
This content originally appeared on Bits and Pieces - Medium and was authored by Kamini Kamal
Design Search Service at Scale (Master-Worker Architecture)
Part 1: An overview of how to approach a distributed microservice in terms of scalability and fault tolerance.
When designing a search or any other microservice at scale, there are a couple of questions popping up in our heads on reliability and dynamicity. There are multiple ways of achieving a fault-tolerant and reliable service. In this article, I will discuss one way to achieve this by introducing parallel computation followed by data partitioning.
Let us list down the key elements of our design:
- We want to make it scalable, fault-tolerant, fast, and reliable.
- We will follow the master-worker architecture and parallel computation and aggregate the results before sending the response to the client.
- We will allow the loosely coupled and scalable components of our system to register themselves to the corresponding service registry.
- We will partition the data across a shared database.
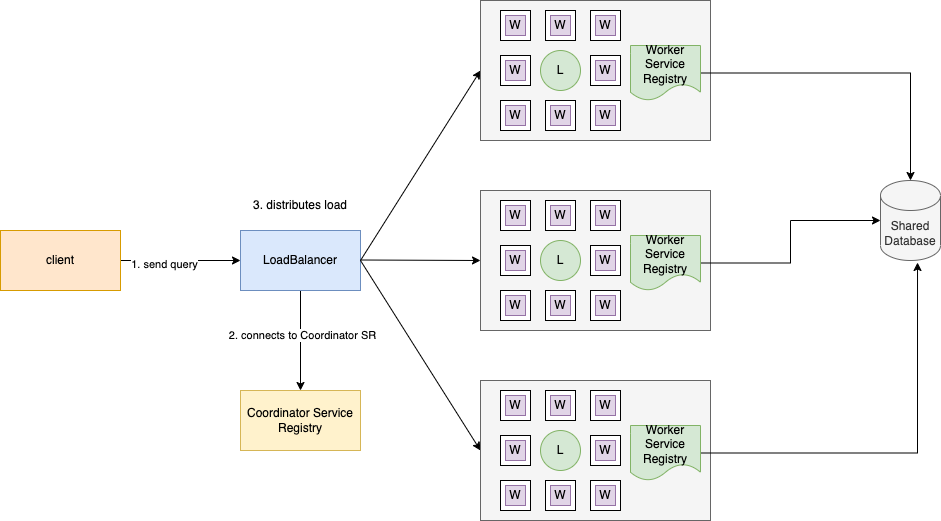
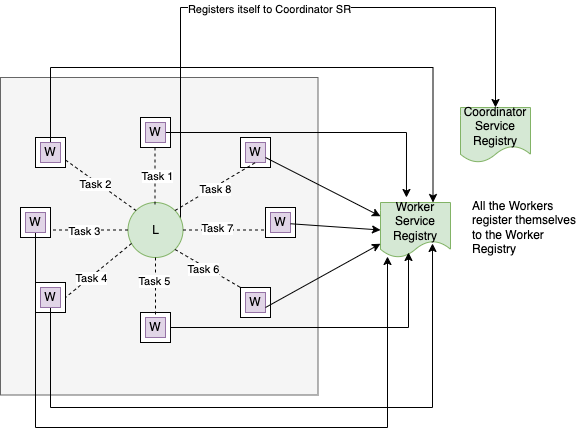
The leader registers itself to the Coordinator Service Registry while the workers register themselves to the Worker Service Registry. Whenever either of the services goes down, it's deregistered from the Service Registry.
A Service Registry is a way for the Load Balancers to discover the healthy instances of a service.
The Leader receives the query and delegates tasks to each of the worker nodes after checking their health status from the Worker Service Registry.
The datasets are huge, so they are partitioned based on a key or a combination of keys. When the Worker nodes receive a task from the Leader Node, based on the task description they read and find the exact partition to the data from. This calculation can be done by the leader using a hash function.
How do we handle failures in this design?
- If one of the leaders goes down, the leader election brings up a new leader among the available worker nodes and registers the new leader to the Coordinator Service Registry.
- When the workers go down, the partitioning logic in the Leader node assigns tasks to the remaining workers so that none of the partitions are left unread.
- The load balancer checks the Coordinator Service Registry and routes the traffic to the available clusters. In case, we see that a few of the clusters are heavily loaded with requests, we can implement logic on the load balancer's end to route the traffic uniformly to the available clusters.
- The Leader will wait for the workers to get computed results for the search for a specific time period within which the workers are supposed to send back the response. If not, the leader will follow a retry mechanism, failing which the defective worker will be thrown out of the Quorum or marked unhealthy by the Leader in the Worker Service Registry.
💡 Another way to ensure fault-tolerance and reliability in a microservice architecture is to use an open-source toolchain like Bit. Bit is a package management and collaboration platform that allows you to build, share, and reuse individual components across your codebase, making it easier to scale and maintain your microservices.
By using Bit, you can ensure that your components are versioned, tested, and shared across different microservices, reducing the risk of failures caused by inconsistent dependencies or code duplication. Find out more here and here.
Learn more here:
Component-Driven Microservices with NodeJS and Bit
Summary
In this article, we got an overview of how to approach a distributed microservice in terms of scalability and fault tolerance. We will dive deep into certain aspects of the search service like the search algorithm, scaling up the database replicas, load balancing logics, strategies to deploy the Worker Service Registry, and many more in the upcoming articles. In one of my articles, I discussed Designing Search Service at Scale using Scatter Gather Pattern https://medium.com/@kamini.velvet/search-service-using-scatter-gather-pattern-13fab5fe71ad
Thank you!
Build Apps with reusable components, just like Lego
Bit’s open-source tool help 250,000+ devs to build apps with components.
Turn any UI, feature, or page into a reusable component — and share it across your applications. It’s easier to collaborate and build faster.
Split apps into components to make app development easier, and enjoy the best experience for the workflows you want:
→ Micro-Frontends
→ Design System
→ Code-Sharing and reuse
→ Monorepo
Learn more:
- How We Build Micro Frontends
- How we Build a Component Design System
- How to reuse React components across your projects
- 5 Ways to Build a React Monorepo
- How to Create a Composable React App with Bit
Design Search Service at Scale was originally published in Bits and Pieces on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Bits and Pieces - Medium and was authored by Kamini Kamal
Kamini Kamal | Sciencx (2023-02-23T02:20:23+00:00) Design Search Service at Scale. Retrieved from https://www.scien.cx/2023/02/23/design-search-service-at-scale/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.