
This content originally appeared on DEV Community and was authored by Lucas Correia
Our team at Chili Piper has recently started migrating our backend to a microservices architecture. As a front-end developer, I've been documenting my journey and insights while tackling the challenge of handling aggregated data in this new scenario.
NOTE: I've made slight modifications to the samples to prevent any potential exposure of Chili Piper internals
First of all, what is data aggregation?
Data aggregation in the frontend involves combining and organizing data from multiple sources to display it in a way that makes sense to the user. In a microservices architecture, where services are designed to be agnostic of each other, data aggregation can be a challenge because it may require making multiple requests to different microservices to retrieve all the necessary data.
This means you will often find yourself loading entities that look like the following:
{
title: 'Billie Jean'
artistId: 'some-uuid-here'
}
To display a card with both the track title and artist name, there are several steps to follow.
- First, make a request to the tracks microservice to load the list of tracks.
- Next, iterate over the tracks to collect the artistId.
- After that, make a batch request to the artists microservice to collect all the artists from the list.
- Finally, map each requested artist back to its corresponding track.
Although it seems simple and manageable with just a few lines of JS, it can quickly become complex. This is because the track entity may contain other entities besides the artist, and the artist entity may also contain sub-entities such as bands.
The n+1 problem
The N + 1 problem arises when an application retrieves data from a database and iterates over the results, resulting in repeated database queries. Specifically, the application will issue N additional database calls for every row returned by the initial query, in addition to the original query (+1).
It may seem familiar to what we just discussed, right? If you replace the database with microservices, that's essentially it.
The solutions we experimented with
Our use-cases often require us to load a list of items, and then make additional requests to fetch more data to display information related to each individual item. It can quickly become complex if we need to go several levels deep to retrieve all the necessary information.
Batch endpoints as first solution
Initially, we relied on frontend calls to batch endpoints to display data from multiple sources. However, we soon discovered that this approach had limitations, particularly in terms of performance due to the n+1 problem. Additionally, making multiple requests to the backend in frontend can be costly and not very user-friendly, particularly when waiting for data to load. This led us to explore more efficient data aggregation methods.
We identified two possible methods for implementing data aggregation in the frontend:
Transforming the received data and adding the related entities
const aggregatedCards: Card[] = cards.map(card => {
const draftPayload = card.draft.payload
const publishedPayload = card.published.payload
const updatedDraft: DraftCard = set(
'payload.cardType',
cardTypesMap[draftPayload.cardTypeId]
card.draft
)
const updatedPublished: PublishedCard = set(
'payload.cardType',
cardTypesMap[publishedPayload.cardTypeId]
card.published
)
return {
draft: updatedDraft,
published: updatedPublished,
}
})
Pros:
- The related entity is directly injected into its parent, making it easily accessible.
Cons:
- Transformation logic needs to be implemented, adding complexity to the code.
- Predefined types (Our case involves auto-generated types based on our backend's OpenAPI specification) must be extended to accommodate the new entities, which can be cumbersome.
Dealing with code transformation logics can be even more challenging if the parent entity is part of a union. Here's an example of code we used in one of our experiments:
type AggregatedCardA = CardA & {
cardType: CardType
}
type AggregatedCardB = CardB & {
cardType: CardType
}
type AggregatedCard = AggregatedCardA | AggregatedCardB
export interface CardData {
metadata: SimpleMetadata
payload: AggregatedCard
}
export interface Card {
draft: CardData
published: CardData
}
We had to redefine all the types because of the necessary data transformation to aggregate cardType into CardA and CardB within that union.
Relationship maps as alternative
We also explored an alternative approach where instead of transforming the data, we provided a relationship map to send down the React tree. When we needed to use a relationship, we could simply pick it from the map. Here's an example of the code we used for this approach:
export const aggregateData = async () => {
const data = await getCards()
const cards = data?.cards ?? []
const cardTypesIds = cards
.map(card => {
const { payload } = card.draft
return payload.cardTypeId
})
.filter((item): item is string => !!item)
const cardTypes = await findBatchedCardTypes(cardTypesIds)
const cardTypesMap = keyBy(cardTypes, 'id')
return { cardTypesMap, cards }
}
Drawbacks of this approach:
- It can be challenging to memoize the cardTypesMap when passing it down to card items components, depending on the specific use-case.
- The approach relies on prop drilling the cardTypesMap.
Note: We considered implementing these features on a raw node BFF server to reduce loading times and eliminate the need for multiple backend calls. However, we realized that we would still face the same issues with types and data transformation.
Following discussions with individuals outside our organization, we decided to experiment with GraphQL as a potential solution.
The findings when experimenting with GraphQL
In short, we chose not to pursue GraphQL due to some limitations with union types and a lack of support for maps. This is further detailed in this link: limitations.
