
This content originally appeared on DEV Community and was authored by Benjamen Pyle
Instrumenting code for observability upfront is one of the most important things that a developer can do for one's “future” self. And instrumenting for observing AWS Lambda with Datadog and Golang is actually much simpler than you could imagine. So what does that mean?
Definition
Observability is the ability to measure a systems’ state at any given time, understand how it’s performing and behaving and provides the right level of visibility into each operation in the event it needs to be inspected. The 3 pillars that I’m most familiar with are Metrics, Traces and Logs. I don’t profess to be an expert on this topic but I do understand what it means to be able to observe my services and my team’s services at scale.
First off, It is extremely important that the instrumentation be done correctly up front (or even just attempted to be done). By doing this, when things do get into production, you have the data at your finger tips to be able to resolve issues when and as they happen in addition to monitor those services in order to meet their Service Level Agreements and Service Level Objectives.
This post is not going to talk theoretically about how you might do this, but specifically show you how to set it up and deploy it so you can see what observing a Lambda with Golang and Datadog is really like. I’ve been a huge fan of Datadog for the last few years and honestly am currently working with some of the best tooling of my career. Hopefully this helps you out as you look to do something similar
What All Do We Need?
Assume an issue is happening in production and but you are receiving thousands of events an hour and you can’t easily track down what the offending block of code is. Imagine this gets even hard when you have a very distributed system where many Lambdas or ECS Tasks or EKS Tasks are running and you aren’t sure which one of those is actually causing the issue.
All you know is that a customer has phoned into your support team and they’ve alerted you to the problem. And it gets even worse that it doesn’t happen all the time, but really is more a needle in a haystack. When you have thousands of customers, it might not seem like one matters … just tell them to hit refresh.
But what if there is something underneath that causes it to happen over and over in just the same fashion? Sounds daunting. And it can be. But if you do things up front, it doesn’t have to be. Back to Metrics, Traces and Logs and let’s leave the Metrics out for a bit and focus just on the logs.
Golang Logs Levels
First, you need to make sure that you are correctly logging at the right level with the right amount of content. Let’s leave sampling and whatnot off the table and just discuss at what level you need to be sending things. Personally in production I like to send things up at ERROR level but I always like the ability to be able to tweak my log level on the fly via an environment variable. When using CDK I normally do something like this
new GoFunction(this, `SampleFunc`, {
entry: path.join(__dirname, `../src/source`),
functionName: `func-name`,
environment: {
"DD_FLUSH_TO_LOG": "true",
"DD_TRACE_ENABLED": "true",
"LOG_LEVEL": getLogLevel(props.stage) // this nugget right here
},
});
By adding in the LOG_LEVEL environment variable to this Lambda, I get the ability to change it should I want to force something a little more verbose on demand.
The below is a simple example, and you could add more “default” logic but this sets the log level from the variable passed in
lib.SetLevel(os.Getenv("LOG_LEVEL"))
For the example I’m using the very popular logrus library and then I’m setting the log formatter to be JSON
package main
import (
"context"
"os"
ddlambda "github.com/DataDog/datadog-lambda-go"
log "github.com/sirupsen/logrus"
)
func init() {
log.SetFormatter(&log.JSONFormatter{
PrettyPrint: false,
})
lib.SetLevel(os.Getenv("LOG_LEVEL"))
}
func main() {
lambda.Start(ddlambda.WrapFunction(handler, lib.DataDogConfig()))
}
func handler(ctx context.Context, event interface{}) error {
// you'd NOT use interface{} as the event
return nil
}
AWS Lambda Logging Output
What the above does is sets up the log library to output JSON and it’s going to get to written out into Cloudwatch. I usually set my Log Retention in Cloudwatch to only a day because I’m going to ship everything over to Datadog always. This is what the output looks like in Datadog. As you can from the Event Attributes on the right, everything is nice and categorized. The really cool thing about using JSON is that Datadog will display that super nice for you.
 In order to output additional elements, with logrus I use the withFields logging func.
In order to output additional elements, with logrus I use the withFields logging func.
log.WithFields(
log.Fields{
"somethingInJson": theObject,
}).Debug("Logging out the object")
So this is pretty cool. Logs going into Datadog. But how does that happen? I’m not going to jump through the hoops here for how to do this with DD, but feel free to read their documentation on the matter. It is fantastic. Just know you have options. Lambda Extensions, Forwarders or compiled in resources.
Observing Traces
Tracing in applications is just a way for you to instrument your code so that the request or event or whatever triggered your request is collected in a “context”. The trace is the parent context where all of the sub items are related. If you get 1,000 requests in a minute, you’ll have 1,000 traces.
Then inside each of those traces you’ll have things called Spans. Spans can be nested too so that each function or block that you execute gets specific attributes about it that identifies the
- name
- time started
- duration
This helps with timings of things in addition to being able to group these specific operations. Again, when using Lambda with Golang and Datadog the tooling does this really nicely and the Datadog Go library makes it super simple.
