
This content originally appeared on DEV Community and was authored by Leandro Proença
If you already work with Git daily but want to have a good comprehension of Git fundamentals, then this post is for you.
Here, you'll have the chance to truly understand the Git architecture and how commands such as add, checkout, reset, commit, merge, rebase, cherry-pick, pull, push and tag work internally.
Don't let Git master you, learn the Git fundamentals and master Git instead.
Brace yourselves, a complete guide about Git is about to start.
💡 First things first
You must practice while you read this post.
Following along, let's first create a new project called git-101 and then initialize a git repository with the command git init:
$ mkdir git-101
$ cd git-101
The Git CLI provides two types of commands:
plumbing, which consists of low-level commands used by Git internally behind the scenes when users type high-level commands
porcelain, which are the high-level commands commonly used by Git users
In this guide, we'll see how the plumbing commands relate to the porcelain commands that we use day-to-day.
⚙️ The Git architecture
Inside the project which contains a Git repository, we can check the Git components:
$ ls -F1 .git/
HEAD
config
description
hooks/
info/
objects/
refs/
We're going to focus on the main ones:
.git/objects/
.git/refs
HEAD
Let's analyse each component in detail.
💾 The Object Database
Using the UNIX tool find we can see the structure of the .git/objects folder:
$ find .git/objects
.git/objects
.git/objects/pack
.git/objects/info
In Git, everything is persisted in the .git/objects structure, which is the Git Object Database.
What kind of content can we persist in Git? Everything.
🤔 Wait!
How is that possible?
Through the use of hash functions.
🔵 Hashing for the rescue
A hash function maps data of arbitrary, dynamic size into fixed-size values. By doing this, we can store/persist anything because the final value will have always the same size.
Bad implementations of hash functions can easily lead to collisions, where two different dynamic-size data could map to the same final hash of fixed-size.
SHA-1 is a well-known implementation of the hash function that is in general safe and hardly has collisions.
Let's take, for instance, the hashing of the string my precious:
$ echo -e "my precious" | openssl sha1
fa628c8eeaa9527cfb5ac39f43c3760fe4bf8bed
Note: If you're using Linux, you can use the command sha1sum instead of OpenSSL.
🔵 Comparing differences in the content
A good hashing is a safe practice where we can't know the raw value, i.e doing the reverse engineering.
In case we want to know if the value has changed, we just wrap the value into the hashing function and voilà, we can compare the difference:
$ echo -e "my precious" | openssl sha1
fa628c8eeaa9527cfb5ac39f43c3760fe4bf8bed
$ echo -e "no longer my precious" | openssl sha1
2e71c9ae2ef57194955feeaa99f8543ea4cd9f9f
If the hashes are different, then we can assume that the value has changed.
Can you spot an opportunity here? What about using SHA-1 to store data and just keep track of everything by comparing hashes?
That's exactly what Git does internally 🤯.
🔵 Git and SHA-1
Git uses SHA-1 to generate hashing of everything and stores it in the .git/objects folder. Simple like that!
The plumbing command hash-object does the job:
$ echo "my precious" | git hash-object --stdin
8b73d29acc6ae79354c2b87ab791aecccf51701f
Let's compare with the OpenSSL version:
$ echo -e "my precious" | openssl sha1
fa628c8eeaa9527cfb5ac39f43c3760fe4bf8bed
Oooops...it's quite different. That's because Git prepends a specific word followed by the content size and the delimiter \0. Such a word is what Git calls the object type.
Yes, Git objects have types. The first one we'll look into is the blob object.
🔵 The blob object
When we send for instance the string "my precious" to the hash-object command, Git prepends the pattern {object_type} {content_size}\0 to the SHA-1 function, so that:
blob 12\0myprecious
Then:
$ echo -e "blob 12\0my precious" | openssl sha1
8b73d29acc6ae79354c2b87ab791aecccf51701f
$ echo "my precious" | git hash-object --stdin
8b73d29acc6ae79354c2b87ab791aecccf51701f
Yay! 🎉
🔵 Storing blobs in the database
But the command hash-object itself does not persist into the .git/objects folder. We should append the option -w and the object will be persisted:
$ echo "my precious" | git hash-object --stdin -w
8b73d29acc6ae79354c2b87ab791aecccf51701f
$ find .git/objects
...
.git/objects/8b
.git/objects/8b/73d29acc6ae79354c2b87ab791aecccf51701f
### Or, simply
$ find .git/objects -type f
.git/objects/8b/73d29acc6ae79354c2b87ab791aecccf51701f

