
This content originally appeared on DEV Community and was authored by Lena Jeremiah
Web scraping, in simple terms, is a technique used to collect useful data from a website. You'd agree that there's a ton of information on the internet, and most times, this information might not be structured exactly how we want. So, web scraping allows us to extract data from the internet, which can then be restructured or rearranged so that it is useful to us.
In this article, I'll be taking you step-by-step through the web scraping process, providing you with useful advice on how to develop your skills, tips on what to do and what not to do when scraping websites (copyright infringement in particular), and much more. Additionally, we'd scrape two websites, CoinMarketCap and Bitcoin.com, to get the prices of cryptocurrencies and to get latest news about Bitcoin.
Prerequisites
- Basic programming skill. Although we will be using Python in this article, you can still benefit from it even if you are familiar with other programming languages.
- A fundamental understanding of HTML, HTML elements and attributes, etc.
- Knowledge of Chrome DevTools (not required)
- A computer or other tool for running Python code.
Let me quickly introduce you to two packages: requests and BeautifulSoup. They are Python libraries that you use to scrape websites. In this article, we'd require them.
The Web-scraping Process
When you go to your browser and input the url of the website you want to visit, your browser makes a request to the server. The server then responds to your browser. The browser receives data from the server as text, HTML, JSON, or a multipart request (media file).
When the browser receives HTML, it parses it, generates DOM nodes, and renders it to the page, displaying the lovely website on your screen.

When scraping websites, we need this HTML content, and that introduces us to the first package requests.
Requests
As the name suggests, it's used for sending requests to servers. If you have any experience in frontend development or Javascript, it's the equivalent of fetch API in Javascript.
For us to be able to scrape website content, we need to ensure that end server endpoint we're calling returns HTML.
After getting the HTML, the next course of action is to collect the data we need. And this brings us to the second package BeautifulSoup.
Beautiful Soup
Beautiful Soup is a library used for pulling data out of HTML and XML files. Beautiful soup contains a lot of very useful utilities, which makes web-scraping really easy.
Building the Scrapers (Writing Code)
After much talk, let's get into the crux of the matter, writing code and building the actual web-scrapers.
I've created a Github repo which contains the code for the scrapers. The complete code is at the completed branch, checkout to the get-started branch to get started.
I'll be creating the project from scratch in this article, for those who might not want to clone a Github repo.
PROJECT SETUP
- Create a new folder. Name it whatever you want.
- Set up a new virtual environment.
Run the following commands to set up a new virtual environment
# if you've not already installed virtualenv
pip install virtualenv
# you can name your environment whatever you want
python -m venv <name_of_environment>
After running the previous commands successfully, you should see folder with the name of the virtual environment you just created.
You also need to activate the virtual environment. To do that, run the following commands depending on your OS.
# macOS / linux
source ./<virtual_env_name>/bin/activate
# windows
<virtual_env_name>/Scripts/activate.bat # In CMD
<virtual_env_name>/Scripts/Activate.ps1 # In Powershell
- Install the required packages.
Having activated our virtual environment, let's go on ahead to install the packages. To do so, run the following in your terminal:
pip install requests beautifulsoup4
- Generate a
requirements.txtfile.
If you'll be sharing with code with someone or a team, it's important that the other party installs the exact same package version you used to build the project. There could be breaking changes to the package used, so it's important that everybody uses the same version. A requirements.txt file lets others know the exact version of the packages you used on the project.
To generate a requirements.txt file, just run:
pip freeze > requirements.txt
After running this, you should see a file containing the packages required to run the project.
If you're working in a team and there's a requirements.txt file in the project, run pip install -r requirements.txt to install the exact version of the packages in the requirements.txt file.
How many times did I say requirements.txt file?🤡
- Add a .gitignore file.
This is used to indicate to git the files or folders to ignore when you run git add . Add /<virtual_env_name> to your .gitignore file.

