
This content originally appeared on DEV Community and was authored by Leandro Proença
In this post we're going to see how the SQL JOIN works, guided by a practical example while covering SQL and Set theory basics.
Even though you're not familiar with SQL, you can follow along as this post covers the very basics.
❕ A little disclaimer
As you may already know, every time I want to explain something, it's my modus operandi to take a step back and deep dive into the fundamentals.
But if you are comfortable with set theory and SQL basics such as CREATE TABLE, INSERT INTO, generate_series, SELECT and FROM, you may want to jump to the "JOIN to the world" section.
So fasten your seat belts and let's go into the journey of understanding SQL JOIN.
❗ First things first
The examples described here were tested using PostgreSQL 15.
Despite SQL being a standard DSL that should work on any RDBMS, please review the examples before running on other RDBMS but PostgreSQL.
Without further ado, let's start the journey to understanding SQL JOINs.
🗝️ Back to the basics
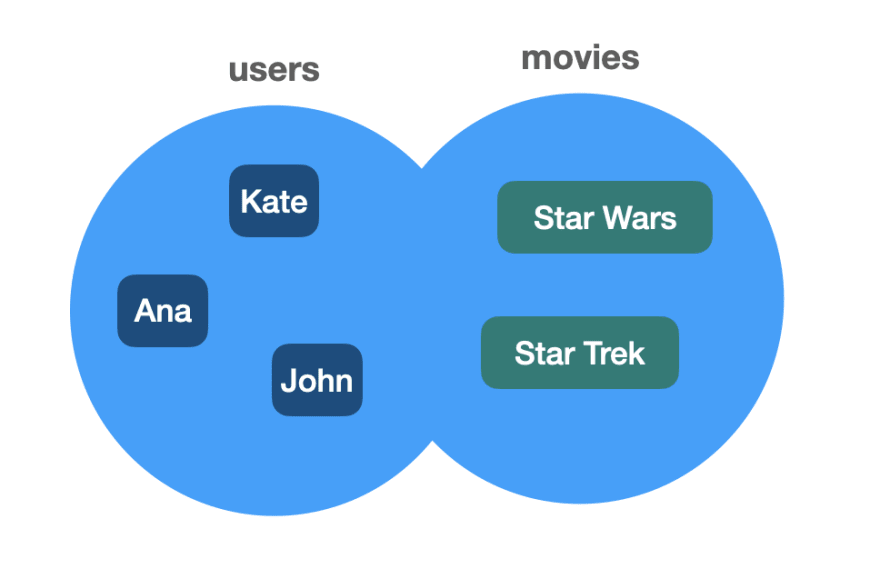
In SQL, tables are related to set theory in mathematics. Usually, a set is a collection of different things, for instance:

Expressing the set above as a tuple:
(Ana, Star Wars, Star Trek, Kate, John)
However, we can also represent users and movies as two distinct sets:

Which can be expressed as tuples as well:
users = (Ana, Kate, John)
movies = (Star Wars, Star Trek)
Using sets, we can perform some mathematical operations such as:
- UNION: users ∪ movies
- INTERSECTION: users ∩ movies
- DIFFERENCE: users - movies
- CARTESIAN PRODUCT: users × movies
We'll take a closer look at set operations in the upcoming sections as we relate them to SQL.
👉 SQL basics
In SQL, tables are relations that are physically persisted. An SQL table can be seen as a set in set theory.
But how do structure a set in SQL without persisting physical tables?
🔵 SELECT
With the SELECT keyword, we can structure a set as follows:
postgres=# SELECT 'John';
?column?
----------
John
(1 row)
But that's a one-element set. We should add more items to the collection.
PostgreSQL provides a set-returning function called generate_series:
postgres=# SELECT generate_series(1, 3);
generate_series
-----------------
1
2
3
(3 rows)
We could add more and more information to the SELECT:
SELECT
generate_series(1, 3),
generate_series(1, 3);
generate_series | generate_series
-----------------+-----------------
1 | 1
2 | 2
3 | 3
(3 rows)
However we're not yet satisfied. The SELECT should be capable of "projecting fields" coming from a structure that is already a set.
Meet SQL FROM.
🔵 FROM
SQL FROM is a keyword used to specify a set of elements and, combined with the SELECT, we could define our first set:
SELECT
*
FROM
generate_series(1, 3) AS id;
id
----
1
2
3
(3 rows)
Using a single FROM we can project multiple columns with SELECT:
SELECT
id,
'User-' || id AS name
FROM
generate_series(1, 3) AS id;
Which should print the output:
id | name
----+-------
1 | User-1
2 | User-2
3 | User-3
(3 rows)
Take for instance that we have two sets:
- the first set containing
(User-1, User-2, User-3) - and a second set containing
(User-2, User-3, User-4, User-5)
Now, time to explore some operations using the two sets.
