
This content originally appeared on Level Up Coding - Medium and was authored by Zack
Introducing one of the most popular indexing techniques: hash-based indexing, explaining its different types and their structure.

Suppose we have a database that contains huge amount of data, and now we need to retrieve some of the data from it, how does DBMS find out those data and send them to us? An easy way is to search all the index values and reach the desired data. But since this database is too big, it will be inefficient to find data through this index structure. Hashing is one of the techniques to solve this problem, with the help of hashing, we can retrieve data faster and easier.
What is Hash-based Indexing
The hash-based indexing are using a technique called hashing to quickly find values that match the given search key value. For example, if the files of student records are hashed on name, then we can get all student information based on the name that we provided.
In this structure, we have several buckets; all the data in a file are grouped in buckets, and the buckets and search keys are linked through the hash function. The first bucket consists of the primary page and additional pages linked in a chain. Given a bucket number, a hash-based index structure allows us to retrieve the primary page for the bucket in one or two disk l/Os.
The image below illustrates this approach. The data in buckets is hashed on age, and the hash function will first convert the age to its binary representation, then group each data to different buckets based on the last two bits of the binary representation.
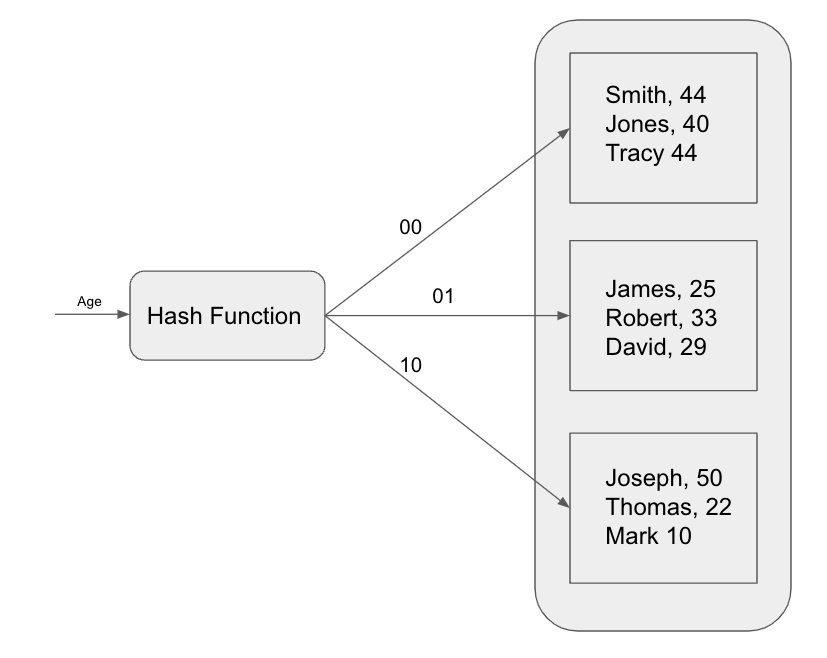
Hash-based indexing can be classified into two types: static hashing and dynamic hashing, based on whether the index structure can be extended. Let’s discuss each of these types in detail.
Static hashing
This is the simplest hash-indexing technique, same as what I said before, it contains several buckets, and each bucket consists of primary bucket pages, and additional space, the additional space is the overflow page added after the primary bucket, one key was linked to one bucket and was connected through a hash function. The reason it is called static is the number of buckets in this structure is fixed, we cannot add or delete buckets in this hash map.