Scraping Bitcoin.com.
Now, we'll be scraping the first website. The first thing we need to do is to get the HTML with requests.
So, create a file bitcoinnews.py (you can name it whatever you want).
Add the following code to the file
import requests
def get_news():
url = '<https://news.bitcoin.com>'
response = requests.get(url) # making a request
response_text = response.text # getting the html
# here's where we should get the news content from the html, we're just printing the content to the terminal for now
print(response_text)
get_news()
A bit on HTML and frontend development
When scraping websites, it's important that we understand basic HTML as this would help us decide the best way to extract our data.
HTML (HyperText Markup Language) is the standard markup language for creating webpages. HTML is used to describe the structure of a web page. HTML elements are the building blocks of every webpage. HTML elements are related to one another in a way that resembles a tree.

In the diagram above, we have the root element, the <html> element, which has two children, the <head> and <body> elements. The <head> tag has a single child, the <title> tag which has text as simple text as its child. The <body> has three children (one heading tag and two paragraph tags).
This tree-like structure facilitates the composition of elements and the definition of relationships between them. It makes it simple to write a paragraph and include links within it.
HTML elements, in addition to having children, have attributes, which add a lot more functionality to them. An 'image' element would require the source of the image it is supposed to display. When you click on a link (anchor tag), it needs to know where you want to go. Attributes can also be used to distinguish between a single element and a group of elements.
Understanding HTML attributes is really important because when scraping a website, we need specific data and it's important we can target the elements that have the data we need.
If you want to learn more about HTML, you can check out W3schools.com
Scraping top crypto prices from CoinMarketCap.
Before we get back to our Bitcoin News scraper, let's scrape the prices of the top cryptocurrencies from CoinMarketCap, alongside the images.
TIP: Before you start scraping a website, disable Javascript and open the page in that browser. This is significant because some websites display content on the webpage using client-side Javascript, which cannot be used by our scrapers. So it only makes sense to see the exact HTML that the server is returning.
With Javascript running

Without Javascript running

If you open coinmarketcap.com on a browser with Javascript disabled, you'd notice that you can only get the prices for the first ten cryptocurrencies. You'd also notice that on a browser where Javascript is enabled, you can scroll to get prices of other cryptocurrencies. This difference in the look of page (HTML) can cause you a lot of trouble when scraping a website.
Back to the code editor
- Create a new file. You can call it whatever you want. I called mine
coinmarketcap.py - Add the following code to it.
import requests
from bs4 import BeautifulSoup
def get_crypto_prices():
url = '<https://coinmarketcap.com>'
response_text = requests.get(url).text
soup = BeautifulSoup(response_text, 'html.parser') #added this line
print(soup)
get_crypto_prices()
This looks almost exactly like the previous file, I only changed the URL and function name, and also added the line with BeautifulSoup.
That line of code parses the HTML text we get from the endpoint and converts it to a BeautifulSoup object which has methods we can use to extract information from the text.
Now that we have access to the HTML, let's figure out how to scrape the data we need: in our case, prices of cryptocurrencies.
- Open up DevTools on your web browser.
If you're using Chrome on a Mac, you can press
Cmd + Option + Ito open up DevTools.

Or you can just right click on the target element and click inspect.

If you look at the elements in the Inspect Element section of Chrome DevTools, you'd notice that there's a table element which children. Inside the table element, we have the colgroup, thead, tbody elements. The tbody element contains all the content of the table. Inside the tbody element, you'd notice that we have a tr which denotes a table row, which also contains multiple td elements. td denotes table data.
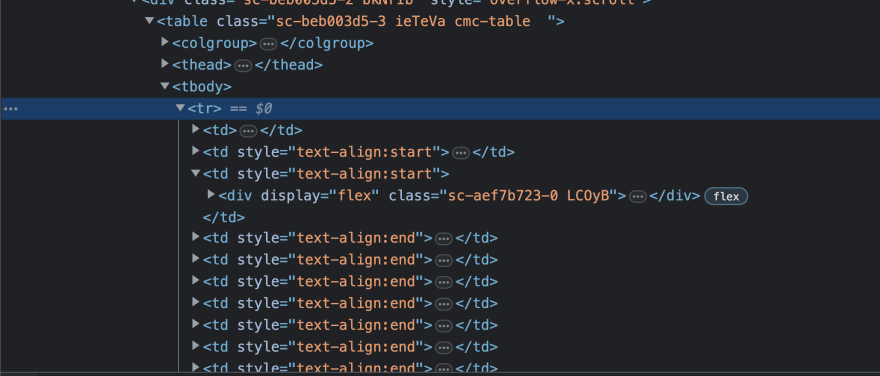
Now, just knowing that the data we need is inside of table isn't enough. We have to dig deeper into the HTML tree to be able to extract the exact data we need. In this case, we need the name of the cryptocurrency, the shortened name e.g. BTC for Bitcoin, the current price and the image of the cryptocurrency.

