
This content originally appeared on DEV Community and was authored by Aallzz
DSU is one of the most elegant in implementation data structure and I've used in my competitive programming life for many many time. Internet is full of various implementations for it, but unfortunately there are almost no article with a good proof of DSU efficiency, in this article I will do by best to uncover this secret.
Trivial Disjoint Set Union data structure can be implemented in a following way
class DSU
{
private int[] parent;
void createSet(int vertex)
{
parent[vertex] = vertex;
}
bool isRepresentative(int vertex)
{
return parent[vertex] == vertex;
}
void findRepresentative(int vertex)
{
if (!isRepresentative(vertex))
{
return findRepresentative(parent[vertex]);
}
return vertex;
}
void mergeSets(int lhs, int rhs)
{
int rhsRepresentative = findRepresentative(rhs);
int lhsRepresentative = findRepresentative(lhs);
if (lhsRepresentative != rhsRepresentative)
{
parent[lhsRepresentative] = rhsRepresentative;
}
}
}
Let's start with two trivial heuristic DSU has
Tree depth rank heuristic
The following heuristic suggests that we should attach a set-tree with smaller depth to a set-tree with larger depth.
void createSet(int vertex)
{
parent[vertex] = vertex;
rank[vertex] = 1;
}
void mergeSets(int lhs, int rhs)
{
int rhsRepresentative = findRepresentative(rhs);
int lhsRepresentative = findRepresentative(lhs);
if (rhsRepresentative != lhsRepresentative)
{
if (rank[lhsRepresentative] < rank[rhsRepresentative])
{
swap(lhsRepresentative, rhsRepresentative);
}
parent[rhsRepresentative] = lhsRepresentative;
if (depth[lhsRepresentative] == depth[rhsRepresentative])
{
rank[lhsRepresentative] += 1;
}
}
}
Let's show that this heuristic will help to reduce the findRepresentative complexity to O(log(N)).
We can do this by proving that if set-tree rank is equal to K, then this tree contains at least 2^K vertices and has depth K. We will use induction on K.
If K = 1, then size of the tree is 1 and the depth is 1.
Let's understand how we get a set-tree with rank equal K. It happens if we merge two set-trees of the same K-1 ranks. But we know that for set-trees with K-1 rank we have depth K-1, it means that a new set-tree for rank K is going to contains at least 2 * 2^(K - 1) = 2^K vertices and have a depth of at most K.
Tree size rank heuristic
Similar heuristic, but it suggests to attach a smaller set-tree to a larger one.
void createSet(int vertex)
{
parent[vertex] = vertex;
size[vertex] = 1;
}
void mergeSets(int lhs, int rhs)
{
int rhsRepresentative = findRepresentative(rhs);
int lhsRepresentative = findRepresentative(lhs);
if (rhsRepresentative != lhsRepresentative)
{
if (size[lhsRepresentative] < size[rhsRepresentative])
{
swap(lhsRepresentative, rhsRepresentative);
}
parent[rhsRepresentative] = lhsRepresentative;
size[lhsRepresentative] += size[rhsRepresentative];
}
}
In a similar way we can prove that if size of set-tree is K, then its height is log(K).
If K = 1, that's obviously true.

Let's look at two trees Tree_k1 of size k1 and Tree_k2 of size k2. We can tell that Tree_k1 has height log(k1) and Tree_k2 has height log(k2).
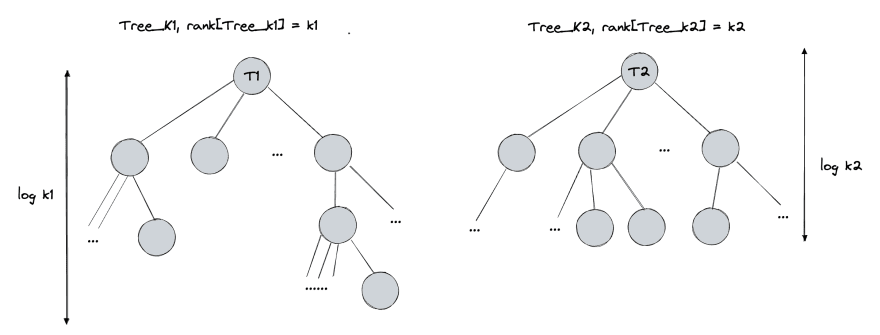
Let's say that k1 >= k2, then Tree_k2 will be attached to Tree_k1 and the new height of the tree will be max(log(k1), log(k2) + 1).