🔵 Reading the raw content of a blob
We already know that for cryptographic reasons it's not possible to read the raw content from its hashing version.
🤔 Ok, but wait.
How does Git get to know the original value?
It uses the hash as a key pointing to a value, which is the original content itself using a compression algorithm called Zlib, that compacts the content and stores it in the object database, hence saving storage space.
The plumbing command cat-file does the job so that, given a key, inflates the compressed data thus getting the original content:
$ git cat-file -p 8b73d29acc6ae79354c2b87ab791aecccf51701f
my precious
In case you are guessing, that's right, Git is a key-value database!

🔵 Promoting blobs
When using Git, we want to work on the content and share them with other people.
Commonly, after working on various files/blobs, we are ready to share them and sign our names for the final work.
In other words, we need to group, promote and add metadata to our blobs. This process works as follows:
Add the blob to a staging area
Group all blobs in the stage area into a tree structure
Add metadata to the tree structure (author name, date, a semantic message)
Let's see the above steps in detail.
🔵 Stage area, the index
The plumbing command update-index allows to add a blob to the stage area and give a name to it:
$ git update-index \
--add \
--cacheinfo 100644 \
8b73d29acc6ae79354c2b87ab791aecccf51701f \
index.txt
--add: adds the blob to the stage, also called the index--cacheinfo: used to register a file that is not in the working directory yetthe blob hash
index.txt: a name for the blob in the index

Where does Git store the index?
$ cat .git/index
DIRCsҚjT¸zQp index.txtÆ
7CJVVÙ
It's not human-readable though, it's compressed using Zlib.
We can add as many blobs to the index as we want, for example:
$ git update-index {sha-1} f1.txt
$ git update-index {sha-1} f2.txt
After adding blobs to the index, we can group them into a tree structure which is ready to be promoted.
🔵 The tree object
When using the plumbing command write-tree, Git groups all blobs that were added to the index and create another object in the .git/objects folder:
$ git write-tree
3725c9e313e5ae764b2451a8f3b1415bf67cf471
Checking the .git/objects folder, note that a new object was created:
$ find .git/objects
### The new object
.git/objects/37
.git/objects/37/25c9e313e5ae764b2451a8f3b1415bf67cf471
### The blob previously created
.git/objects/8b
.git/objects/8b/73d29acc6ae79354c2b87ab791aecccf51701f
Let's retrieve the original value using cat-file to understand better:
### Using the option -t, we get the object type
$ git cat-file -t 3725c9e313e5ae764b2451a8f3b1415bf67cf471
tree
$ git cat-file -p 3725c9e313e5ae764b2451a8f3b1415bf67cf471
100644 blob 8b73d29acc6ae79354c2b87ab791aecccf51701f index.txt
That's an interesting output, it's quite different from the blob which returned the original content.
In the tree object, Git returns all the objects that were added to the index.
100644 blob 8b73d29acc6ae79354c2b87ab791aecccf51701f index.txt
100644: the cacheinfoblob: the object typethe blob hash
the blob name

Once the promotion is done, time to add some metadata to the tree, so we can declare the author's name, date and so on.
🔵 The commit object
The plumbing command commit-tree receives a tree, a commit message and creates another object in the .git/objects folder:
$ git commit-tree 3725c -m 'my precious commit'
505555f4f07d90ae14a0f2e67cba7f7b9af539ee
What kind of object is it?
$ find .git/objects
...
.git/objects/50
.git/objects/50/5555f4f07d90ae14a0f2e67cba7f7b9af539ee
### cat-file
$ git cat-file -t 505555f4f07d90ae14a0f2e67cba7f7b9af539ee
commit
What about its value?
$ git cat-file -p 505555f4f07d90ae14a0f2e67cba7f7b9af539ee
tree 3725c9e313e5ae764b2451a8f3b1415bf67cf471
author leandronsp <leandronsp@example.com> 1678768514 -0300
committer leandronsp <leandronsp@example.com> 1678768514 -0300
my precious commit
tree 3725c: the referencing tree objectauthor/committer
the commit message my precious commit