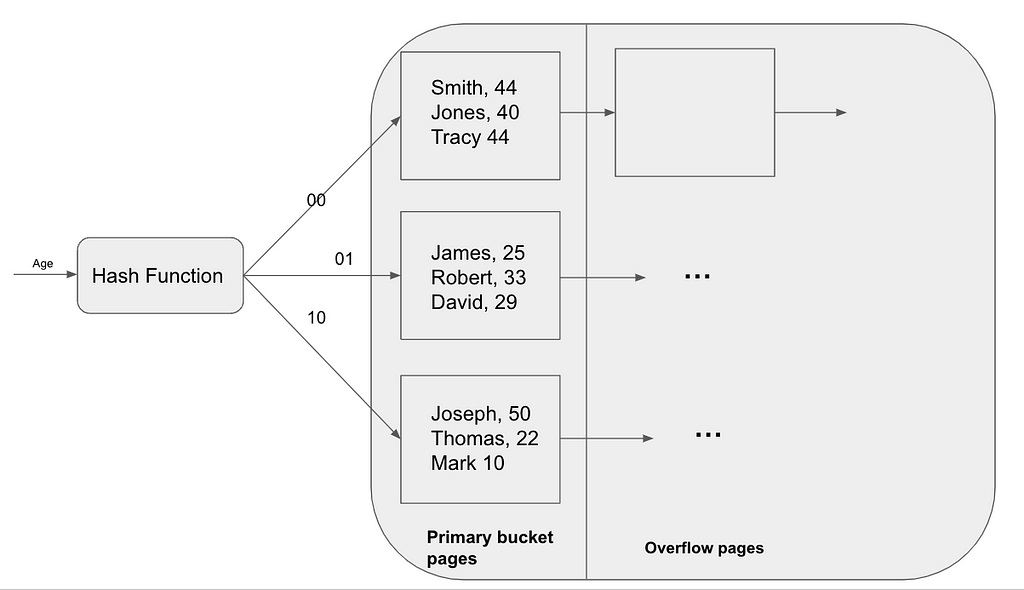
When inserting a data item in static hashing, we use a hash function to identify the appropriate bucket and append the data to it. If the bucket is already full, we allocate a new overflow page and store the data there. Similarly, when deleting a data item, we use the hash function to locate the corresponding bucket. If the data entry is the only one in an overflow page, we can simply remove that page.
This data structure can be pretty effective since the insert and delete operations only need two I/Os (read and write), but its disadvantage is also pretty obvious. As the file grows, the overflow page chains can be pretty long which might cost lots of time while searching in the chain. Since the number of buckets is fixed, when one of the files shrinks greatly, a lot of empty buckets will waste tons of space.
The alternative is to use dynamic hashing techniques which are what we are going to talk about: extendible and linear hashing.
Dynamic hashing
Extendible hashing
As the name shows, not like static hashing, extendible hashing can increase the number of buckets. To tell the program when should it increase buckets and how many buckets it should increase, we have to use a special hash function.
Compare to the original static indexing structure, the extendible hashing added a directory of pointers to buckets, so the whole process changes to using the hash function to find the correct pointer in the directory, through that pointer find the correct page that we want to search. Whenever we need to increase the number of buckets, we can double the size of the directory first and split only the bucket that overflowed.
