
This content originally appeared on DEV Community and was authored by Scofield Idehen
What is Customer Churn?
Customer churn is when customers or subscribers discontinue business with a firm or service.
To be simple, it is when customers stop being your customer.
Telco churn data includes information about a fictitious telecom company that provided home phone and Internet services to 7,043 California customers in the third quarter. Which customers have left, stayed, or signed up for their service shows?
In this project, we aim to find the likelihood of a customer leaving the organization, the key indicators of churn, and the retention strategies that can be implemented to avert this problem.
1.1 The Data
The data for this project is in a CSV format. The following describes the columns present in the data.
- Gender — Whether the customer is a male or a female
- SeniorCitizen — Whether a customer is a senior citizen or not
- Partner — Whether the customer has a partner or not (Yes, No)
- Dependents — Whether the customer has dependents or not (Yes, No)
- Tenure — Number of months the customer has stayed with the company
- Phone Service — Whether the customer has a phone service or not (Yes, No)
- MultipleLines — Whether the customer has multiple lines or not
- InternetService — Customer’s internet service provider (DSL, Fiber Optic, No)
- OnlineSecurity — Whether the customer has online security or not (Yes, No, No Internet)
- OnlineBackup — Whether the customer has online backup or not (Yes, No, No Internet)
- DeviceProtection — Whether the customer has device protection or not (Yes, No, No internet service)
- TechSupport — Whether the customer has tech support or not (Yes, No, No internet)
- StreamingTV — Whether the customer has streaming TV or not (Yes, No, No internet service)
- StreamingMovies — Whether the customer has streaming movies or not (Yes, No, No Internet service)
- Contract — The contract term of the customer (Month-to-Month, One year, Two year)
- PaperlessBilling — Whether the customer has paperless billing or not (Yes, No)
- Payment Method — The customer’s payment method (Electronic check, mailed check, Bank transfer(automatic), Credit card(automatic))
- MonthlyCharges — The amount charged to the customer monthly
- TotalCharges — The total amount charged to the customer
- Churn — Whether the customer churned or not (Yes or No)
Ask Stage
Here, we put down the questions we intend to answer at the end of the analysis process. The following hypothesis was stated, and questions were asked to guide the analyses.
2.1 Hypothesis
Null Hypothesis (H0): The sample has a Gaussian distribution in the numerical feautures.
Alternative Hypothesis (H1): The sample does not have a Gaussian distribution in the numerical features.
- Statistical Normality Tests:
- Normality tests determine if a dataset is normally distributed about the mean value. It is assumed that any measurement values will follow a normal distribution with an equal number of measurements above and below the mean value.
- Gaussian distribution is a continuous probability distribution with symmetrical sides around its centre. Its mean, median and mode are equal.
- Popular normality tests — D’Agostino’s K², Anderson-Darling .
- This dataset has three numerical features — Monthly Charges , Tenure, and TotalCharges.

Monthly Charges do not have a Gaussian Distribution.

Tenure does not have a Gaussian Distribution
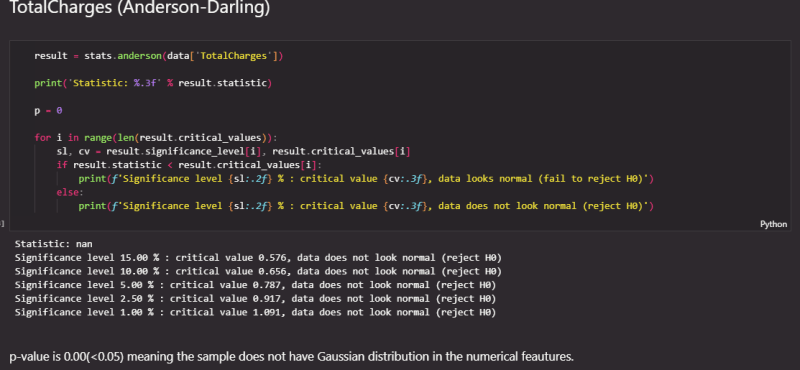
TotalCharges does not have a Gaussian Distribution
We therefore reject our null hypothesis, which states that the sample has a Gaussian distribution in the numerical features.
