
This content originally appeared on Level Up Coding - Medium and was authored by Rabi Siddique

Creating a website or an online platform is one thing, but making it handle multiple users without any performance issues or downtime is another. As your user base grows, the traditional architecture of a single server communicating with a database becomes insufficient. This is where scalability and fault tolerance comes into play.
Initial Setup
Let’s dive into the figure below and explore the process of designing a basic app with multiple users. Initially, the easiest approach is to deploy the entire app on a single server, which is typically how most of us begin. This entails running a website with some APIs on a web server and a database.
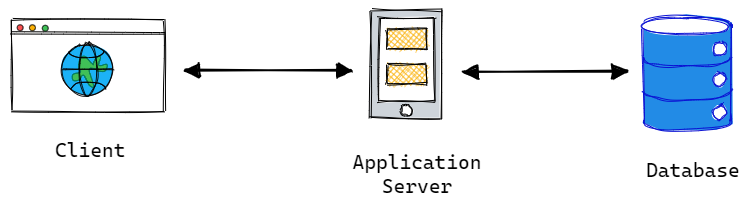
Deploying the entire app on a single server may seem easy, but it can cause problems as more people start using it. Here are some reasons why:
- As your website gains popularity, user traffic can cause delays in response times, leading to a less-than-ideal user experience.
- Furthermore, relying on a single application server or database server can create a single point of failure, where if either server fails, your entire application will stop working.
This highlights the importance of implementing a system that is scalable and fault tolerant. A system that ensures that the application remains resilient and available, even during high-traffic periods or unexpected failures.
What are Scalability and Fault Tolerance?
Scalability refers to the ability of a system to handle an increasing amount of work by adding resources. In contrast, fault tolerance refers to the ability of a system to continue functioning even in the face of failures or errors. These two concepts go hand in hand, as a scalable system must also be fault-tolerant to avoid downtime in case of failures.
Vertical Scaling vs Horizontal Scaling
When scaling your application, you have two options: vertical and horizontal.
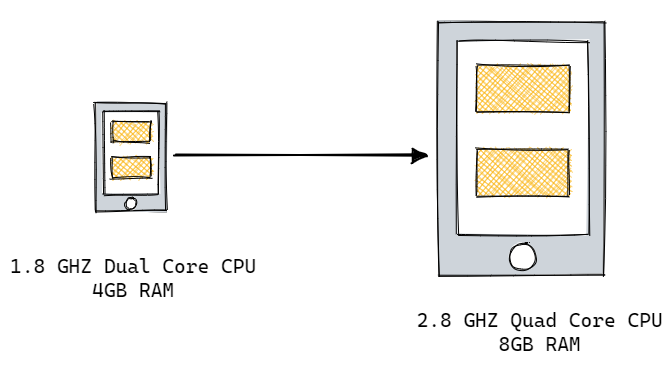
Vertical scaling involves adding more power such as RAM or CPU power to your existing server or replacing it with a more powerful one. While this can provide an immediate solution, it can only take you far. Eventually, you’ll hit a limit on how much you can vertically scale your server, and you’ll need to find another way to handle the increasing traffic.
That’s where horizontal scaling comes in. This technique involves adding more servers to your infrastructure hosting the same application. This provides redundancy and ensures uninterrupted service even if one server goes down.
Horizontal scaling offers a much more scalable and fault-tolerant solution than vertical scaling, allowing you to handle increasing traffic and user demands without experiencing performance issues or downtime.
Load Balancers

When scaling your application, adding more servers is a great way to handle increased traffic and user demands. But with multiple servers comes another issue: how do you effectively distribute traffic between them? This is where load balancers come in.
Load balancers act as traffic cops, directing incoming requests from clients to different servers. They do this by examining various factors such as the type of request, the current load on each server, and the proximity of the client to each server. This ensures that no single server is overwhelmed with traffic and that each server is utilized efficiently.
Our website’s IP address is now exclusively used for communication with the load balancer. As a result, our servers are accessible only on the private network, which enhances our security measures. This setup limits the number of publicly accessible components and consequently reduces the potential resources that could be targeted by malicious attacks.
Load balancers have evolved over time and have become crucial gatekeepers for the servers they oversee. They provide an additional layer of defence against DDoS attacks by automatically redirecting suspicious requests, preventing them from reaching the servers.
In addition to distributing traffic, load balancers also play a critical role in ensuring high availability and fault tolerance for an application. They monitor the health of each server in the pool and can automatically route traffic to healthy servers in the event of a failure or outage. This helps to minimize downtime and ensure that users can continue to access the application even if one or more servers go down.
Load balancers can be implemented in hardware or software. Hardware load balancers are typically faster and more powerful but are also more expensive and difficult to maintain. They are often used in large enterprise environments that require high levels of performance and scalability. Software load balancers, on the other hand, are typically less expensive and easier to maintain, but they may need help to handle as much traffic.
Stateful vs Stateless Architecture
Regarding application architecture, there are two main approaches: stateless and stateful. Stateless architecture treats each user request as an independent transaction without the knowledge of previous interactions. This means that each request contains all the necessary information for the server to process the request without needing any additional context from previous requests.