There is a simple example for illustration:
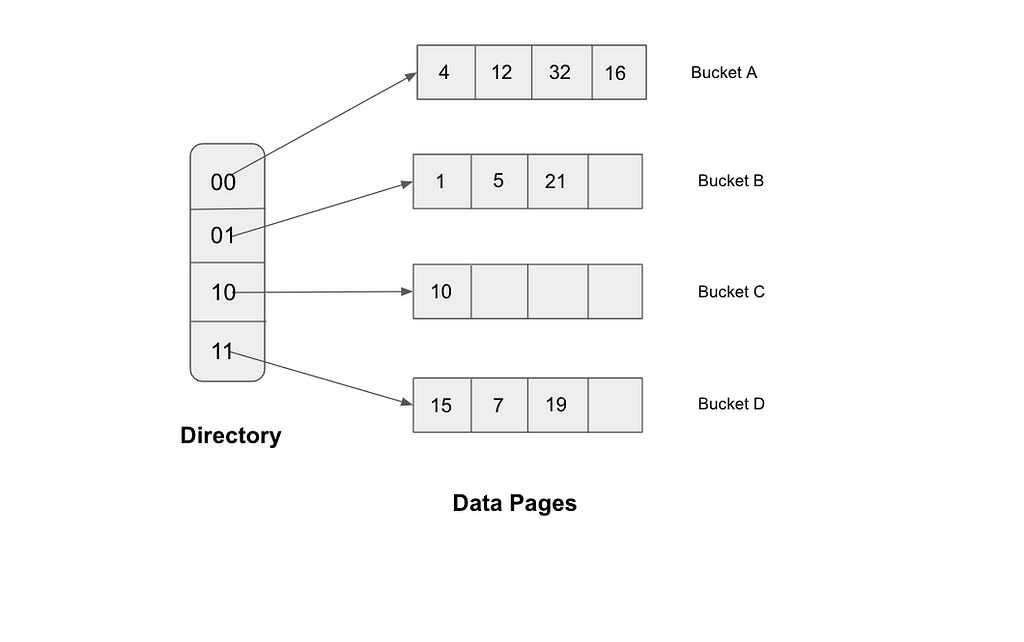
There has a directory that consists of an array of size 4, and each position has a pointer point to a bucket, so in this example, there are totally four buckets. For each bucket, we assume that each bucket can hold four data items. And for the hash function, we assume that it will take the last 2 bits of the data items’ binary representation, it will find the pointer based on that 2 bits, and use the pointer to locate the correct bucket. For example the binary representation of 4 is 100, and the last two bits are 00, so 4 should go to the bucket to which the 00 pointer pointed.
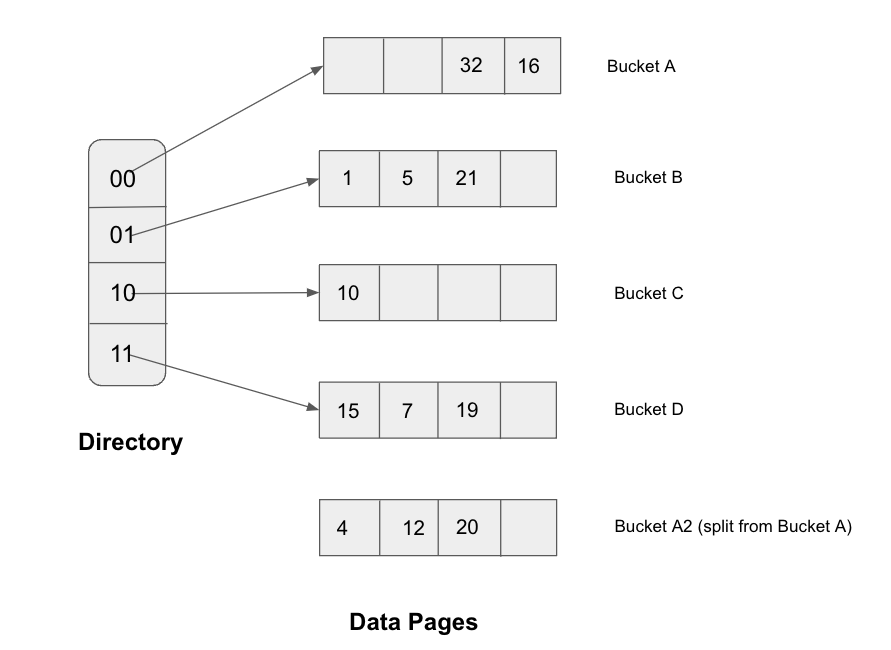
If we want to insert one value into bucket C, that’s fine, because bucket C still has space for extra data, but what if we want to insert 20 into the bucket? Based on the hash function, the binary representation of 20 is 10100, it should go to bucket A, but bucket A is already full. Thus we should split A into A1 and A2. After we split bucket A, there will not have enough pointers in the directory, thus we should also double the size of the directory. So now, we need three bits to discriminate between the pages that we have. Since the size of the directory is way smaller than buckets, so the cost of doubling it is more acceptable than doubling the pages.