🔵 UNION and UNION ALL
The SQL UNION operator combines the result of two or more sets, i.e SELECT statements:
SELECT id, 'User-' || id AS name
FROM generate_series(1, 3) AS id
UNION
SELECT id, 'User-' || id AS name
FROM generate_series(2, 5) AS id;
Which outputs:
id | name
----+-------
2 | User-2
3 | User-3
1 | User-1
5 | User-5
4 | User-4
(5 rows)
The UNION operator removes all duplicates in the result. But in case we want to also return duplicates, we can use UNION ALL:
SELECT id, 'User-' || id AS name
FROM generate_series(1, 3) AS id
UNION ALL
SELECT id, 'User-' || id AS name
FROM generate_series(2, 5) AS id;
Output:
id | name
----+-------
1 | User-1
2 | User-2
3 | User-3
2 | User-2
3 | User-3
4 | User-4
5 | User-5
(7 rows)
The result outputs 7 rows: 3 from the first SELECT and 4 from the second SELECT, including the duplicates User-2 and User-3.
Also, keep in mind some rules about SQL UNION:
- every set must have the same number of columns
- the columns in both sets must be in the same order
An illustrated example:

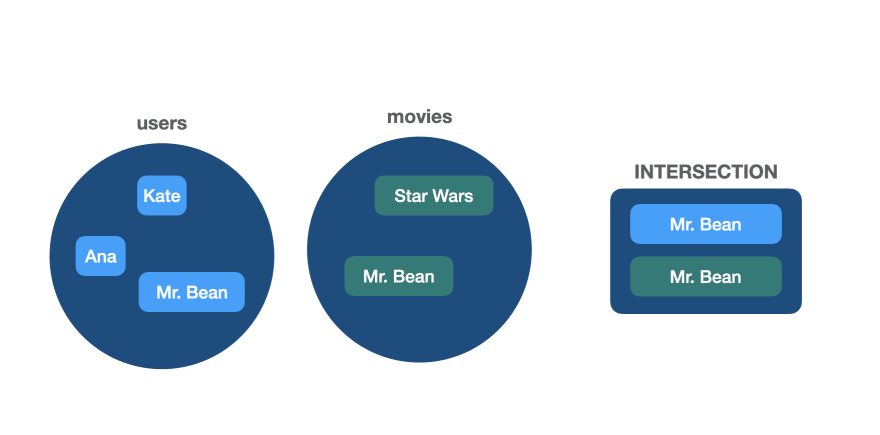
🔵 INTERSECT
The SQL INTERSECT operator also combines the result of two or more sets, but only return rows from the first set (first SELECT) that are identical to a row in the second set (second SELECT).
SELECT id, 'User-' || id AS name
FROM generate_series(1, 3) AS id
INTERSECT
SELECT id, 'User-' || id AS name
FROM generate_series(2, 5) AS id;
Output:
id | name
----+--------
3 | User-3
2 | User-2
(2 rows)
Here, the query returned only the identical rows found in both sets. That's exactly the "intersection" between the two sets.
An illustrated example:
🔵 EXCEPT
Another important operator is the SQL EXCEPT, which in the set theory is the DIFFERENCE (A - B).
This operator also combines the result of two or more sets, but only return rows of the first set (first SELECT) that are not present in the second set (second SELECT).
SELECT id, 'User-' || id AS name
FROM generate_series(1, 3) AS id
EXCEPT
SELECT id, 'User-' || id AS name
FROM generate_series(2, 5) AS id;
Output:
id | name
----+--------
1 | User-1
(1 row)
Just 1 row. The only one that is present in the first set (left) but not in the second (right). We can also invert the sets and get the differences in reverse:
SELECT id, 'User-' || id AS name
FROM generate_series(2, 5) AS id
EXCEPT
SELECT id, 'User-' || id AS name
FROM generate_series(1, 3) AS id;
Which are the User-5 and User-4 respectively:
id | name
----+--------
5 | User-5
4 | User-4
(2 rows)
An illustrated example:

Once we understand some SQL basics and how those relate to set theory in mathematics, it's time to go beyond and explore a more sophisticated example.
💡 A more sophisticated example
So far, we've been experimenting SQL operators with sets on the fly by using the generate_series PostgreSQL function.
Did you notice that we haven't create any table? That's a good alternative to experiment and learn ad hoc.