🤯 OMG! Am I seeing a pattern here?
Furthermore, commits can reference other commits:
$ git commit-tree 3725c -p 50555 -m 'second commit'
5ea578a41333bae71527db537072534a199a0b67
Where the option -p allows referencing a parent commit:
$ git cat-file -p 5ea578a41333bae71527db537072534a199a0b67
tree 3725c9e313e5ae764b2451a8f3b1415bf67cf471
parent 505555f4f07d90ae14a0f2e67cba7f7b9af539ee
author leandronsp <leandronsp@gmail.com> 1678768968 -0300
committer leandronsp <leandronsp@gmail.com> 1678768968 -0300
second commit
We can see that, given a commit with a parent, we can traverse all commits recursively, through all their trees until we get to the final blobs.
A potential solution:
$ git cat-file -p <first-commit-sha1>
$ git cat-file -p <first-commit-tree-sha1>
$ git cat-file -p <first-commit-parent-sha1>
$ git cat-file -p <parent-commit-sha1>
...
And so on. Well, you got to the point.
🔵 Log for the rescue
The porcelain git log command solves that problem, by traversing all commits, their parents and trees, giving us a perspective of a timeline of our work.
$ git log 5ea57
commit 5ea578a41333bae71527db537072534a199a0b67
Author: leandronsp <leandronsp@gmail.com>
Date: Mon Mar 13 22:42:48 2023 -0300
second commit
commit 505555f4f07d90ae14a0f2e67cba7f7b9af539ee
Author: leandronsp <leandronsp@gmail.com>
Date: Mon Mar 13 22:35:14 2023 -0300
my precious commit
🤯 OMG!
Git is a giant yet lightweight key-value graph database!
🔵 The Git Graph
Within Git, we can manipulate objects like pointers in graphs.
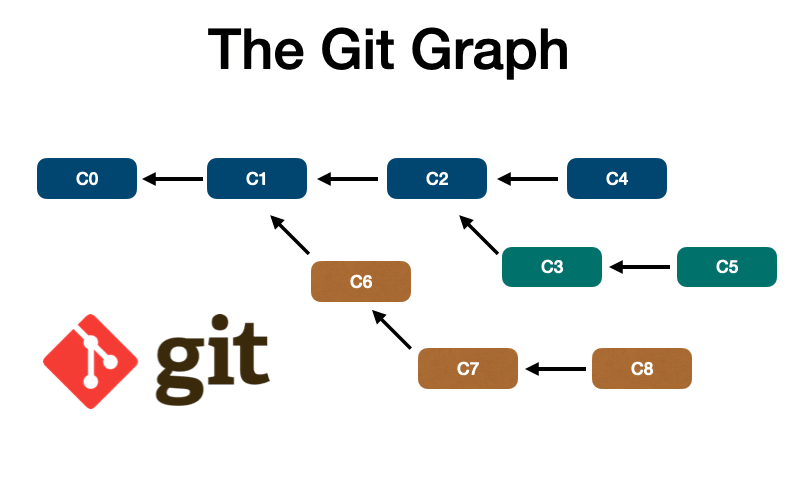
Blobs are data/files snapshots
Trees are set of blobs or another tree
Commits reference trees and/or other commits, adding metadata
That's super nice and all. But using sha1 in the git log command can be cumbersome.
What about giving names to hashes? Enter References.
Git References
References are located in the .git/refs folder:
$ find .git/refs
.git/refs/
.git/refs/heads
.git/refs/tags
🔵 Giving names to commits
We can associate any commit hash with an arbitrary name located in the .git/refs/heads, for instance:
echo 5ea578a41333bae71527db537072534a199a0b67 > .git/refs/heads/test
Now, let's issue git log using the new reference:
$ git log test
commit 5ea578a41333bae71527db537072534a199a0b67
Author: leandronsp <leandronsp@gmail.com>
Date: Mon Mar 13 22:42:48 2023 -0300
second commit
commit 505555f4f07d90ae14a0f2e67cba7f7b9af539ee
Author: leandronsp <leandronsp@gmail.com>
Date: Mon Mar 13 22:35:14 2023 -0300
my precious commit
Even better, Git provides the plumbing command update-ref so we can use it to update the association of a commit to a reference:
$ git update-ref refs/heads/test 5ea578a41333bae71527db537072534a199a0b67
Sounds familiar, uh? Yes, we are talking about branches.
🔵 Branches
Branches are references that point to a specific commit.
As branches represent the update-ref command, the commit hash can change at any time, that is, a branch reference is mutable.

