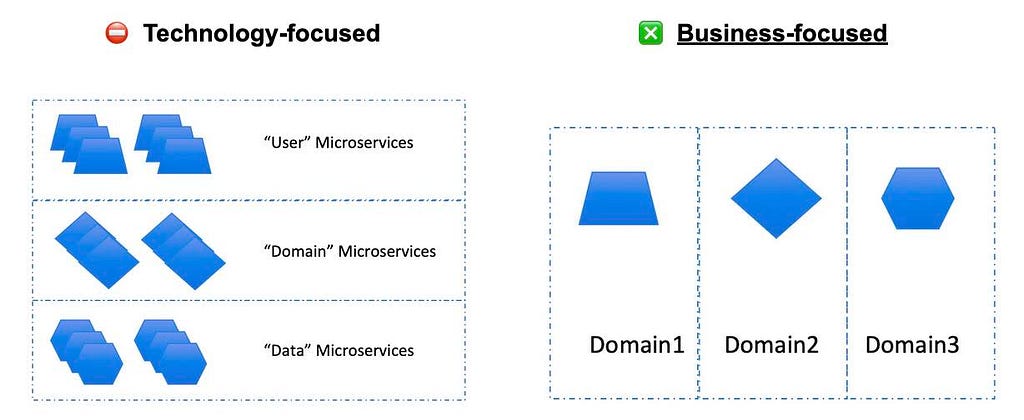
Layered Services Architecture
This anti-pattern usually emerges in architectures created by teams that haven’t adopted Domain-Driven Design from the start. One common mistake from the SOA age is trying to achieve reusability of services by mostly focusing on technical capabilities rather than functional cohesion. The resulting services tend to be very technology-focused and not at all related to terms that the business would recognize.
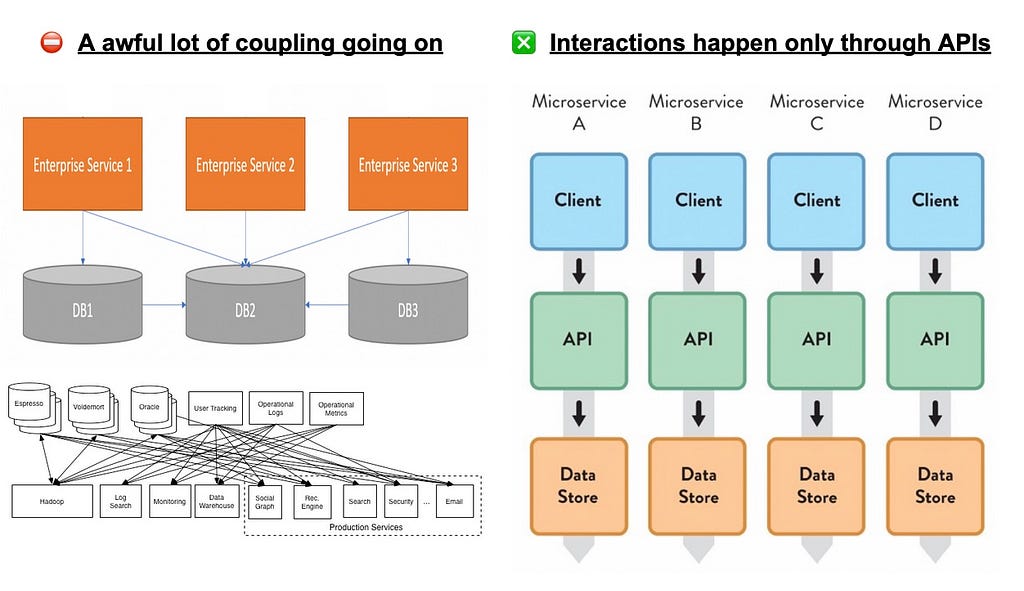
Data Taffy
This anti-pattern, also known as Entangled Data, is very common and happens when services have full access to each other’s data stores, regardless of the technology being used.
