
This content originally appeared on DEV Community and was authored by Josh Bauer
Finding Dynamic Combos
Getting Machine Learning (ML) infrastructure right is really hard. One of the challenges for any ML project getting off the ground is finding the right tools for the job. The number of tools out there that target different parts of the ML lifecycle can easily feel overwhelming.
Sometimes, two tools seem to “just fit” together, and you forget that you’re even working with multiple tools as the lines blur into a coherent experience. One example that every ML Engineer or Data Scientist is familiar with is numpy and pandas. Numpy enables fast and powerful mathematical computations with arrays/matrices in Python. Pandas provides higher-level data structures for manipulating tabular data. While you can of course use one without (explicitly) using the other, they complement each other so well that they are often used together. Pandas works as a usability layer, while numpy supercharges it with compute efficiency.

At Sematic, we care a lot about usability. We aim to make your ML workflows as simple and intuitive as possible, while providing you with best-in-class lineage tracking, reproducibility guarantees, local/cloud parity, and more. You can chain together the different parts of your ML pipelines using Sematic, and specify what kind of resources you need in the cloud. But many parts of the modern ML lifecycle require more than one computing node–you need a cluster. For example, training the original ResNet-50 on a single GPU takes 14 days. Leveraging cluster computing can cut this time drastically. Sematic needed a tool to help supercharge it with cluster computing resources, ideally in a way that “just fits” with another tool.
Ray
Ray pitches itself as “an open-source unified compute framework that makes it easy to scale AI and Python workloads.” Ray can be broken down into three major pieces:
- Ray Core: some primitives for distributed communication, defining workloads and logic to be executed by the distributed compute layer, and initializing computing resources to interact with the system.
- Ray-native domain libraries: libraries provided “out of the box” with Ray for various parts of ML development, such as hyperparameter tuning, data processing, and training.
- Ecosystem of integrations: Ray integrates with many popular tools and frameworks within the broader ML landscape, such as Hugging Face, Spark, PyTorch, and many more.
With these pieces, Ray easily stands as a powerhouse for distributed computing within ML.
Sematic + Ray
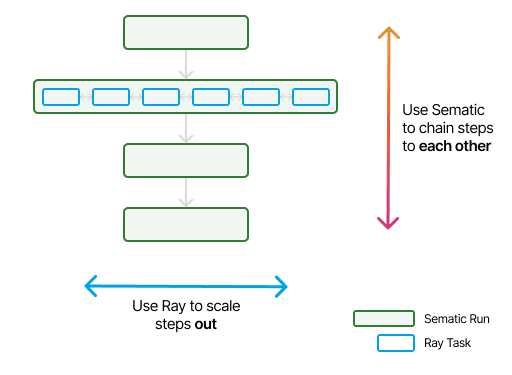
Sematic was designed to let you create end-to-end ML pipelines with minimal development overhead, while adding visualization, lineage tracking, reproducibility, and more. In the language of Sematic, your pipeline steps are Sematic Functions–perhaps one for data processing, one for training, one for evaluation, and so on. Then, within these Sematic Functions, you can use Ray to efficiently scale data processing beyond a single compute node.
That’s great as a conceptual model, but how does Sematic integrate with Ray in practice?
When you’re authoring a pipeline, using Ray within a Sematic Function is as easy as using the RayCluster context manager inside the function. This will spin up a Ray cluster on-demand and enter the ‘with’ context only once the cluster is ready for use. Your code can then use Ray just like it would in any other situation. When your code is done executing (either successfully or unsuccessfully), the Ray cluster will be cleaned up for you. The Ray cluster uses the same container image as your pipeline so that the same code and dependencies are guaranteed to be present on every node.
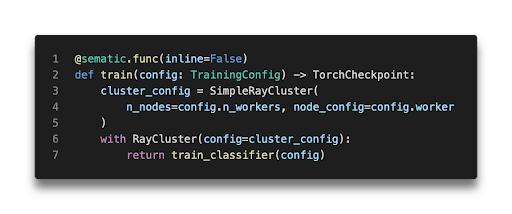
If you’re familiar with Ray or Sematic, you likely know that both can be used locally as well as in the cloud. Sematic’s Ray integration is no exception! When you execute the code above locally, a local-process based Ray cluster will be created instead of one executing on Kubernetes. This enables rapid local development, where you can use all of your favorite debuggers and other tools until you’re ready to move execution to the cloud.
Unlocking New Use Cases
This combination of Sematic + Ray can jumpstart your journey to a world-class ML platform. Using these tools together, your Sematic Functions can now do things such as:
- Do quick and efficient distributed training on a PyTorch image classifier using PyTorch Lightning and Ray.
- Perform distributed Hyperparameter tuning of a TensorFlow natural language model using Ray Tune.
- Do distributed data processing and ingest with Ray Datasets.
And you can do all these things while taking advantage of Sematic’s lineage tracking, visualization and orchestration capabilities.
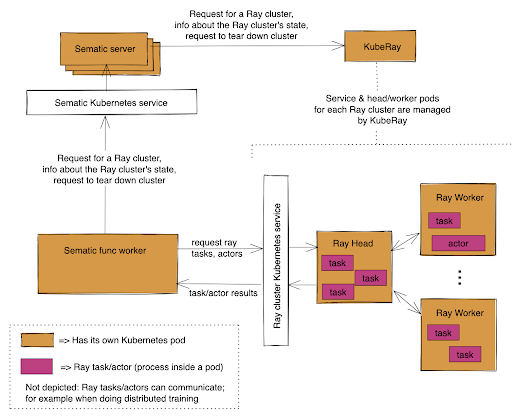
A Look Behind the Scenes
When you use RayCluster as above, there’s a lot going on behind the scenes. Sematic uses KubeRay, a tool developed by the maintainers of Ray to manage Ray clusters within Kubernetes. Your code execution will result in calls to the Sematic server, which will in turn publish information about the required cluster to KubeRay. KubeRay will then create and manage the new Ray cluster for you.
Since Sematic knows all about your code and what container image it’s using, it can ensure that KubeRay uses that same image for the Ray head and workers. This means that you don’t have to worry about any new dependency management when using Ray from Sematic – any code that can be used from your Sematic Functions can be used from Ray, even without using Ray’s Runtime environments!
Learning More
If you want to know more about Sematic’s Ray integration, you can check out our docs. If you’re looking for something more hands on, check out one of our examples doing distributed training and evaluation using Ray from Sematic. One uses PyTorch Lightning to do distributed training of a ResNet model, and another uses Ray’s AIR APIs (including Ray Datasets) to do distributed training of a simple image classifier on the CIFAR10 dataset. You can also join our Discord if you’d like to ask some questions. We’re always happy to help!
Sematic’s Ray integration is part of Sematic’s paid “Enterprise Edition”. Get in touch if you’d like to use it! Rather play around with Sematic for free first? Most of it is free and open-source!
This content originally appeared on DEV Community and was authored by Josh Bauer
Josh Bauer | Sciencx (2023-04-17T19:56:08+00:00) Sematic + Ray: The Best of Orchestration and Distributed Compute at your Fingertips. Retrieved from https://www.scien.cx/2023/04/17/sematic-ray-the-best-of-orchestration-and-distributed-compute-at-your-fingertips/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.