For a moment, let's think about how a git log without arguments work:
$ git log
fatal: your current branch 'main' does not have any commits yet
🤔 Hmmm...
How does Git get to know that my current branch is the "main"?
🔵 HEAD
The HEAD reference is located in .git/HEAD. It's a single file that points to a head reference (branch):
$ cat .git/HEAD
ref: refs/heads/main
Similarly, using a porcelain command:
$ git branch
* main
Using the plumbing command symbolic-ref, we can manipulate to which branch the HEAD points:
$ git symbolic-ref HEAD refs/heads/test
### Check the current branch
$ git branch
* test
Like update-ref on branches, we can update the HEAD using symbolic-ref at any time.

In the picture below, we'll change our HEAD from the main branch to the fix branch:

Without arguments, the git log command traverses the root commit that is referenced by the current branch (HEAD):
$ git log
commit 5ea578a41333bae71527db537072534a199a0b67 (HEAD -> test)
Author: leandronsp <leandronsp@gmail.com>
Date: Tue Mar 14 01:42:48 2023 -0300
second commit
commit 505555f4f07d90ae14a0f2e67cba7f7b9af539ee
Author: leandronsp <leandronsp@gmail.com>
Date: Tue Mar 14 01:35:14 2023 -0300
my precious commit
Until now, we learned architecture and main components in Git, along with the plumbing commands, which are more low-level commands.
Time to associate all this knowledge with the porcelain commands we use daily.
🍽️ The porcelain commands
Git brings more high-level commands that we can use with no need to manipulate objects and references directly.
Those commands are called porcelain commands.
🔵 git add
The git add command takes files in the working directory as arguments, saves them as blobs into the database and adds them to the index.

In short, git add:
runs
hash-objectfor every file argumentruns
update-indexfor every file argument
🔵 git commit
git commit takes a message as the argument, groups all the files previously added to the index and creates a commit object.
First, it runs write-tree:

Then, it runs commit-tree:

$ git commit -m 'another commit'
[test b77b454] another commit
1 file changed, 1 deletion(-)
delete mode 100644 index.txt
🕸️ Manipulating pointers in Git
The following porcelain commands are widely used, which manipulate the Git references under the hood.
Assuming we just cloned a project where the HEAD is pointing to the main branch, which points to the commit C1:

How can we create another new branch from the current HEAD and move the HEAD to this new branch?
🔵 git checkout
By using the git checkout with the -b option, Git will create a new branch from the current one (HEAD) and move the HEAD to this new branch.
### HEAD
$ git branch
* main
### Creates a new branch "fix" using the same reference SHA-1
#### of the current HEAD
$ git checkout -b fix
Switched to a new branch 'fix'
### HEAD
$ git branch
* fix
main
Which plumbing command is responsible for moving the HEAD? Exactly, symbolic-ref.

Afterwards, we do some new work on the fix branch and then perform a git commit, which will add a new commit called C3:

By running git checkout, we can keep switching the HEAD across different branches:

Sometimes, we may want to move the commit that a branch points to.
We already know that the plumbing command update-ref does that:
$ git update-ref refs/heads/fix 356c2
In porcelain language, let me introduce you to the git reset.
🔵 git reset
The git reset porcelain command runs update-ref internally, so we just need to perform:
$ git reset 356c2
But how does Git know the branch to move? Well, git reset moves the branch that HEAD is pointing to.

