
This content originally appeared on Bits and Pieces - Medium and was authored by Jamie Wen
How over-engineering harms the business even though it may improve developers’ technical skills
It was a typical story. I joined a new company and work in a small and innovative team to help the business to find the product-market fit. The team has a startup culture and one of its core values is to “be bold”.
The team developed a new website that follows a straightforward 3-tier architecture - front end, API, and database. All seems to be good so far. During my onboarding, I was told that we have a customised data lake base on S3 & Lambda & SNS. My first reaction was like “Yeah, Data Lake🎉”. (It was very popular back then). It would be the foundation to enable the “Big Data” in the future. However, quickly I realised we only have about 5K records. Is it “Big” Data 🙄.
Anyway, let’s go through the iterations of the Data Lake.
The iterations of the Data Lake
Version 0: Why Data Late? Why not database?
We need to deal with a lot of data. How big is big? Relational database is boring. What’s wrong with boring tech stack? What the business goal is?
I believe that failure can be avoided if someone asks the right questions in the beginning. However, it occurred a couple of years ago when micro-service were a popular trend.
Version 1: Simple start
It is a very common pattern that many teams use for basic use cases including my current team. It works perfectly fine with data being fed into a raw bucket, a lambda listens to the bucket events and transform the data and store it in a production bucket. So far so good.

Version 2: Handle event spike
Soon, we realised that lambda could get throttled when large amount files were being written into the raw bucket.
- 🤔 How can I control the event throughput?
- 🚧 We need a message queue — SQS

Version 3: Notify results
With an SQS in between, lambda doesn’t throttle, but it still can fail.
- 🤔 How can I get notified when the lambda fails
- 🚧 Add a SNS topic for user to subscribe for notifications
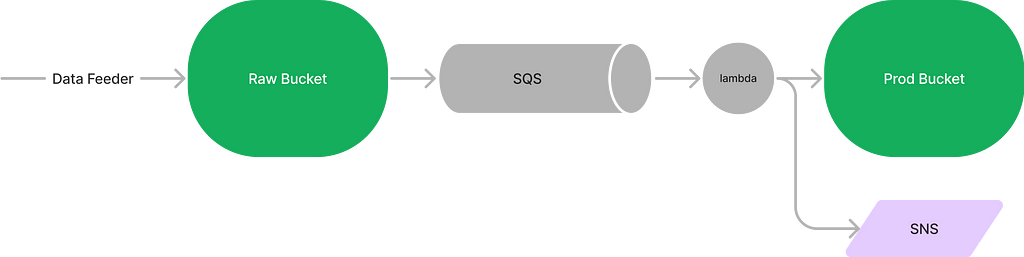
When error occurs, we need a place to hold the failed message for future troubleshooting and fixings
- 🤔 Where to store those failed messages?
- 🚧 Add a Dead Letter Queue
- 🤔 How to replay failed messages after the bug being fixed
- 🚧 A dev tool to move messages from the DL queue to the main queue
Version 3: Optimise reading latency
Reading data out of the data lake is slow that is because it is based on S3. We should not expect the performance in the first place, right?
- 🤔 How can I accelerate the read operations?
- 🚧 Add a RDS instance as a catelog database and store all files in the RDS instance // odd isn’t it :)