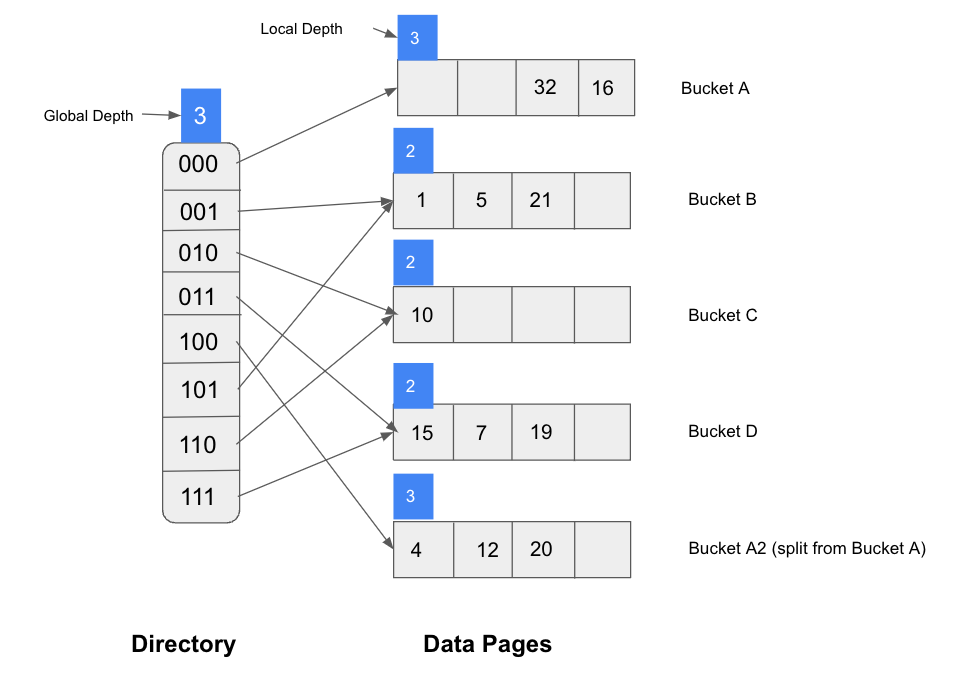
Now through this example, we can find the basic technique used in extendible hashing is that hash function which will take the last k bits, the k depends on the size of the directory. The number of k is called the global depth of the hashed file. In the example above, before insertion, the global depth is 2, it changes to 3 after insertion.
And also as you can see in the example, splitting a bucket may increase the number of pointer but also may not need to increase. To know when should we increase the directory size, we can maintain a local depth for each bucket. Initially, the local depth is equal to the global depth, we increment global depth by 1 each time the directory doubles, and we increment local depth each time when that bucket splits. Whenever the local depth is less than the global depth which means splitting this bucket will not cause directory doubling, on the contrary, if the local depth is equal to the global depth, we need to double the directory to contain the new split bucket.
On the other hand, same as insertion, if we delete the last data entity in one bucket, it can be merged with its split image and decrease the local depth. And if each directory pointer and its split image points to the same bucket, we can halve the directory and reduce the global depth.
Linear Hashing
Linear hashing is another dynamic hashing technique, since for Extendible hashing, we still need to double the size of the directory when there will be an overflow page, people came up with another way to do hash indexing without using the directory, it is called Linear hashing.
Compare to Extendible hashing, Linear hashing is more complicated, before we talk about any detail, let’s figure out some terms and prerequisites:
Hash function of Linear hashing:
First of all, is the hash function, this scheme uses a list of hash functions: h0, h1, h2 …., and the range of each function is twice bigger than its predecessor. For example, the hi function range is M, which means it will map a data item into one of the M buckets, then the range of hi+1 will be 2M, which will map data into 2M buckets. Then if we know the number of bucket M, we can get the hash function:
hi(value) = value mod (2^i * M)
For example, for the h1 function, 4 buckets, the data that we want to insert is 10, then the hashed value is “10 mod (2 * 4)”, which is 2.
Depth:
Same to extendible hashing, linear hashing also has depth information. It maintains a number d, which means we only look at the last d bits of the result of the hash function. If M is chosen to be a power of 2, then d0 is the number of bits needed to represent M, and di = d0+i.