It's very easy to show now that new height h is smaller than log(k1 + k2).
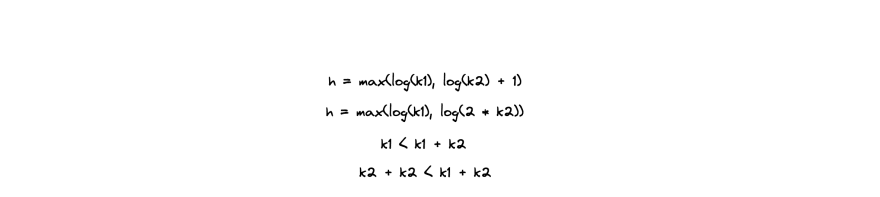
Now let's take a look at a little more interesting heuristic
Tree path compression heuristic
Let's consider the following optimisation of findRepresentative function
public int findRepresentative(int vertex)
{
if (!isRepresentative(vertex))
{
parent[vertex] = findRepresentative(
parent[vertex]
);
}
return parent[vertex];
}
In this code we're removing all edges on a path from vertex to the root (representative) of the set-tree connecting vertices on the path to the root.
First observation, that this alone can still produce a tree of depth O(N). For this we always connect root of a set-tree to an set-tree of one vertex.
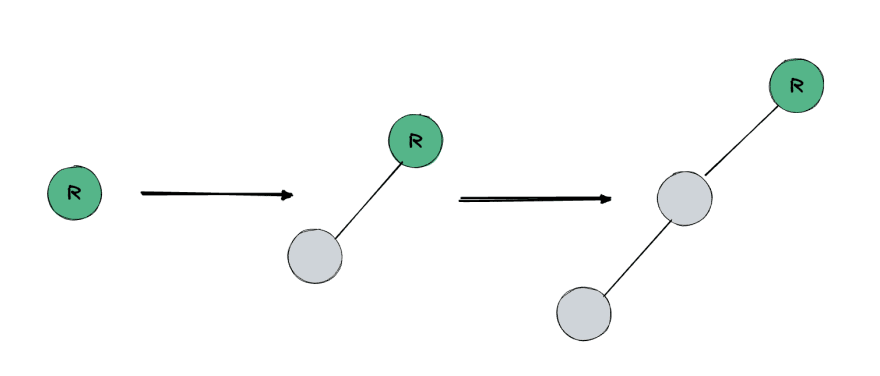
In the image above findRepresentative is always called for set-tree root, so the complexity of this call is O(1).
Let's consider a case where findRepresentative is called from non set-tree root and understand why it will have O(log N) complexity in average. To do so lets start with introducing a category for the edges in the set-tree.
Edge (a, b) where a is a parent of b has category 2^K if 2^K <= size(a) - size(b) < 2^(K + 1).