What about when there are differences between revisions? By using reset, Git moves the pointer but leaves all the differences in the stage area (index).
$ git reset b77b
Checking with git status:
$ git status
On branch fix
Untracked files:
(use "git add <file>..." to include in what will be committed)
another.html
bye.html
hello.html
nothing added to commit but untracked files present (use "git add" to track)
The revision commit was changed in the fix branch and all the differences were moved to the index.
Still, what should we do in case we want to reset AND discard all the differences? Just passing on the option --hard:

By using git reset --hard, any difference between revisions will be discarded and they won't appear in the index.
💡 Golden tip about moving a branch
In case we want to perform the plumbing update-ref on another branch, there's no need to checkout the branch like needed in git reset.
We can perform the porcelain git branch -f source target instead:
$ git branch -f main b77b
Under the hood, it performs a git reset --hard in the source branch. Let's check to which commit the main branch is pointing:
$ git log main --pretty=oneline -n1
b77b454a9a507f839880879a895ac4f241177a28 (main) another commit
Also, we confirm that the fix branch is still pointing to the 369cd commit:
$ git log fix --pretty=oneline -n1
369cd96b1f1ef6fa7de1ff2ed12e15be979dcffa (HEAD -> fix, test) add files
We did a "git reset" without moving the HEAD!

Not rare, instead of moving a branch pointer, we want to apply a specific commit to the current branch.
Meet cherry-pick.
🔵 git cherry-pick
With the porcelain git cherry-pick, we can apply an arbitrary commit to the current branch.
Take the following scenario:

main points to C3 - C2 - C1
fix points to C5 - C4 - C2 - C1
HEAD points to fix
In the fix branch, we are missing the C3 commit, which is being referenced by the main branch.
We can apply it by running git cherry-pick C3:

Note that:
the C3 commit will be cloned into a new commit called C3'
this new commit will reference the C5 commit
fix will move the pointer to C3'
HEAD keeps pointing to fix
After applying changes, the graph will be represented as follows:

There's another way to move the pointer of a branch though. It consists of applying an arbitrary commit of another branch but merging the differences if needed.
You're not wrong, we're talking about git merge here.
🔵 git merge
Let's describe the following scenario:

main points to C3 - C2 - C1
fix points to C4 - C3 - C2 - C1
HEAD points to the main
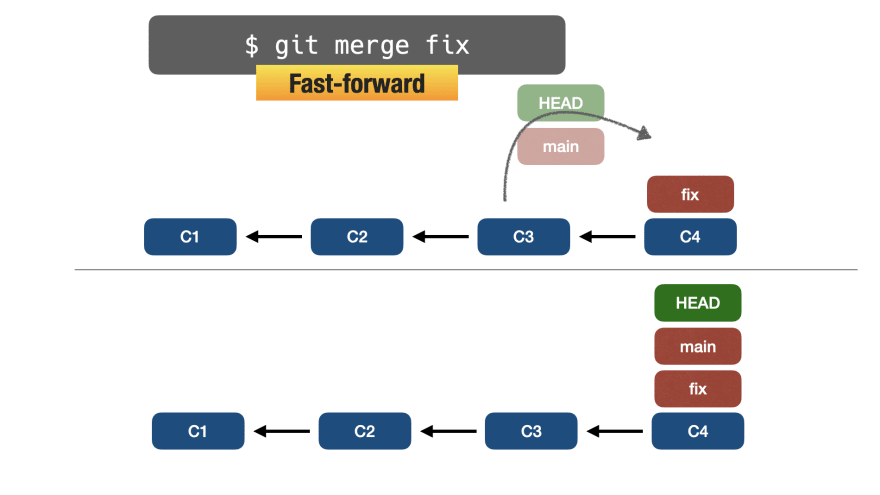
We want to apply the fix branch into the current (main) branch, a.k.a perform a git merge fix.
Please note that the fix branch contains all commits belonging to the main branch (C3 - C2 - C1), having only one commit ahead of the main (C4).
In this case, the main branch will be "forwarded", pointing to the same commit as the fix branch.
This kind of merge is called fast-forward, as described in the image below:
When fast-forward is not possible
Sometimes, our tree structure current's state does not allow fast-forward. Take the scenario below:

That's when the merge branch - fix branch in the above example -, is missing one or more commits from the current branch (main): the C3 commit.
As such, fast-forward is not possible.
However, for the merge to succeed, Git performs a technique called Snapshotting, composed of the following steps.
First, Git looks to the next common parent of the two branches, in this example, the C2 commit.