Round of splitting:
Another thing that we should know about is rounds of splitting. During round number Level, only the hLevel and hLevel+1 will be used. And there will have a next pointer which point at the bucket which needs to split, whenever the current bucket is split, the “next” pointer will move to the next bucket, and the buckets will be split from the first bucket in this round to the last one in the round Level. Thus, unlike the extendible hashing, when inserting trigger bucket splitting, we do not split the bucket that needs to be split, we split the next pointer-pointed bucket. And also, since the bucket may not split after full, we can add an overflow page after it in the Linear hashing.
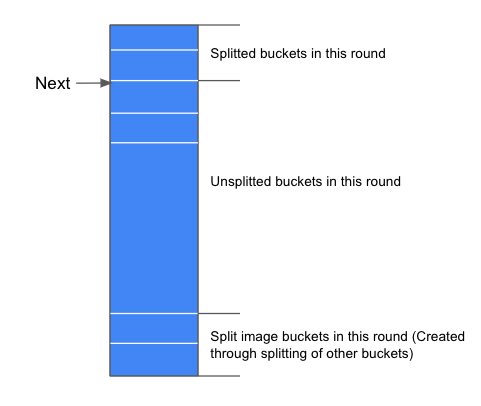
After introducing all those terms, its time to describe Linear Hashing in an example:
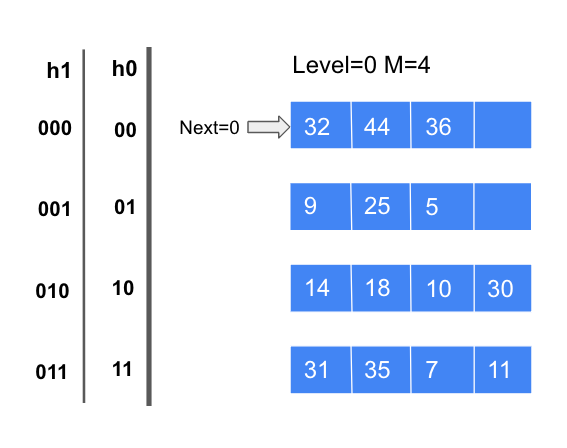
Now let’s create a Linear hash table. In the beginning, the round level is 0, number of buckets at level 0 is 4, thus the number of buckets at level i will be 2^i * 4, since the number of buckets at level0 M is 4 = ²², the depth of level 0 d0 = 2, so in this example, we will take a look at the last two bits of the number.
- For number 32, 32 mod (²⁰ * 4) = 0, the last two bits are 00, thus, it should go to the first bucket;
- For number 9, 9 mod (²⁰ * 4) = 1, the last two bits are 01, thus it goes to the second bucket.
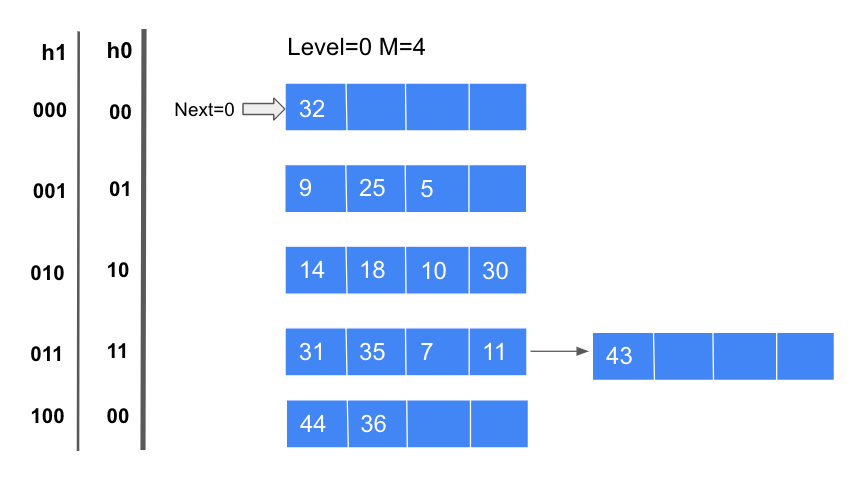
Then we can insert all the other numbers based on the hash function. Now if we want to insert 43 into this hash file, based on the hash function, 43 should go to the last bucket, but we can notice that the last bucket is full, to finish this insertion, since the linear hashing will not split the bucket which needs to split, we need to add an overflow page after the last bucket to contain 43 and we need to trigger a split. Whenever a split is triggered the Next bucket is split, and the next level hash function hlevel+1 should be used to redistribute data items in the Next bucket. The hlevel+1 function is:
hlevel+1(value) = <value> mod (2^(1evel+1) * 4)
And since the number of level+1 buckets is 8 = ²³ now, the depth changes to 3. So based on the new hash function, 32 stays at the first bucket, but 44 and 36 will move to the newly inserted bucket. After all that, the Next pointer will +1 and move to the next bucket.