But for a more sophisticated example we'll start persisting data into pyshical tables.
🔵 CREATE TABLE
Using CREATE TABLE, we can define a structure for a particular set of elements.
Such table structure is represented by a matrix of rows and columns, where rows are essentially a collection of values whereas columns define the type of values.
Let's create a table called users:
CREATE TABLE users (id INTEGER, name VARCHAR(250));
- id is the name of the first column. It only allows values of type integer
-
name is the name of the second column. It only allows values of type "character varying up to 250 bytes"
(VARCHAR(250))
Now, we can query the table using FROM and SELECT:
SELECT
id,
name
FROM
users;
Output:
id | name
----+------
(0 rows)
Of course, there's no data inserted into the table. Let's insert some data.
🔵 INSERT INTO
The command INSERT INTO allows to insert a collection of values into an existing table.
INSERT INTO users (id, name)
VALUES (1, 'John'), (2, 'Ana'), (3, 'Kate');
Note that the VALUES clause accepts a collection of tuples. Each tuple matches the columns (id, name) respectively.
Now, if we execute the query again, we get the output:
id | name
----+------
1 | John
2 | Ana
3 | Kate
Yay! Our first table was created!
Now let's create another table called movies, which will contain the same number of columns as users, id and name respectively.
Afterwards, we follow inserting some data into the movies table.
CREATE TABLE movies (id INTEGER, name VARCHAR(250));
INSERT INTO movies (id, name)
VALUES (1, 'Star Wars'), (2, 'Star Trek');
💡 Tip
If we want to SELECT all the columns from a table, we can use the symbol *
SELECT * FROM movies;
id | name
----+-----------
1 | Star Wars
2 | Star Trek
(2 rows)
Until now, we learned some basic operations that are used to combine data between two simple sets:
- UNION
- INTERSECT
- EXCEPT
Next, it's time to explore some other operations between users and movies.
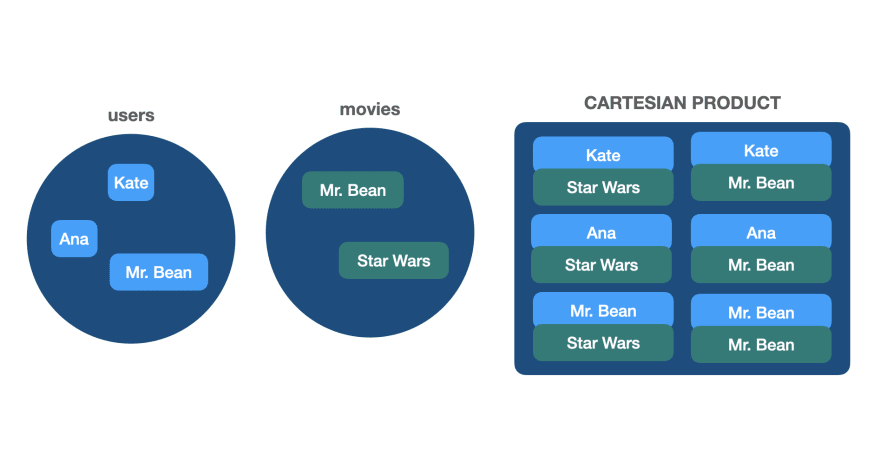
👉 A Cartesian Product
In set theory, a cartesian product is a combination of every element from one set to every element of another set.
As for our example, it's like combining every pair user-movie:
users = (John, Ana, Kate)
movies = (Star Wars, Star Trek)
### The cartesian product
(John, Star Wars)
(John, Star Trek)
(Ana, Star Wars)
(Ana, Star Trek)
(Kate, Star Wars)
(Kate, Star Trek)
In SQL, it's the operator CROSS JOIN.
🔵 CROSS JOIN
The SQL CROSS JOIN keyword is used to build a cartesian product, a.k.a the cartesian join.
SELECT * FROM users
CROSS JOIN movies;
It outputs every combination between the two tables:
id | name | id | name
----+------+----+-----------
1 | John | 1 | Star Wars
1 | John | 2 | Star Trek
2 | Ana | 1 | Star Wars
2 | Ana | 2 | Star Trek
3 | Kate | 1 | Star Wars
3 | Kate | 2 | Star Trek
(6 rows)
🥁 It's all good, man! 🥁
💡 An even more sophisticated example
Suppose that users can give a rating (not mandatory) for every movie they watch.
Let's create another table called movies_ratings that associates:
- a user
- a movie
- a rating
In SQL, it's a good practice using relationships, thus avoiding redundancy and stale data.