Secondly, Git takes a snapshot of the target C3 commit branch:

Third, Git takes a snapshot of the source C5 commit branch:

Lastly, Git automatically creates a commit merge (C6) and points it to two parents respectively: C3 (target) and C5 (source):

Have you ever wondered why your Git tree displays some commits that were created automatically?
Make no mistake, this merge process is called the three-way merge!

Next, let's explore another merge technique where fast-forward is not possible, but instead of snapshotting and automatic commit merge, Git applies the differences on top of the source branch.
Yes, that's the git rebase.
🔵 git rebase
Consider the following image:

main points to C3 - C2 - C1
fix points to C5 - C4 - C2 - C1
HEAD points to fix
We want to rebase the main branch into the fix branch, by issuing git rebase main. But how does git rebase work?
👉 git reset
First, Git performs a git reset main, where the fix branch will point to the same main branch pointer: C3 - C2 - C1.

At this moment, the C5 - C4 commits have no references.
👉 git cherry-pick
Second, Git performs a git cherry-pick C5 into the current branch:
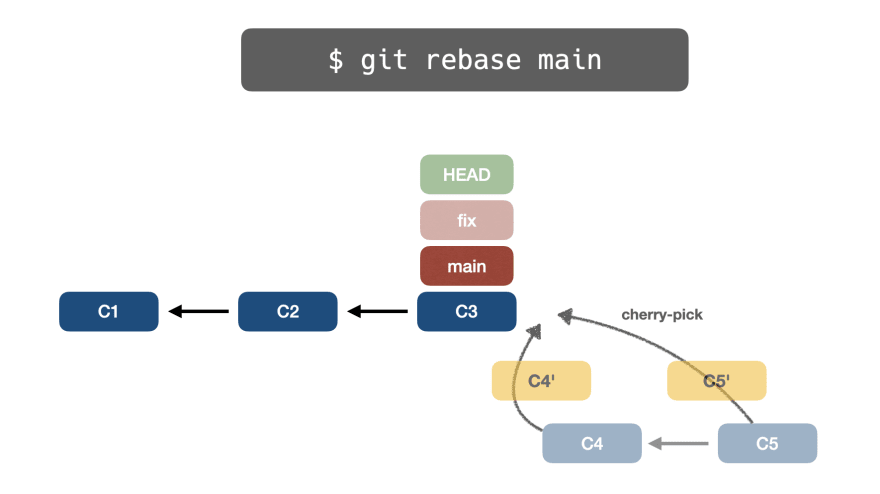
Note that, during a cherry-pick process, the cherry-picked commits are cloned, thus the final hash will change: C5 - C4 becomes C5' - C4'.
After cherry-pick, we may have the following scenario:

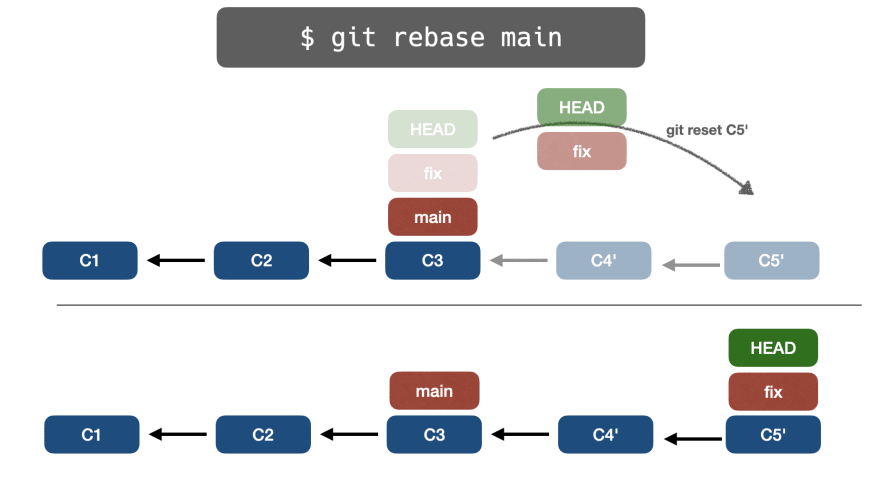
👉 git reset again
Lastly, Git will perform a git reset C5', so the fix branch pointer will move from C3 to C5'.
The rebase process is finished.
So far, we've been working with local branches, i.e on our machine. Time to learn how to work with remote branches, which are synced with remote repositories on the internet.
🌐 Remote Branches
To work with remote branches, we have to add a remote to our local repository, using the porcelain command git remote.
$ git remote add origin git@github.com/myaccount/myrepo.git
Remotes are located in the .git/refs/remotes folder:
$ find .git/refs
...
.git/refs/remotes/origin
.git/refs/remotes/origin/main
🔵 Download from remote
How do we synchronize the remote branch with our local branch?
Git provides two steps:
👉 git fetch
By using the porcelain git fetch origin main, Git will download the remote branch and synchronize it with a new local branch called origin/main, also known as the upstream branch.

