
This content originally appeared on DEV Community and was authored by omarkhater
Introduction
Welcome back to my blog, where I share insights and tips on machine learning workflows using Sagemaker Pipelines. If you're new here, I recommend checking out my first post to learn more about this AWS fully managed machine learning service. In my second post, I discussed how parameterization can help you customize the workflow and make it more flexible and efficient.
After using Sagemaker Pipelines extensively in real-life projects, I've gained a comprehensive understanding of the service. In this post, I'll summarize the key benefits of using Sagemaker Pipelines and the limitations you should consider before implementing it. Whether you're a newcomer to the service or a seasoned user, you'll gain valuable insights from this concise review.
Key Features
1.Sagemaker Integration
This service is integrated with Sagemaker directly, so the user doesn't have to deal with other AWS services. Also, one can create pipelines programmatically thanks to the Sagemaker Python SDK Integration. Further, it can be used from within the console due to the seamless integration with Sagemaker Studio.
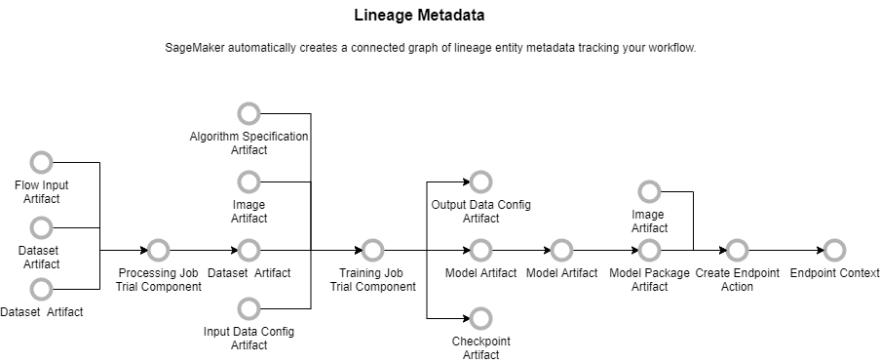
2.Data Lineage Tracking
Data lineage is the process of tracking and documenting the origin, movement, transformation, and destination of data throughout its lifecycle. It refers to the ability to trace the path of data from its creation to its current state and provides a complete view of data movement, including data sources, transformations, and destinations.
Sagemaker pipelines make this process easier as can visualized below 1.
3.Curated list of steps for all ML life cycle
Sagemaker pipeline provides a convenient way to manage the highly iterative process of ML development through something called steps. This enables easier development and maintenance either individually or within a team. Currently, it contains the following list of step types.
A more comprehensive guide on these steps is articulated in this post

4.Parallelism
There are several ways to run the ML workflows in parallel using Sagemaker pipelines. For example, it can be used to either change the data, algorithm or both. The ability to smoothly integrate with other Sagemaker capabilities greatly simplifies the process of creating repeatable and well-organized machine learning workflows.
a simple Python program to lunch many pipelines in parallel can be something like the code snippet below:
from sagemaker.workflow.pipeline import Pipeline
from multiprocessing import Process
from concurrent.futures import ThreadPoolExecutor
import datetime
def start_pipeline(Pipeline_Parameters, execution_parameters):
try:
ct_start = datetime.datetime.now()
print(f'Executing pipeline: {execution_parameters["pipeline_name"]} with the following parameters:\n')
print(Pipeline_Parameters)
for k,v in Pipeline_Parameters.items():
print(f"{k}: {v}")
pipeline = Pipeline(name = execution_parameters["pipeline_name"])
execution = pipeline.start(execution_display_name = execution_parameters["disp_name"],
execution_description = execution_parameters["execution_description"],
parameters=Pipeline_Parameters)
if execution_parameters["wait"]:
print("Waiting for the pipeline to finish...")
print(execution.describe())
## Wait for maximum 8.3 (30 seconds * 1000 attempts) hours before raising waiter error.
execution.wait(delay = 30, # The polling interval
max_attempts = 1000 # The maximum number of polling attempts. (Defaults to 60 polling attempts)
)
print(execution.list_steps())
else:
print("Executing the pipeline without waiting to finish...")
print(f'Executing pipeline: {execution_parameters["pipeline_name"]} done')
ct_end = datetime.datetime.now()
ET = (ct_end - ct_start)
print(f"Time Elapsed: {ET} (hh:mm:ss.ms)")
return execution
except Exception as E:
import sys
sys.exit(f"Couldn't run pipeline: {execution_parameters['disp_name']} due to:\n{E}")
def worer_func(process:Process):
process.join()
return process.exitcode
if __name__ == '__main__':
proc = []
# List of all required executions such as display name. Each configuation should be a dictionary
Execution_args_list = []
# List of parameters per execution. Each configuation should be a dictionary
pipeline_parameters_list = []
for Execution_args, pipeline_parameters in zip(Execution_args_list, pipeline_parameters_list):
p = Process(target=start_pipeline, args=(pipeline_parameters, Execution_args))
p.start()
proc.append(p)
with ThreadPoolExecutor(len(proc)) as pool:
tasks = []
for index,p in enumerate(proc):
tasks.append(pool.submit(worer_func, p))
for item in as_completed(tasks):
if item.result() != 0:
for process in proc:
try:
process.terminate()
except PermissionError:
pass
Limitations and areas of improvment
-
- SageMaker Pipelines doesn't support the use of nested condition steps. You can't pass a condition step as the input for another condition step.
- A condition step can't use identical steps in both branches. If you need the same step functionality in both branches, duplicate the step and give it a different name.
-
Loops:
Sagemaker pipelines doesn't provide a direct way to iterate some steps of the ML flow. For example, if you need to repeat data processing and model training until certain accuracy is met, you will have to implement this logic yourself.
-
Passing data between steps:
It is a typical situation in ML development to pass many data arrays between different steps. While Pipelines can be customized such that the developer can save and load data files from S3, this create a development bottleneck in rapid prototyping. Reading/writing data to files is an error prone in nature and the developer needs to effectively handle the errors of this process to avoid failed executions of the pipelines.
-
Operations on pipeline parameters:
Sagemaker enables using variables within the pipeline that can be changed in run time by using Pipeline Parameters. I dedicated this post to summarize in-depth this key feature of the pipeline.
Conclusions
In conclusion, Sagemaker Model Building Pipelines is a valuable service that simplifies the creation, management, and monitoring of machine learning workflows. Its integration with Sagemaker makes it easy to use without the need to deal with other AWS services, and the availability of a Python SDK enables the creation of pipelines programmatically. The service provides a curated list of steps for all stages of the ML life cycle and enables data lineage tracking, making it easier to trace the path of data throughout its lifecycle. Additionally, the service supports the parallel execution of ML workflows, which is helpful when processing large amounts of data. However, there are still some limitations that the service needs to address, such as the inability to loop through specific part of the pipelines steps. Overall, Sagemaker Model Building Pipelines is a powerful tool for data scientists and machine learning engineers, and its many features make it a valuable addition to the machine learning ecosystem.
This content originally appeared on DEV Community and was authored by omarkhater
omarkhater | Sciencx (2023-03-18T09:26:39+00:00) Service in review: Sagemaker Modeling Pipelines. Retrieved from https://www.scien.cx/2023/03/18/service-in-review-sagemaker-modeling-pipelines/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.