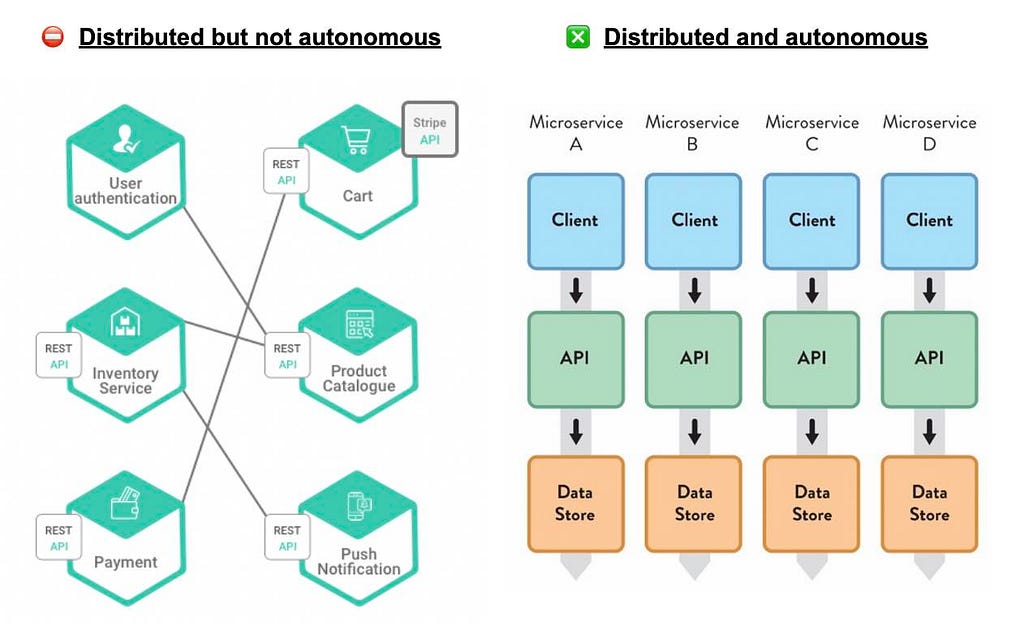
Distributed Monolith
The dreadful distributed monolith is a system that consists of multiple services, where customer journeys require that most (if not all) services be available and, oftentimes, the entire system must be deployed together. It typically emerges when not enough focus is placed on the concepts of design and runtime decoupling I mentioned before.
Final thoughts
The rules above imply that we, software engineers, need to reach out to the Domain Experts from our business to understand what business invariants are supposed to be enforced before defining the right size for our microservices. Not everything needs to be protected under ACID transactions in order for the business to succeed. After all, software is not only about technology but about the business.
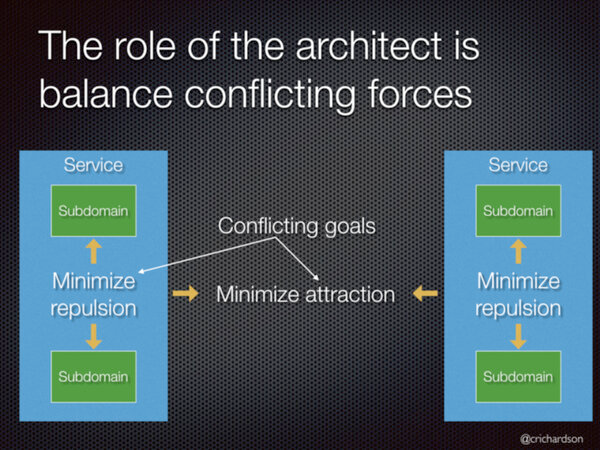
I’ll close this article with Chris Richardson’s comments from another of his great talks, Modular monoliths and microservices: architectural patterns for rapid, reliable, frequent and sustainable development, where he says:
The role of the architect when figuring out how to partition the system into subdomains is to resolve conflicting forces by minimising repulsive forces within a service and minimise the attractive force between different services
From monolithic to composable software with Bit
Bit’s open-source tool help 250,000+ devs to build apps with components.
Turn any UI, feature, or page into a reusable component — and share it across your applications. It’s easier to collaborate and build faster.
Split apps into components to make app development easier, and enjoy the best experience for the workflows you want:
→ Micro-Frontends
→ Design System
→ Code-Sharing and reuse
→ Monorepo
Learn more:
- How We Build Micro Frontends
- How we Build a Component Design System
- How to reuse React components across your projects
- 5 Ways to Build a React Monorepo
- How to Create a Composable React App with Bit
How to Choose Microservice’s Boundaries? was originally published in Bits and Pieces on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Bits and Pieces - Medium and was authored by dbaltor
dbaltor | Sciencx (2023-02-21T11:22:52+00:00) How to Choose Microservice’s Boundaries?. Retrieved from https://www.scien.cx/2023/02/21/how-to-choose-microservices-boundaries/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.