There is something that needs to be mentioned, since now we have two hash functions in this round, h0 and h1, we have to choose which function should we use. If the result of h0 of one data item is in the range from the Next bucket to the last bucket, we can keep using h0, since these buckets haven’t been split. On the contrary, if fall in the range from bucket0 to the Next bucket, which has been split, then we should choose h1 as the hash function.
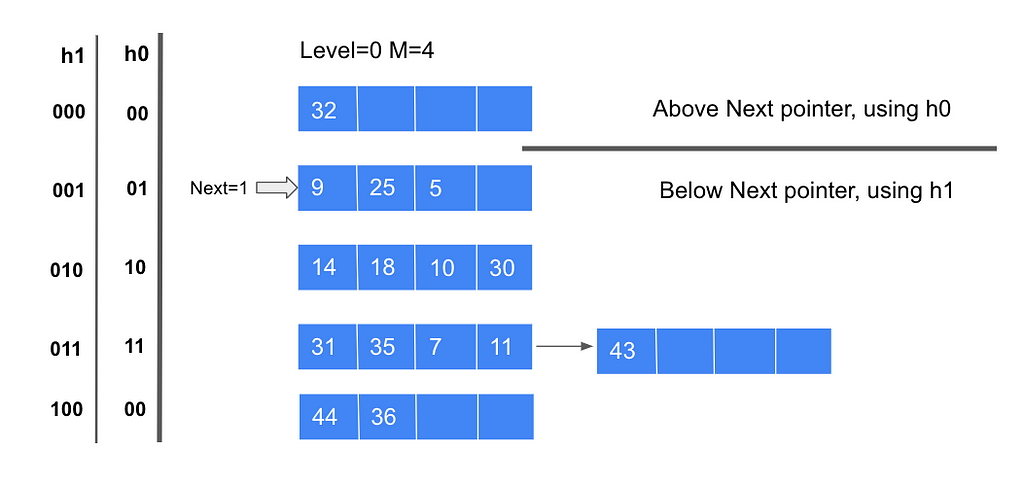
When Next is at the last bucket and a split is triggered, we split the last bucket. Now we will start a new round, Level will be incremented by 1, the number of buckets will double, and Next will reset to 0.
Summary
In this article, I primarily discuss hash-based indexing, which is divided into two types: static hashing and dynamic hashing. Static hashing has a fixed number of buckets, which can result in inefficiency in certain scenarios. On the other hand, dynamic hashing includes extendible hashing and linear hashing. Extendible hashing utilizes a directory to extend the number of buckets, while linear hashing eliminates the directory, splits the buckets in a round-robin fashion, and allows for two hash functions to exist simultaneously.
Thanks for reading!
Level Up Coding
Thanks for being a part of our community! Before you go:
- 👏 Clap for the story and follow the author 👉
- 📰 View more content in the Level Up Coding publication
- 💰 Free coding interview course ⇒ View Course
- 🔔 Follow us: Twitter | LinkedIn | Newsletter
🚀👉 Join the Level Up talent collective and find an amazing job
Exploring the Role of Hash-Based Indexing in Modern Database Architecture was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Zack
Zack | Sciencx (2023-04-07T17:37:11+00:00) Exploring the Role of Hash-Based Indexing in Modern Database Architecture. Retrieved from https://www.scien.cx/2023/04/07/exploring-the-role-of-hash-based-indexing-in-modern-database-architecture/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.