On the other hand, stateful architecture maintains a record of user data and interactions across multiple requests. This means that each request builds on the previous request, and the server needs to maintain some form of context or state to process the request correctly. Stateful architecture is often used in applications where users need to log in and keep a session, such as online shopping sites or social media platforms.
But what happens when you have multiple servers in a stateful architecture? Suppose user sessions are being stored on individual servers. In this scenario, if a load balancer directs a user to a different server for their next request, their session data will be lost. This can lead to users having to log in again, which can be frustrating and time-consuming.
While stateful architecture can have its benefits, it also comes with several downsides. When data is stored across multiple servers, maintaining consistency and keeping track of changes can become difficult. This can lead to increased server loads and decreased performance, ultimately limiting the scalability of the application.
To address these challenges, it is recommended that developers use stateless architecture whenever possible. However, if stateful architecture is necessary, there are solutions that can help improve scalability and consistency. One of these solutions is decoupling the data from individual servers to a shared storage location.
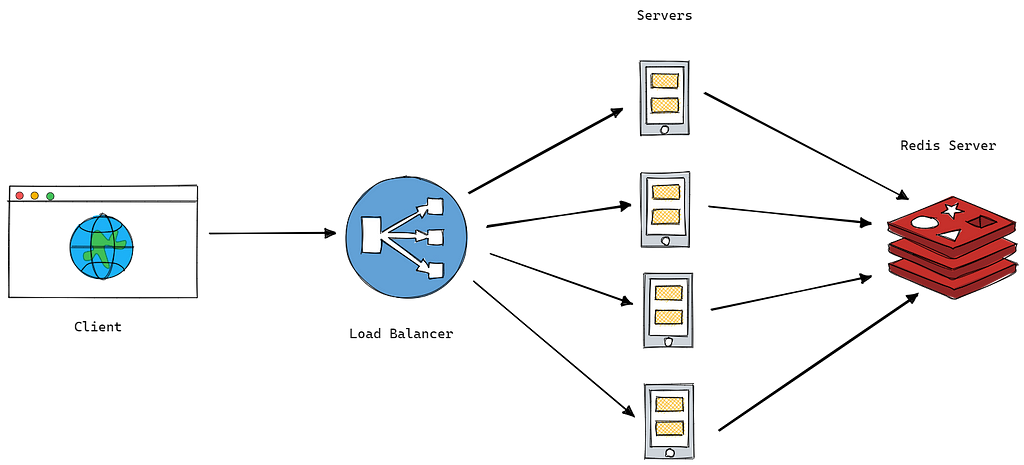
For example, a Redis server can be used to store user sessions and other data, ensuring that all servers have access to the same information regardless of which server a user is directed to. Additionally, any other data stored on individual servers should be decoupled to a shared storage location to ensure consistency across all servers.
Caching
The application usually queries a database when a user requests a page or moves to another page by clicking a link. While querying a database for a small application with only a few hundred or thousand users might not impact performance significantly, serving over a million users can be challenging. Using a cache can significantly boost the application’s performance in such a case.
When a user logs in, the web app typically retrieves user data from the database by running a query at each request. In such a scenario, the system first attempts to get the user data from the cache. If the cache contains the user data, then there is no need to query the database. However, if the user data is absent in the cache, the web app queries the database to retrieve it and stores it in the cache for subsequent requests. Here’s some pseudocode to illustrate the process:
user = getUserFromCache(userId);
if (user == Null) {
user = getUserFromDb(userId);
setUserInCache(user);
}
Content Delivery Networks (CDNs)
Content Delivery Networks (CDNs) are networks of servers that are spread out across different locations. When a user connects to a website, the server closest to them is selected, which reduces the amount of time it takes to load the page. Initially, CDNs were only used to deliver static resources, like images, CSS, and javascript. However, newer and more advanced CDNs can now also deliver dynamic content that is unique to the user and not cacheable.
With a basic CDN, the website is still served through your load balancer, but all the static resources are served from CDNs. In the past, if a file was updated, it had to be manually pushed to the CDN. But now, “origin pulling” automatically refreshes files. When a user requests a resource, the CDN checks its cache. If the resource is outdated or not present, it fetches the updated version from the original website.
Using a CDN can help you cache certain pages or content, which will remain live even if your own servers are down. Some CDNs also specialize in security and can detect and block DDoS attacks and other types of malicious traffic.
Database Replication
Currently, our database server has not been scaled, which means that it is a single point of failure. This poses a significant problem as the entire system would cease to function if the database server crashes, even if one of the application servers is still operational.
To address this issue, the first step is to set up Read Replicas for the database server. This involves creating one or more copies of the database and designating one as the “Leader” while the others are labelled as “replicas.” Write actions, such as Create, Update, and Delete, will be performed solely on the leader database, while read actions will be distributed across the replica databases. After each write operation, the data will be synchronized across all slave servers.