Let’s first take a look at how this shows up. Remember, Traces have Spans and Spans can have child spans inside of that parent span
First thing is a flame graph is a real nice way to view the spans. Here’s what Datadog does for me below
 ### Spans
### Spans
As you can see the top level Span is the execution of the Lambda itself. Then inside that span, I’ve got a call to DynamoDB and then a call to SQS to put an event on the queue. Also note the percentage of time each span took of the whole and then the duration that each represents. Here it is again when viewed vertically as a list
 So how did I do that? The top level span looks like this
So how did I do that? The top level span looks like this
func handler(ctx context.Context, event interface{}) error {
span, _ := tracer.SpanFromContext(ctx)
// more code here
}
And tracing AWS libraries is simple as well. You need to include the context in the request in addition to wrapping the client library. For DynamoDB here’s how that’s done. Notice the wrapping with the Datadog library
package lib
import (
"context"
"fmt"
"time"
"github.com/aws/aws-sdk-go/aws"
"github.com/aws/aws-sdk-go/aws/session"
"github.com/aws/aws-sdk-go/service/dynamodb"
"github.com/bix-digital/golang-fhir-models/fhir-models/fhir"
awstrace "gopkg.in/DataDog/dd-trace-go.v1/contrib/aws/aws-sdk-go/aws"
)
// NewDynamoDBClient inits a DynamoDB session to be used throughout the services
func NewDynamoDBClient() *dynamodb.DynamoDB {
c := &aws.Config{
Region: aws.String("us-west-2"),
}
sess := session.Must(session.NewSession(c))
sess = awstrace.WrapSession(sess,
awstrace.WithAnalytics(true),
awstrace.WithAnalyticsRate(1.0))
return dynamodb.New(sess)
}
// in another file or func
// make a call to DynaomDB
_, err = d.db.PutItemWithContext(ctx, itemInput)
Pretty simple, right? Traces and individual spans all wired up and if you followed the guidance from DD how to push into your account, you get those nice flame graphs and span lists. If by chance you are tracing HTTP requests, I’ve got an article you should look at next
Connecting it all together
So we’ve got Traces (spans) and Logs. Remember I said we’d cover metrics later. But in production if I’ve got traces/spans and logs wired up, I can filter on logs that are logged with errors and I can easily find the offending component whether it’s a Lambda or ECS tasks (or something else). Observing those Lambdas with Datadog using the Golang lib makes this super simple …
func handler(ctx context.Context, event interface{}) error {
span, _ := tracer.SpanFromContext(ctx)
newCtx := context.WithValue(ctx, "correlationId", event.MetaDetails.CorrelationId)
log.WithFields(
log.Fields{
"event": event,
"span_id": span.Context().SpanID(),
"trace_id": span.Context().TraceID(),
"correlationId": newCtx.Value("correlationId"),
}).Debugf("Logging out the event")
}
Once we’ve got a new span, each span will be assigned a span id by DD and then inside that span, we have access to the trace id itself. If you log things out with the span and trace id then you get the connectivity that you desire. And in the Datadog app, you can easily see those logs associate with the given span and vice versa. You can start from the log viewer and rotate into the APM side if you want as well. Simple view of this below showing the INFO and DEBUG level logs associated with this trace
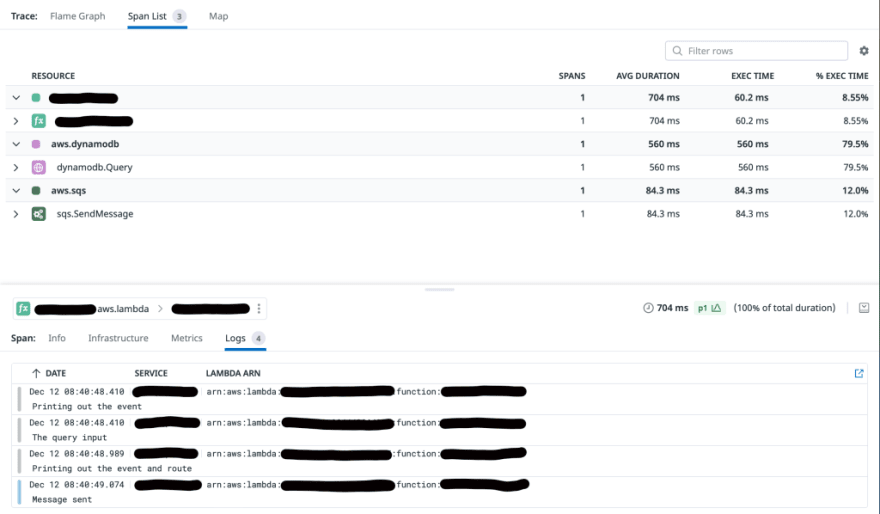
Last thing to note about all of this. You might see in the above code this field called “correlationId” which is being logged out. Why??? Simple. Imagine that an event triggers something way upstream and that one event lands in 12 functions, 8 queues and 3 kinesis streams. Wouldn’t it be nice to be able to trace the overall latency of an event? Or even trace a failure in that one specific event? If the user was presented an error and shown their “traceId”, you could then find that specific transaction and troubleshoot. And with Datadog you can use this a “facet” of the log statement and filter down on it. For more reading, this article might be a good place to start.
Wrapping up Observing Lambdas with Datadog and Golang
Lots of details in this one but hopefully it’s shown some patterns and setup for observing AWS Lambdas, with Golang and Datadog to accomplish 2 of the 3 key components of Observability. Logs, Traces and Metrics. I might do a future article on Metrics and why they are useful. But if you are doing cloud based, distributed systems, in my opinion at least having Logs and Traces and at minimum connecting them together gives you a great starting point. Observability isn’t free. You’ve got to instrument your code but it more than pays for itself with that first issue you have in production when you’ve got any kind of volume.
This content originally appeared on DEV Community and was authored by Benjamen Pyle
Benjamen Pyle | Sciencx (2023-03-20T22:26:14+00:00) Observing AWS Lambda with Golang and Datadog. Retrieved from https://www.scien.cx/2023/03/20/observing-aws-lambda-with-golang-and-datadog/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.