Let's look at the path that will be removed when calling findRepresentative(x) (marked with yellow)
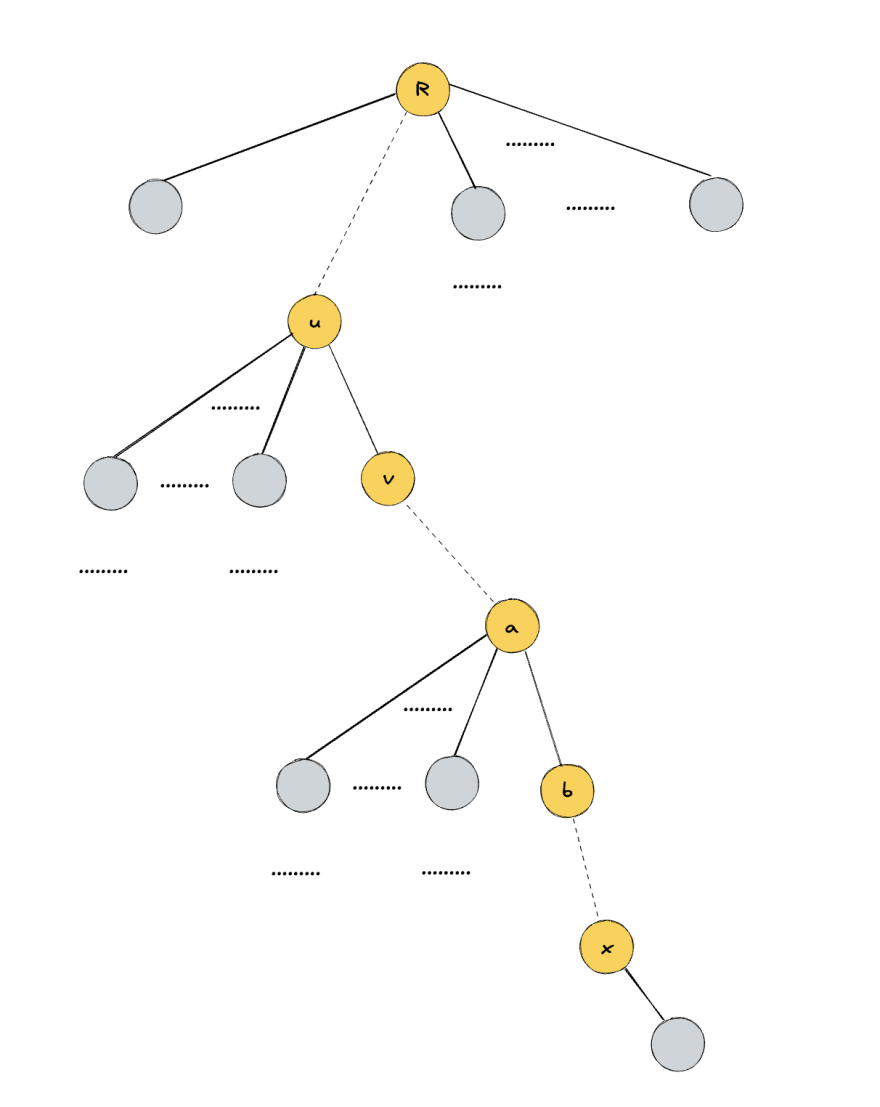
If this path has log(N) edges, we're happy with that as we want to prove O(log N) complexity.
Let's say there are more than log(N) edges. In this case we will find at least two edges with the same category K (
Pigeonhole principle)
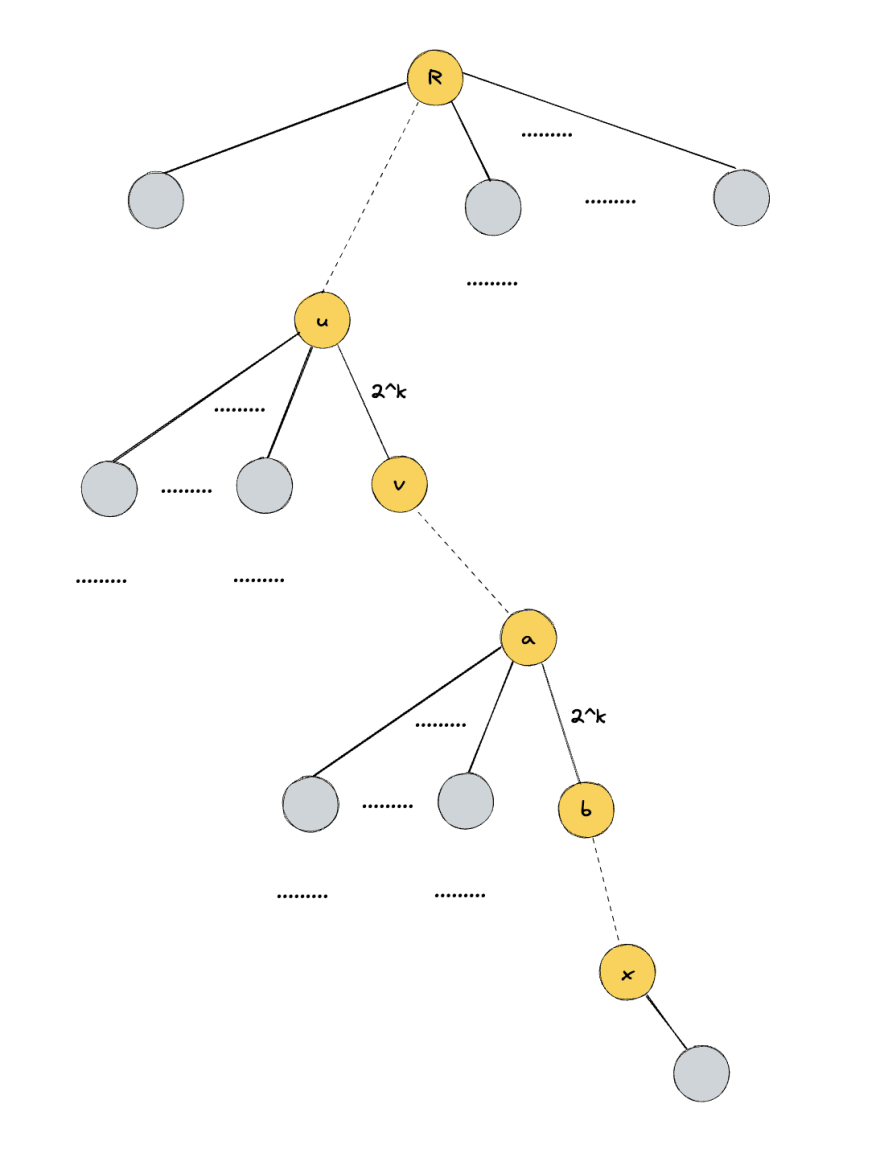
Let's define size(a / b) as size of sub-tree a without sub-tree of b.
We can easily see that size(u / v) >= 2^K + size(v) and size(a / b) >= 2^K + size(b). But we can say even more! v contains in its sub-tree at least size(a / b) vertices, this means that size(u / v) >= size(a / b) + 2^K >= size(b) + 2^K + 2^K.

Let's look more closely in the first edge of category 2^K on the path. With the observation above we can understand what will be the category of edge (R, v) that we add instead of (u, v) as part of path compression. Size of R sub-tree is at least size(u / v) + size(v) which is more than 2^(K + 1) + size(v) and the size of v is size(v), so size(R / v) >= 2^(K + 1). This means that if there are more then log(N) edges on a path from representative (R) to the vertex x, then there will be at least on edge with increase category. The category is limited by the size of the tree so it cannot grow indefinitely.

Let's show that when we're replacing an edge on the path with an edge to the root, category of that edge can't decrease. Let's say that we're replacing edge (u, v) with edge (R, v). Because R is an ancestor of u it will have at least one more vertex in its sub-tree thus size(u, v) < size(R, v) + 1.
All other edges won't change their category, because the edge replacement either doesn't affect them or size of both vertices of that edges are decreased by the same number.
So knowing that category of edges is only growing and has a limit we can say that it won't be more than (N - 1) * log(N) (every edge in set-tree of size N can increase its category at most log(N)). Combining with a scenario when path from a vertex to representative is less or equal to log(N) we got total complexity for M operations findRepresentative O((M + N)log(N)).
Combination of path compression with rank heuristic
The proof for this is rather complex, but I believe it worth mentioning that complexity of this heuristic speeds up the algorithm to O(ackermann(n)), where ackermann is reversed Ackermann function that growth extremely slow (for example for n <= 10^500, ackermann(n) < 4).
Summary
In this article we took a look at a fascinating data structure DSU and we proved the most common heuristics used in it and mentioned one extremely efficient heuristic that combines two of them.
This content originally appeared on DEV Community and was authored by Aallzz
Aallzz | Sciencx (2023-04-01T23:56:49+00:00) Disjoint Set Union heuristics. Retrieved from https://www.scien.cx/2023/04/01/disjoint-set-union-heuristics/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.