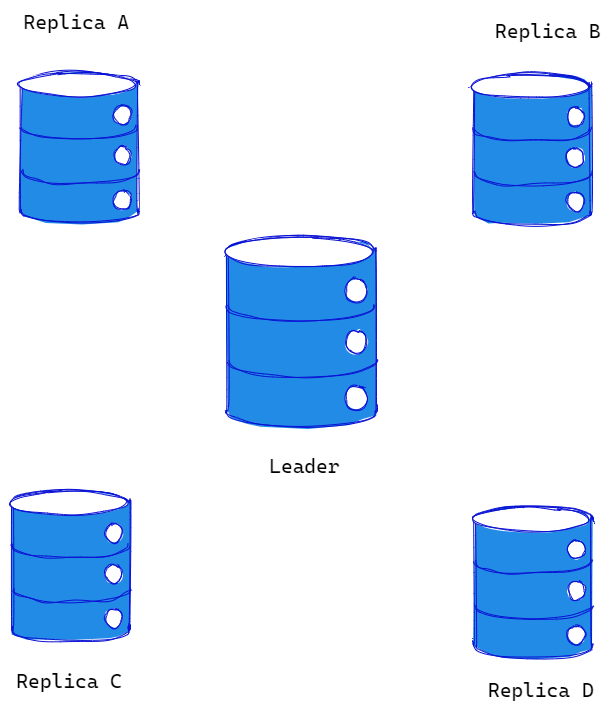
The Read Replica approach offers several key benefits:
- It allows you to handle more requests, thus improving system performance.
- Data processing activities, such as backups, analytics, and reporting, can be safely carried out on one of the replicas without affecting system performance.
- If any of the servers go offline, they can be easily replaced. If the leader server goes down, one of the replica databases can be promoted to leader. Meanwhile, if a replica server crashes, it is usually straightforward to create a new one.
By implementing this approach, we can mitigate the risk of a single point of failure and ensure that our system remains operational even if one or more servers experience downtime. This architecture is highly beneficial for websites like Medium, which have more read requests than write, edit, or delete requests. In such cases, the read requests could be balanced among the read replicas, while all the other requests would be sent to the leader database.
Sharding the Database
Lastly, as your database grows, sharding can help improve efficiency by splitting queries between multiple databases based on a certain metric.
Sharding is a database scaling technique that distributes data across multiple servers to improve performance and reduce the load on a single database server. Simply, it means breaking up a large database into smaller, more manageable chunks called “shards.” Each shard contains a subset of the overall data, and queries are directed to the appropriate shard based on a predefined metric, such as geographic location, customer ID, or alphabetical order.
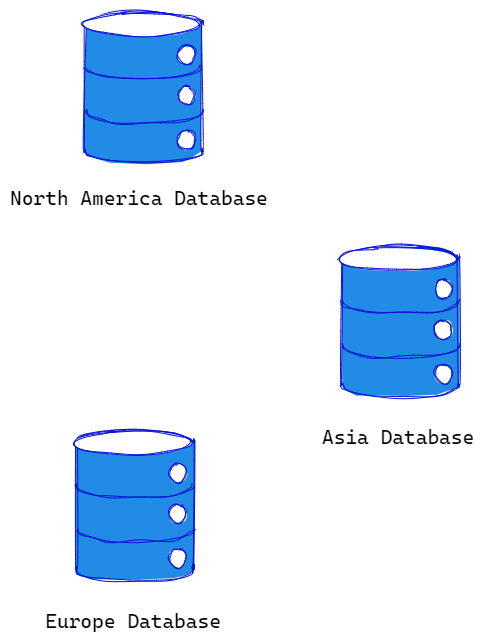
For example, you shard your customer database into three shards based on geographic location: North America, Europe, and Asia. Each shard would contain all the customer data for their respective region, and any queries for customer information would be directed to the appropriate shard based on the customer’s location. This would significantly reduce the data each server has to handle, resulting in faster response times and a better user experience.
Thank you for reading. I hope this post is helpful to you. If you have any further questions, don’t hesitate to reach out. I’m always happy to help.
References
- How to design a system to scale to your first 100 million users
- Scale your system Part 1: From 1 to 10 000 users
- Scale your system Part 2: From 100 000 to 100 000 000 users
- System Design: Building & Scaling to 100 Million Users
- ByteByteGo | Technical Interview Prep
- Introduction to architecting systems for scale.
- Scaling Your Web Application
Level Up Coding
Thanks for being a part of our community! Before you go:
- 👏 Clap for the story and follow the author 👉
- 📰 View more content in the Level Up Coding publication
- 💰 Free coding interview course ⇒ View Course
- 🔔 Follow us: Twitter | LinkedIn | Newsletter
🚀👉 Join the Level Up talent collective and find an amazing job
Architecting a Scalable and Fault-Tolerant System for a Million Users was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Rabi Siddique
Rabi Siddique | Sciencx (2023-03-28T19:17:10+00:00) Architecting a Scalable and Fault-Tolerant System for a Million Users. Retrieved from https://www.scien.cx/2023/03/28/architecting-a-scalable-and-fault-tolerant-system-for-a-million-users/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.