Such relationships are defined using ID's as "foreign keys". So, in the movies_rating table, a user is represented by its ID and a movie is represented by its ID.
CREATE TABLE movies_ratings
(user_id INTEGER, movie_id INTEGER, rating INTEGER);
And insert some data into it:
INSERT INTO
movies_ratings (user_id, movie_id, rating)
VALUES
(1, 1, 7),
(1, 2, 8),
(2, 1, 6),
(2, 2, 10);
When we query this table, we get the following output:
user_id | movie_id | rating
---------+----------+--------
1 | 1 | 7
1 | 2 | 8
2 | 1 | 6
2 | 2 | 10
(4 rows)
The schema should look like the following:

For reporting, we'd like to combine the data of movies_ratings with users and movies so we can display their names, something like that:
name | movie | rating
------+-----------+--------
Ana | Star Trek | 10
John | Star Trek | 8
John | Star Wars | 7
Ana | Star Wars | 6
(4 rows)
Once we got a third table into the game - the movies_ratings table -, and because its structure differs form the other two tables, we can no longer use basic set operators such as UNION, INTERSECT or EXCEPT to combine data between different tables.
We need something like a cartesian product, but not doing every combination, only under certain conditions, based on a related column.
That's what we're going to explore in the next section: a world of JOINs.
🥁 JOIN to the world
With SQL JOIN, we can combine rows across different tables but applying a specific condition.
The clause may have different types of JOIN depending on the situation.
In case we want to combine all data from the first table (left) with the second table (right), but discarding the rows that do not appear in both tables, we use INNER JOIN.
🔵 INNER JOIN
Should we combine all the values from users with movies_ratings, discarding rows that don't appear in both tables:
SELECT * FROM users
INNER JOIN movies_ratings ON movies_ratings.user_id = users.id;
Output:
id | name | user_id | movie_id | rating
----+------+---------+----------+--------
1 | John | 1 | 1 | 7
1 | John | 1 | 2 | 8
2 | Ana | 2 | 1 | 6
2 | Ana | 2 | 2 | 10
(4 rows)
Note that:
- John voted two times
- Ana too
- Kate haven't registered any vote, so Kate was discarded in the INNER JOIN

💡 Note
In PostgreSQL, we can useINNER JOINor simplyJOIN. By default, without specifying the JOIN type, PostgreSQL will perform an INNER JOIN
But what if we wanted to display even Kate in the JOIN but with null values? In other words, how to keep every row in both tables even if the condition wasn't satisfied?
🔵 FULL OUTER JOIN
The SQL FULL OUTER JOIN will keep every row from both tables even if the condition wasn't satisfied.
SELECT * FROM users
FULL OUTER JOIN movies_ratings ON movies_ratings.user_id = users.id;
Which produces the output:
id | name | user_id | movie_id | rating
----+------+---------+----------+--------
1 | John | 1 | 1 | 7
1 | John | 1 | 2 | 8
2 | Ana | 2 | 1 | 6
2 | Ana | 2 | 2 | 10
3 | Kate | | |
(5 rows)

💡 Note
In PostgreSQL, we can useFULL OUTER JOINor simplyFULL JOIN
Also, SQL provides another type of JOIN, which combines two tables (left and right) but keeps all rows from the left table only, even if they do not appear in the right table.
Yes, we are talking about the LEFT OUTER JOIN.
🔵 LEFT OUTER JOIN
The SQL LEFT OUTER JOIN will keep every row from the left table even if they do not appear in the right table.
SELECT * FROM users
LEFT OUTER JOIN movies_ratings ON movies_ratings.user_id = users.id;
Which produces the output:
id | name | user_id | movie_id | rating
----+------+---------+----------+--------
1 | John | 1 | 1 | 7
1 | John | 1 | 2 | 8
2 | Ana | 2 | 1 | 6
2 | Ana | 2 | 2 | 10
3 | Kate | | |
(5 rows)

💡 Note
In PostgreSQL, we can useLEFT OUTER JOINor simplyLEFT JOIN
On the other hand, there's also the opposite direction: RIGHT OUTER JOIN.
🔵 RIGHT OUTER JOIN
The SQL RIGHT OUTER JOIN will keep every row from the right table even if they do not appear in the left table.
Please note that we'll invert the tables, movies_ratings will be the left table whereas users will be the right table:
SELECT * FROM movies_ratings
RIGHT OUTER JOIN users ON movies_ratings.user_id = users.id;
Which produces the output:
user_id | movie_id | rating | id | name
---------+----------+--------+----+------
1 | 1 | 7 | 1 | John
1 | 2 | 8 | 1 | John
2 | 1 | 6 | 2 | Ana
2 | 2 | 10 | 2 | Ana
| | | 3 | Kate
(5 rows)
With the tables inverted, in case we applied LEFT JOIN, Kate would be discarded.