If you look closely, you'd notice that the name of the cryptocurrency is in a paragraph tag with the class sc-e225a64a-0 ePTNty. The shortened name of the cryptocurrency is also in a paragraph tag with a different class name sc-e225a64a-0 dfeAJi coin-item-symbol.
We use attributes like class and id to uniquely identify HTML elements or groups of familiar HTML elements. When we have these distinct attributes, we can use them to target the elements and extract the values we need from them.
What we've done so far?
From analysing Coinmarketcap's website, we've seen that data of each cryptocurrency is in a row and each row has children that contains data we'd like to scrape.
Let's get back to the code editor and update our coinmarketcap.py file
import requests
from bs4 import BeautifulSoup
def get_crypto_prices():
url = '<https://coinmarketcap.com>'
response_text = requests.get(url).text
soup = BeautifulSoup(response_text, 'html.parser')
# get all the table rows
table_rows = soup.findAll('tr')
# iterate through all the table rows and get the required data
for table_row in table_rows:
crypto_name = table_row.find('p', class_ = 'sc-e225a64a-0 ePTNty')
shortened_crypto_name = table_row.find('p', class_ = 'sc-e225a64a-0 dfeAJi coin-item-symbol')
coin_img = table_row.find('img', class_ = 'coin-logo')
print(crypto_name, shortened_crypto_name)
get_crypto_prices()
Notice the difference between findAll and find
If you run the above code, you'd get this

You can see that some of the data is returning None. This is as a result of the remaining table rows which are empty. What we can do here is to check to see if there is a value before printing the values.
Updating our for loop, we have this:
# iterate through all the table rows and get the required data
for table_row in table_rows:
crypto_name = table_row.find('p', class_ = 'sc-e225a64a-0 ePTNty')
shortened_crypto_name = table_row.find('p', class_ = 'sc-e225a64a-0 dfeAJi coin-item-symbol')
coin_img = table_row.find('img', class_ = 'coin-logo')
if crypto_name is None or shortened_crypto_name is None:
continue
else:
crypto_name = crypto_name.text
shortened_crypto_name = shortened_crypto_name.text
coin_img = coin_img.attrs.get('src')
print(crypto_name, shortened_crypto_name)
If there's a value for crypto_name or shortened_crypto_name, we get the text from the HTML element and print it to the console. We also get the src of the crypto image.
Running the updated code, we should have this:

Now, let's get the prices for each cryptocurrency.
Going back to our Chrome Devtools and right-clicking on the price text, we should see this:

We see that the price of the currency is in a span tag, which is wrapped in an anchor tag: the a tag, which has a class value of cmc-link. However, using the class of the anchor tag to scrape the price won't work because the class cmc-link does not uniquely identify the element we're attempting to target.
const bitcoinRow = document.querySelectorAll('tr')[1]
const cmcLinks = bitcoinRow.querySelectorAll('.cmc-link')
console.log(cmcLinks) // NodeList(4) [a.cmc-link, a.cmc-link, a.cmc-link, a.cmc-link]
If you run the Javascript code above in the browser console, you'd see that there are four links with the class name cmc-link in every row. This is definitely not the best way to get the price of the crypto at that row.
Let's look at the parent: the div with the class name sc-8bda0120-0 dskdZn
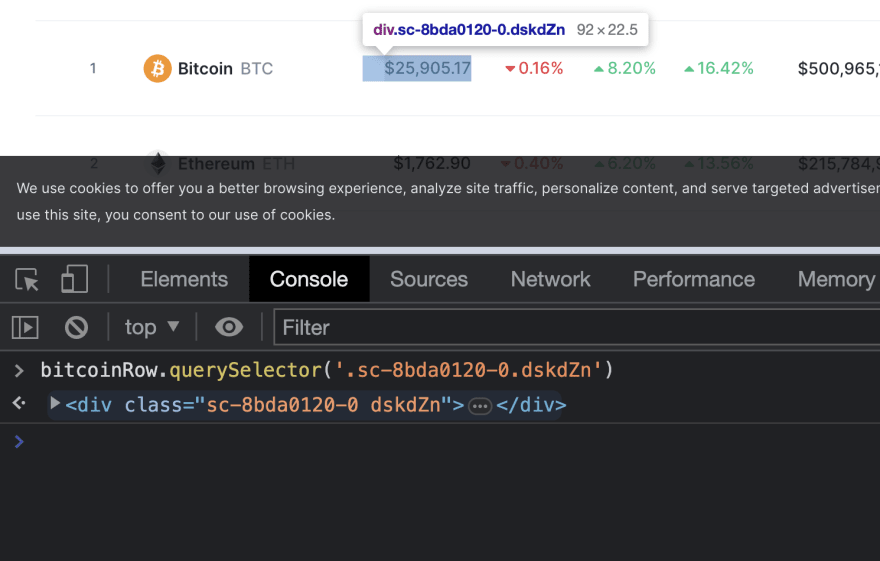
Notice that when the element is hovered on the console, the price is also hovered on the web page. So, this proves to be a better way to get the price of the cryptocurrency.
Updating the code, we have:
import requests
from bs4 import BeautifulSoup
def get_crypto_prices():
url = '<https://coinmarketcap.com>'
response_text = requests.get(url).text
soup = BeautifulSoup(response_text, 'html.parser')
# get all the table rows
table_rows = soup.findAll('tr')
# iterate through all the table rows and get the required data
for table_row in table_rows:
crypto_name = table_row.find('p', class_ = 'sc-e225a64a-0 ePTNty')
shortened_crypto_name = table_row.find('p', class_ = 'sc-e225a64a-0 dfeAJi coin-item-symbol')
coin_img = table_row.find('img', class_ = 'coin-logo')
crypto_price = table_row.find('div', class_ = 'sc-8bda0120-0 dskdZn')
if crypto_name is None or shortened_crypto_name is None or crypto_price is None:
continue
else:
crypto_name = crypto_name.text
shortened_crypto_name = shortened_crypto_name.text
coin_img = coin_img.attrs.get('src')
crypto_price = crypto_price.text
print(f"Name: {crypto_name} ({shortened_crypto_name}) \\nPrice: {crypto_price} \\nImage URL: {crypto_img_url}\\n")
get_crypto_prices()
Running the updated code, we should get this:

Whooopppsssssss... That was a lot to process. I hope you were able to follow through.
Grab that cup of coffee, you deserve it👍
Going back to scraping Bitcoin News
Now, with the knowledge we've gained from scraping Coinmarketcap, we can go on ahead to complete our Bitcoin News scraper. We'd be using this scraper to get the latest news in the crypto space.
Right-clicking on the first news and opening the Inspect Elements section of Chrome Devtools would reveal that news headlines have a story class. However, if you right-click on more news headlines, you'd discover that they are variations to the news. There's the medium story, small, huge, tiny, etc, with different class names to uniquely identify each type.
A very important skill required for web-scraping is the ability to take a close look at how the HTML of a webpage is structured. As long as you understand the structure of a webpage, extracting useful content from the elements is a small task.
Heading back to the code editor:
import requests
def get_news():
url = '<https://news.bitcoin.com>'
response = requests.get(url) # making a request
response_text = response.text # getting the html
print(response_text)
soup = BeautifulSoup(response_text, 'html.parser')
all_articles = soup.findAll('div', class_ = 'story')
for article in all_articles:
print(article.text.strip())
get_news()
When you run the above code, you might get this:
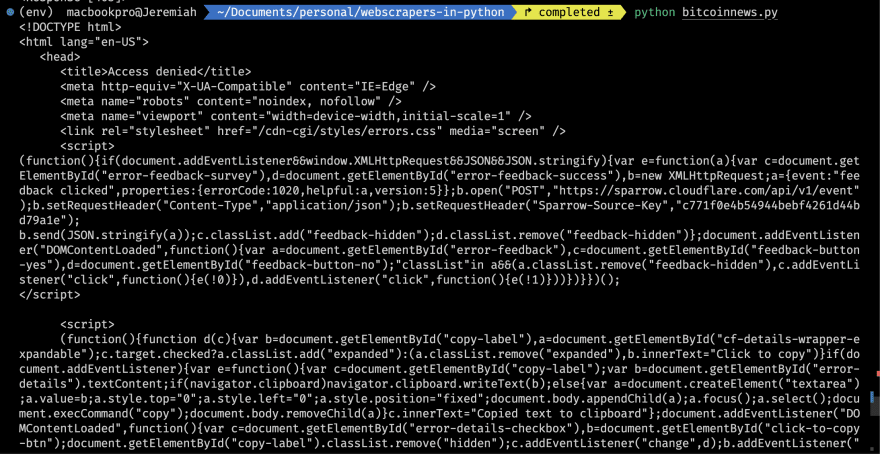
To prevent malicious bots from accessing their website, some websites employ Cloudflare Bot Management. Cloudflare maintains a list of known good bots that are granted access to the website, such as search engines, copyright bots, chat bots, site monitoring bots, and so on. Unfortunately for web-scraping enthusiasts like you and me, they also assume all non-whitelisted bot traffic is malicious.
However, they are a number of ways this can be bypassed and the ease depends on how much of a threat our bot poses to Cloudflare and the Bot Protection plan the website owner subscribed for.