Version 4: Handle variations (specific > generic)
The files being ingested are in various shapes, requiring different logic to read and transform into the desired shapes.
- 🤔 How to handle those variations
- 🚧 Config as code
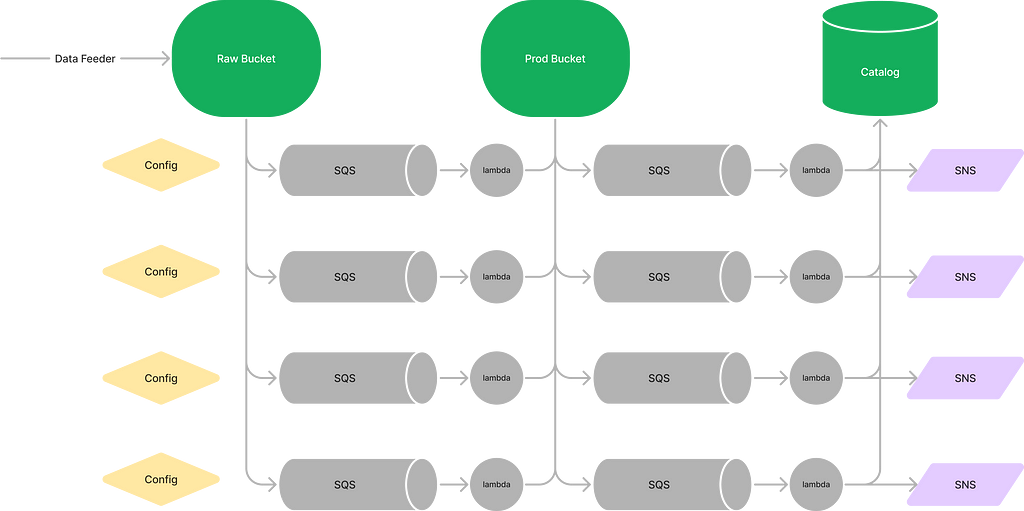
Version next: Lots of small optimisations
We continue put efforts to optimise the Data Lake because we already invest so much, it is just too big to fail. “Let’s get it done quickly” shown in our OKRs every quarter, never ending.
Developers workaround the lake
During the iterations of the data lake, questions pop up every now and then. Why we need a lake? Why not use a database? What’s the benefits? Why? Why? Why?
There wasn’t any alignment around the software architecture within the team. Shall we continue optimise it or move away to a database. No clear answer, so developers started to detour.
The team created a RDS instance and put all data in it. We didn’t hit the ceiling of a relational database and we were not even close to the ceiling.
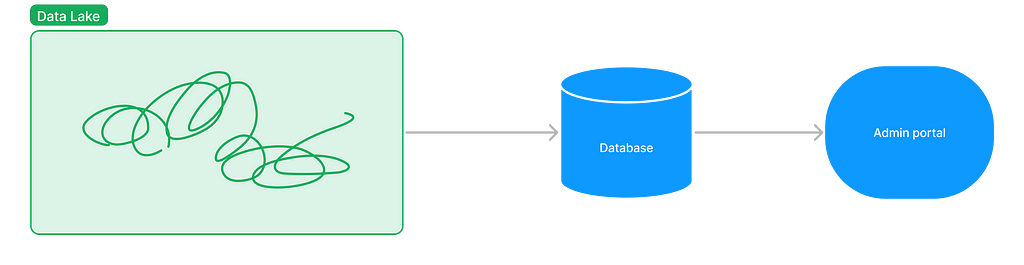
Remove the lake
It is a big commitment. We already had lots of systems built on top of it. The migration was also complicated and took lots of efforts. Lots of learnings, I will share it in a future post. Bye,

Final Thoughts
- Technical decisions should always begin with considering its business value
- Data Lake itself is a good concept. It is also a complex one. It beyond the capabilities of a small web development team.
- Don’t recreate wheels. Maybe you can buy one
- If you are unsure, it is better to start with a relational database
- If things are too hard to achieve, take a step back and re evaluate your decision
From monolithic to composable software with Bit

Bit’s open-source tool help 250,000+ devs to build apps with components.
Turn any UI, feature, or page into a reusable component — and share it across your applications. It’s easier to collaborate and build faster.
Split apps into components to make app development easier, and enjoy the best experience for the workflows you want:
→ Micro-Frontends
→ Design System
→ Code-Sharing and reuse
→ Monorepo
Learn more
- How We Build Micro Frontends
- How we Build a Component Design System
- How to reuse React components across your projects
- 5 Ways to Build a React Monorepo
- How to Create a Composable React App with Bit
Lessons Learned From a Failed Microservice Architecture was originally published in Bits and Pieces on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Bits and Pieces - Medium and was authored by Jamie Wen
Jamie Wen | Sciencx (2023-03-15T07:56:34+00:00) Lessons Learned From a Failed Microservice Architecture. Retrieved from https://www.scien.cx/2023/03/15/lessons-learned-from-a-failed-microservice-architecture/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.