But as we applied RIGHT JOIN (users are in the right-side), Kate was kept in the JOIN even not appearing in the left table movies_ratings.
💡 Note
In PostgreSQL, we can useRIGHT OUTER JOINor simplyRIGHT JOIN
Putting all together
Now that we understand about different JOIN strategies in SQL, let's build a query where we display:
- the user name
- the movie title
- the rating
...keeping users who didn't vote.
Let's write the query in baby steps.
First, we project the fields in SELECT:
SELECT
users.name,
movies.name,
movies_ratings.rating
FROM users
As such, we should JOIN movies and movies_ratings tables.
Next, we'll perform a LEFT JOIN with the movies_ratings, because we want to keep all users even those who didin't vote.
SELECT
users.name,
movies.name,
movies_ratings.rating
FROM users
LEFT JOIN movies_ratings ON users.id = movies_ratings.user_id
The following step consists of joining the movies table as well.
But keep in mind that at this moment, the left table is the result of the first join and the right table will be the movies table.
So if we apply JOIN, Kate will be discarded as she doesn't appear in the movies table. We then should use LEFT JOIN as well:
SELECT
users.name,
movies.name,
movies_ratings.rating
FROM users
LEFT JOIN movies_ratings ON users.id = movies_ratings.user_id
LEFT JOIN movies ON movies.id = movies_ratings.movie_id
Lastly, let's order the results by rating in descending order.
Also, in the ORDER clause, we'll perform the NULLS LAST, so Kate will appear at the bottom of the results, and not at the top:
SELECT
users.name AS user,
movies.name AS movie,
movies_ratings.rating
FROM users
LEFT JOIN movies_ratings ON users.id = movies_ratings.user_id
LEFT JOIN movies ON movies.id = movies_ratings.movie_id
ORDER BY movies_ratings.rating DESC NULLS LAST;
Which outputs:
user | movie | rating
------+-----------+--------
Ana | Star Trek | 10
John | Star Trek | 8
John | Star Wars | 7
Ana | Star Wars | 6
Kate | |
(5 rows)
Such a big Yay!
☢️ Wait!
What if I wanted to discard users who didn't vote in the results?
No problem, you just need to perform an INNER JOIN, remember?
...
JOIN movies_ratings ON users.id = movies_ratings.user_id
JOIN movies ON movies.id = movies_ratings.movie_id
...
➕ More
Moreover, we want to display a query which only brings the number of votes for each user. Then it should display as follows:
user | votes
------+-------
Ana | 2
John | 2
Kate | 0
(3 rows)
First, we return all users JOINed with movies_ratings, projecting the users.name field:
SELECT
users.name
FROM users
LEFT JOIN movies_ratings ON users.id = movies_ratings.user_id
name
------
John
John
Ana
Ana
Kate
(5 rows)
Now, we want to group users by their names. In SQL, we can use the clause GROUP BY.
SELECT
users.name
FROM users
LEFT JOIN movies_ratings ON users.id = movies_ratings.user_id
GROUP BY users.name
name
------
Kate
Ana
John
(3 rows)
Next, we want to project another field in the SELECT, which are the count of votes of each user.
PostgreSQL provides a function called COUNT, which does the job: you can count on an arbitrary field that belongs to a selected projection.
SELECT
users.name,
COUNT(movies_ratings.rating) AS votes
FROM users
LEFT JOIN movies_ratings ON users.id = movies_ratings.user_id
GROUP BY users.name
Last but not least, let's order by the counter of votes, so Kate with 0 votes will appear at the bottom:
SELECT
users.name,
COUNT(movies_ratings.rating) AS votes
FROM users
LEFT JOIN movies_ratings ON users.id = movies_ratings.user_id
GROUP BY users.name
ORDER BY COUNT(movies_ratings.rating) DESC;
And, voilà:
name | votes
------+-------
Ana | 2
John | 2
Kate | 0
(3 rows)
Wrapping Up
This post was a try to explain the basics of SQL and set theory, along with a practical example towards an explanation of different JOIN strategies.
I hope you could learn a bit more about SQL JOIN and SQL in general.
Cheers!
This content originally appeared on DEV Community and was authored by Leandro Proença
Leandro Proença | Sciencx (2023-03-17T00:39:12+00:00) SQL JOIN explained. Retrieved from https://www.scien.cx/2023/03/17/sql-join-explained/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.