A list of ways to avoid Cloudflare can be found here. Click here to learn more about Cloudflare Bot Management.
In this article, we'll look at the most basic, which is setting the User-Agent header. By doing so, we pretend to the server that the request is coming from a regular web browser.
def get_news():
url = '<https://news.bitcoin.com>'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
response = requests.get(url, headers=headers)
# the rest of the code
After adding the above line of code and running it, we should get this:
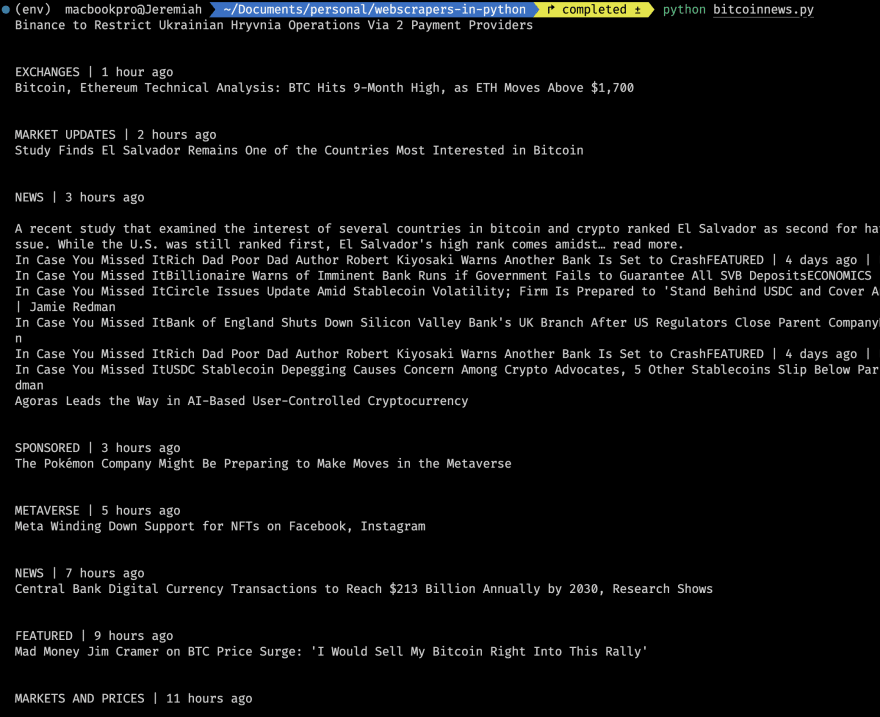
Now that we have the actual web content, let's go to our browser to inspect the webpage:
Right-clicking on the first news there, we should see this:
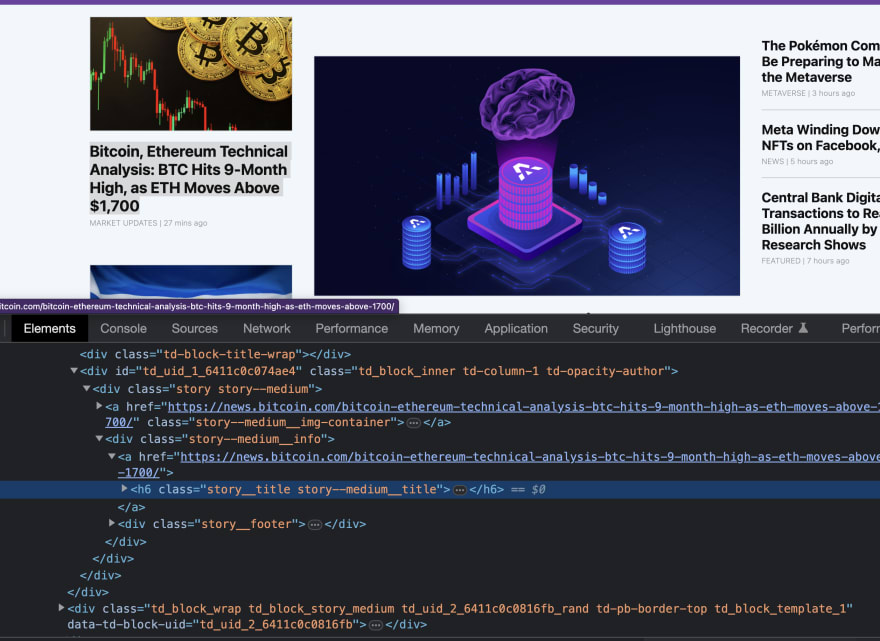
Scraping news headline
Notice that the h6 element has a class of story__title story--medium__title. If you right-click on another news, you might see something like story__title story--huge__title, or story__title story--large__title. Notice how there's already a pattern: the headline of each news always has the class of story__title. That seems like the best way to target the headline of the news.
Scraping news URLs
If you look closely, you'd notice that the news title has a parent which is a link. This link contains the URL of the news in it's href attribute.
Putting all of these together, we can write the code for the scraper.
import requests
from bs4 import BeautifulSoup
def get_news():
url = '<https://news.bitcoin.com>'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
} # headers to bypass Cloudflare Protection
response = requests.get(url, headers=headers)
response_text = response.text
soup = BeautifulSoup(response_text, 'html.parser')
all_articles = soup.findAll('div', class_ = 'story')
for article in all_articles:
news_title_element = article.select_one('.story__title')
news_url = news_title_element.parent.attrs.get('href')
news_title = news_title_element.text.strip()
print(f"HEADLINE: {news_title} \\nURL: {news_url}\\n")
get_news()
Running the above code, we have the news headline and the URL