👉 git merge
After fetching and syncing the upstream branch, we can perform a git merge origin/main and because the upstream is ahead of our local branch, Git will safely apply a fast-forward merge.

However, fetch + merge could be repetitive, as we would synchronize local/remote branches multiple times a day.
But today is our lucky day, and Git provides the git pull porcelain command, that performs fetch + merge on our behalf.
👉 git pull
With git pull, Git will perform fetch (synchronize remote with the upstream branch), and then merge the upstream branch into the local branch.

Okay, we've seen how to pull/download changes from the remote. On the other hand, how about sending local changes to remote?
🔵 Upload to remote
Git provides a porcelain command called git push:
👉 git push
Performing git push origin main will first upload the changes to remote:

Then, Git will merge the upstream origin/main with the local main branch:

At the end of the push process, we have the following image:

Where:
The remote was updated (local changes pushed to the remote)
main points to C4
origin/main points to C4
HEAD points to the main
🔵 Giving immutable names to commits
Until now, we learned that branches are simply mutable references to commits, that's why we can move a branch pointer at any time.
However, Git also provides a way to give immutable references, which cannot have their pointers changed (unless you delete them and create them again).
Immutable references are helpful when we want to label/mark commits that are ready for some production release, for example.
Yes, we are talking about tags.
👉 git tag
Using the porcelain git tag command, we can give names to commits but we cannot perform reset or any other command which would change the pointer.

It's quite useful for release versioning. Tags are located in the .git/refs/tags folder:
$ find .git/refs
...
.git/refs/tags
.git/refs/tags/v1.0
If we want to change the tag pointer, we must delete it and create another one with the same name.
💡 Git reflog
Last but not least, there's a command called git reflog which keeps all the changes we've made in our local repository.
$ git reflog
369cd96 (HEAD -> fix, test) HEAD@{0}: reset: moving to main
b77b454 (main) HEAD@{1}: reset: moving to b77b
369cd96 (HEAD -> fix, test) HEAD@{2}: checkout: moving from main to fix
369cd96 (HEAD -> fix, test) HEAD@{3}: checkout: moving from fix to main
369cd96 (HEAD -> fix, test) HEAD@{4}: checkout: moving from main to fix
369cd96 (HEAD -> fix, test) HEAD@{5}: checkout: moving from fix to main
369cd96 (HEAD -> fix, test) HEAD@{6}: checkout: moving from main to fix
369cd96 (HEAD -> fix, test) HEAD@{7}: checkout: moving from test to main
369cd96 (HEAD -> fix, test) HEAD@{8}: checkout: moving from main to test
369cd96 (HEAD -> fix, test) HEAD@{9}: checkout: moving from test to main
369cd96 (HEAD -> fix, test) HEAD@{10}: commit: add files
b77b454 (main) HEAD@{11}: commit: another commit
5ea578a HEAD@{12}:
It's quite useful if we want to go back and forth on the Git timeline. Along with reset, cherry-pick and similar, it's a powerful tool if we want to master Git.
Wrapping Up
What a long journey!
This article was a bit too long, but I could express the main topics I think are important to understand about Git.
I hope that, after reading this article, you should be more confident while using Git, resolving daily conflicts and painful situations during a merge/rebase process.
Follow me on twitter and check out my website blog leandronsp.com, where I also write some tech articles.
Cheers!
This content originally appeared on DEV Community and was authored by Leandro Proença
Leandro Proença | Sciencx (2023-03-15T03:02:32+00:00) Git fundamentals, a complete guide. Retrieved from https://www.scien.cx/2023/03/15/git-fundamentals-a-complete-guide/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.