We are aware that we could use aliases as a workaround, but that would mean the data structure would differ from what our types are expecting, and we would face the same issue of having to extend our types.
Anyway, we came across two amazing tools that are useful in situations where a BFF is necessary:
- graphql-mesh is a tool that allows you to integrate backend microservices (whether they are REST with OpenAPI specs, GraphQL, etc.) into a single GraphQL Gateway. It's easy to set up as it generates schemas, queries, and mutations based on the provided specifications. You only need to implement additional properties for data aggregation
The main setup for us consisted of three files:
.meshrc.yml
sources:
- name: Card
handler:
openapi:
endpoint: https://cp.com/card
source: card.json
operationHeaders:
Authorization: "{context.headers['authorization']}"
- name: CardTypes
handler:
openapi:
endpoint: https://cp.com/card-type
source: card-type.json
operationHeaders:
Authorization: "{context.headers['authorization']}"
additionalTypeDefs:
- ./typeDefs/card.graphql
additionalResolvers:
- ./resolvers/card
./typeDefs/card.graphql
extend type Card {
cardType: CardType
}
./resolvers/card
import { print, SelectionSetNode } from 'graphql'
import keyBy from 'lodash/keyBy'
import { Maybe, CardType, Resolvers } from '../.mesh'
const resolvers: Resolvers = {
Card: {
cardType: {
selectionSet: `
{
cardTypeId
}
`,
resolve(root, _args, context, info) {
return context.CardTypes.Query.find_card_types({
root,
key: root.cardTypeId,
argsFromKeys: ids => {
return {
id: ids,
}
},
valuesFromResults: (data?: Maybe<Array<Maybe<CardType>>>, keys?: string[]) => {
const map = keyBy(data, 'cardTypeId')
return keys?.map(key => map[key]) || null
},
selectionSet(selectionSet: SelectionSetNode) {
return print(selectionSet)
},
context,
info,
})
},
},
},
}
export default resolvers
- Another tool we discovered was wundergraph, which we didn't have the chance to fully explore. However, based on our initial research, it appears to be similar to graphql-mesh but more powerful, using JSON-RPC instead of GraphQL.
Mixed approach: Lazy-loading with dataloader
What if, instead of loading all the necessary data at the list-level, we loaded it at the item-level as needed? This would eliminate the need for data transformation or changing types, and there would be no prop drilling. Instead, we would load the data for each individual item when it is needed and use it directly where it is needed. Additionally, we could display a placeholder or blurred version of the component while the data is loading:
const { data: cardType, isLoading } = useCardType(card.cardTypeId, {
enabled: Boolean(card.cardTypeId),
})
// if its loading, render blur version, if its not, render cardType info
The downside of the item-level loading approach is that it requires each item to make its own request, which can lead to a high volume of requests to the backend as the number of items increases. However, after researching potential solutions, we found that GraphQL's dataloader tool could help us address this issue through its batching feature.
For those who are unfamiliar with the dataloader batching feature, it groups together requests that occur in the same event loop tick and calls the provided loader to make a single request instead of multiple. Once it receives the results, it automatically maps the response back to each individual call. This feature essentially solves the main issue with the lazy-loading strategy.
Implementing a react-query + dataloader hook is a simple process. Here's how we did it:
type Key = { id: string; }
const cardTypesLoader = new Dataloader<Key, CardType>(
async keys => {
const resultMap = await CardTypesApi.findCardTypes({
id: keys.map(key => key.id),
})
return keys.map(key => resultMap[key.id])
},
{
cache: false, // <-- IMPORTANT, dataloader doesn't have the same cache management as react-query
}
)
export const useCardType = (id: string, options?: { enabled?: boolean }) => {
return useQuery(
['card-type', id],
() => {
return cardTypesLoader.load({ id })
},
options
)
}
How does it solve the problem of data aggregation?
First, let's address the question: Why is data aggregation necessary?
- We want to have a fast way to request all the sub-entities so users can see/interact with our items as soon as possible. We want to reduce user idle time.
- We want to map all the requested sub-entities to their respective parent. So in our case, we want to aggregate the card type into the card because we want to use it in the card component.
How does lazy loading with data-loader address these issues?
- With lazy-loading, we can display list items to the user without waiting for the additional information related to other microservices to load. This approach allows users to see and interact with cards sooner than any other approach, including BFF, and results in the least amount of idle time.
- By using dataloader, we can use react-query in each item of our list to request the sub-entity we want to use in that item. This eliminates the need to map sub-entities to entities since the place we request them is the place where we use them. We don't need to change types or data structures in any way.
Extra points for lazy-loading
- Since we will be utilizing batch endpoints and not aggregating data, the final JSON payload exchanged between the backend and frontend is reduced. This is because duplicates can be removed when sending the request to the dataloader if two cards have the same card type.