Utilising scraped data
Now that we've successfully scraped required data from the websites, let's save the scraped data. If you're working with a database, you could immediately save it to the data, you could perform computations with the data, you could save it for future use, whatever the case is, data you've scraped is not very useful in the console.
Let's do something really simple: save the data in a JSON file
import requests
from bs4 import BeautifulSoup
import json
# some code
all_articles = soup.findAll('div', class_ = 'story')
scraped_articles = []
for article in all_articles:
news_title_element = article.select_one('.story__title')
news_url = news_title_element.parent.attrs.get('href')
news_title = news_title_element.text.strip()
scraped_articles.append({
"headline": news_title,
"url": news_url
})
with open ('news.json', 'w') as file:
news_as_json = json.dumps({
'news': scraped_articles,
'number_of_news': len(scraped_articles)
}, indent = 3, sort_keys = True)
file.write(news_as_json)
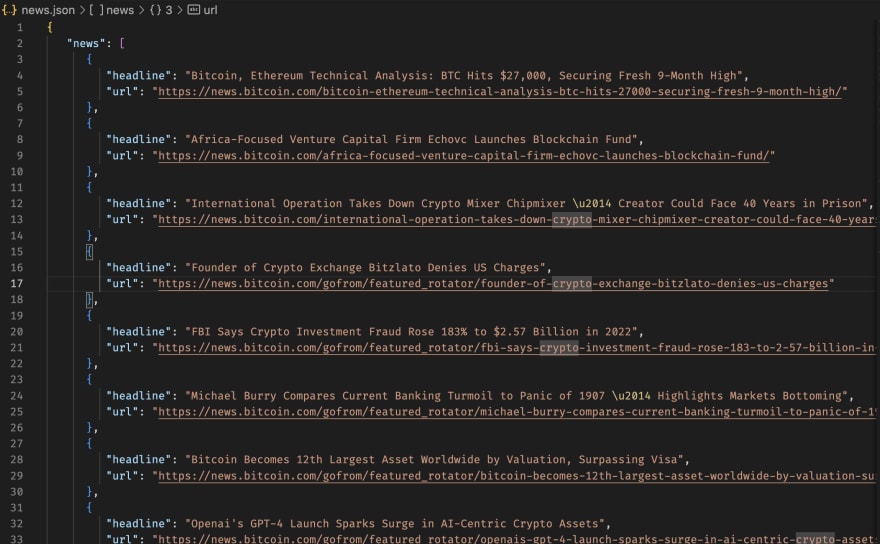
Now, we're saving saved news in a JSON file, which can be used for whatever you want.
Your JSON file should look something like this.
Whooopppsssss.⚡️⚡️ That was a whole lot to take in.
What not to do when scraping websites
- Overloading the servers with too many requests at a time. The reason why many websites frown against bots is their frequent abuse. When you make a request, the server uses resources to be able to process the request. Making a ton of requests might make the server run out of resources, which isn't good.
"""
⛔️ DON'T DO THIS
"""
for i in range(10000):
request.get('<https://reallyamazingwebsite.com>')
Your IP address might get blacklisted.
- Disrespecting copyright rules. Web scraping is completely legal if you scrape data publicly available on the internet. But some kinds of data are protected by international regulations, so be careful scraping personal data, intellectual property, or confidential data. Some websites might openly state that content on the page should not be distributed by any other means, that should be respected.
You've finally made it to the end of the article, well-done champ.
Conclusion
In conclusion, web scraping in Python can be a useful tool for gathering information from websites for a variety of purposes. Python provides a user-friendly and efficient way to extract structured data from websites through the use of popular libraries such as BeautifulSoup. However, it is critical to remember that web scraping should always be done ethically and in accordance with the terms of service of the website. It is also critical to be aware of any legal constraints that may apply to the data that is being scraped. With these factors in mind, Python web scraping can be a useful skill for anyone looking to collect and analyse data from the web.
If you enjoyed reading this article, you can follow help share on your socials and follow me on social media.
This content originally appeared on DEV Community and was authored by Lena Jeremiah
Lena Jeremiah | Sciencx (2023-03-17T14:04:58+00:00) Practical Guide to Web-scraping in Python. Retrieved from https://www.scien.cx/2023/03/17/practical-guide-to-web-scraping-in-python/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.