- By using react-query to retrieve sub-entities in a pagination scenario, already-resolved entities in page 1 will not be re-requested in page 2.
- This is also true when using a virtualization library. Sub-entities are only loaded for what's on the user's screen, and when the user scrolls down, react-query cache is utilized to prevent reloading what's already been requested.
But hey, wont we have too many rerenders?
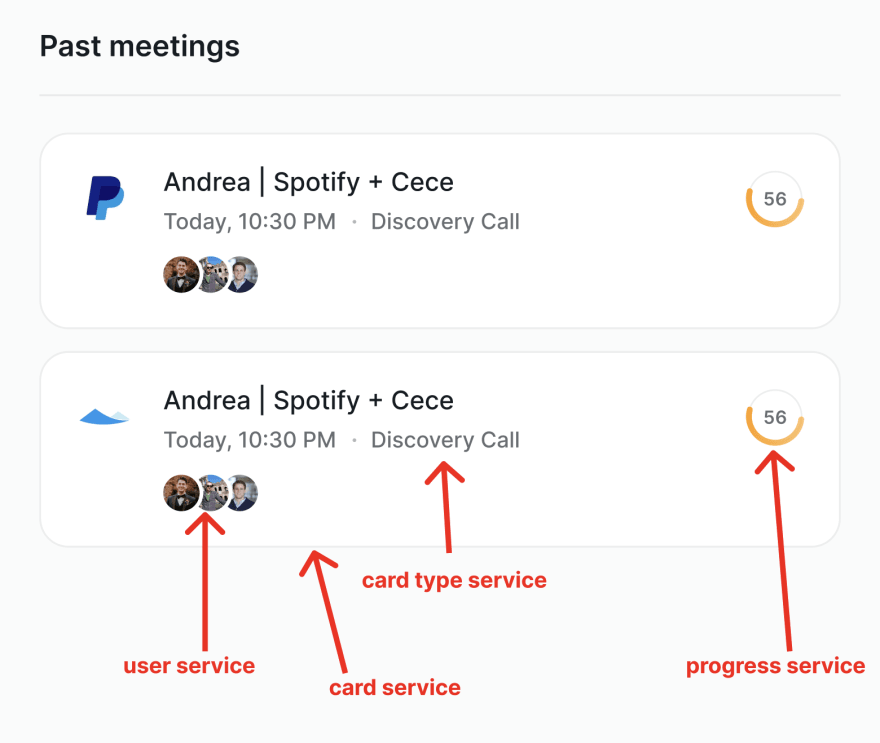
Using dataloader actually groups all sub-entity requests for a given entity, resulting in simultaneous resolution of requests and minimizing rerenders, even in scenarios with a high number of items on a page. For example, in the team card card, 3 sub-entity requests are required (card-type, user, and progress), which means that regardless of the number of cards on the screen, only 3 (visible) rerenders will occur.
Additionally, incorporating smooth CSS transitions between the loading state and actual state can enhance the user experience even further.
Note that if the 3 rerenders in your list are causing performance issues, it may be more effective to address these issues through virtualization rather than attempting to reduce the number of rerenders.
Hydration as a opt-in performance improvement
This approach allows you to take advantage of react-query hydration for data prefetching, even without utilizing SSR. By creating a node endpoint that fetches your queries and returns a dehydrated state to the frontend, you can benefit from partial hydration. This enables you to prefetch essential queries while leaving the frontend to lazy-load the rest. Consequently, you achieve performance comparable to the BFF approach, without the need to manage aggregation logic.
It also has a built-in fail-safe: if the prefetch endpoint is down, the frontend will resort to directly requesting data. This ensures that your application remains functional even in the face of potential issues.
A downside is the necessity of introducing prefetching logic to the BFF, though it's notably less code than aggregation.
There is no silver bullet
- In instances where the n+1 problem occurs or when optimizing performance is essential, implementing the prefetching strategy is not optional.
- If you find yourself in a scenario where you need to handle data from several interdependent sources and your processing logic requires data from both sources prior to displaying it to the user, then this alternative is likely unsuitable.
In the end, which approach did we take at Chili Piper?
General consensus claims that the lazy-loading and dataloader method is a more elegant solution and it is commonly adopted in various scenarios. In a particular case, we use BFF due to the need to process the data before presenting it to the user.
As a bonus, here's how lazy-loading looks like in one of our pages:
This content originally appeared on DEV Community and was authored by Lucas Correia
Lucas Correia | Sciencx (2023-03-22T12:01:16+00:00) Uncovering Frontend Data Aggregation: Our Encounter with BFF, GraphQL, and Hydration. Retrieved from https://www.scien.cx/2023/03/22/uncovering-frontend-data-aggregation-our-encounter-with-bff-graphql-and-hydration/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.