2.2 Questions
For our Exploratory Data Analysis (EDA), we must ask the right questions:
- Does longer tenure increase churn?
- Is there any pattern in Customer Churn based on gender?
- Which type of contract keeps more customers?
- What’s the most profitable Internet service type?
2.3. Bivariate Analysis
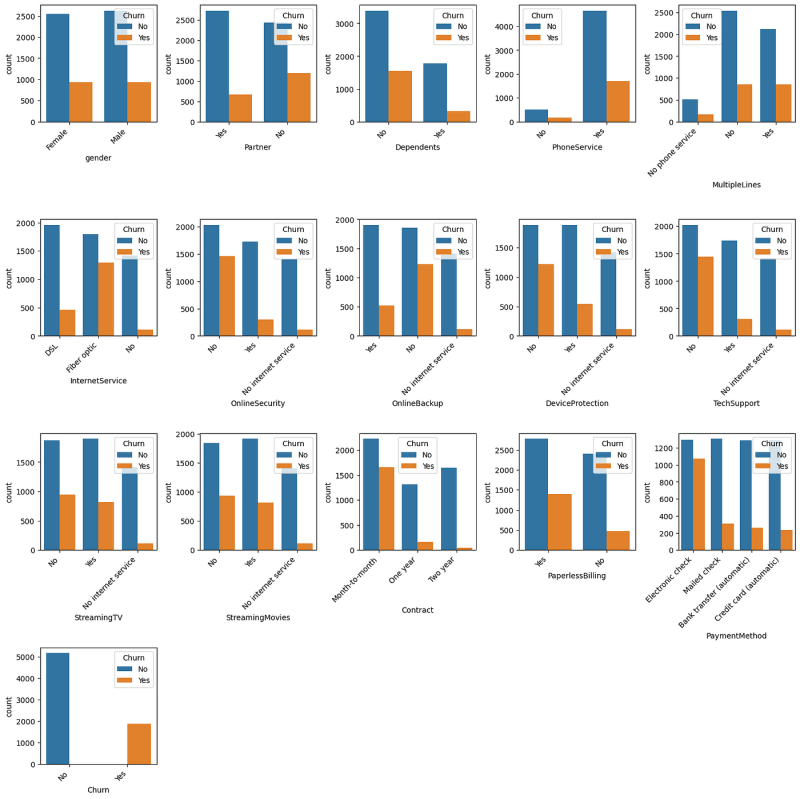
Observations:
Gender is not affecting the churn.
Customers who are more likely to churn:
1. Who doesn’t have a partner
2. Who doesn’t have dependants
3. Who has phone service
4. Who uses fibre optic as internet service
5. Who didn’t subscribe to extra services (Online Backup, Online Security, etc.)
6. Who has a contract month-to-month basis
7. Who chose Paperless Billing
8. Who uses Electronic check
2.4. Multivariate Analysis
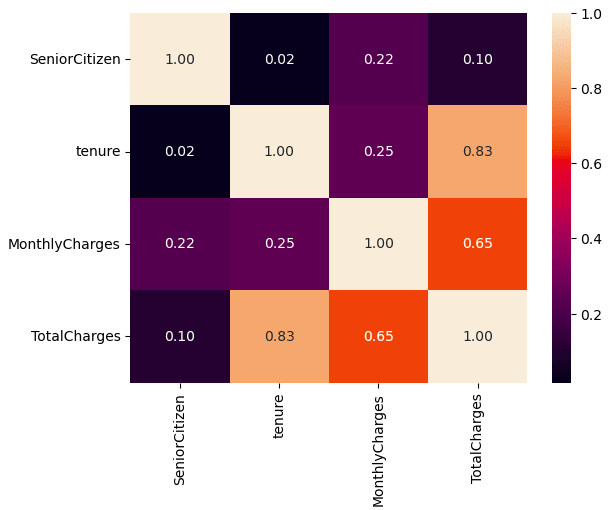
Tenure is highly correlated to TotalCharges but not to MonthlyCharges.
However, MonthlyCharges and TotalCharges are somehow correlated to each other, but the correlation value is less than 0.8.
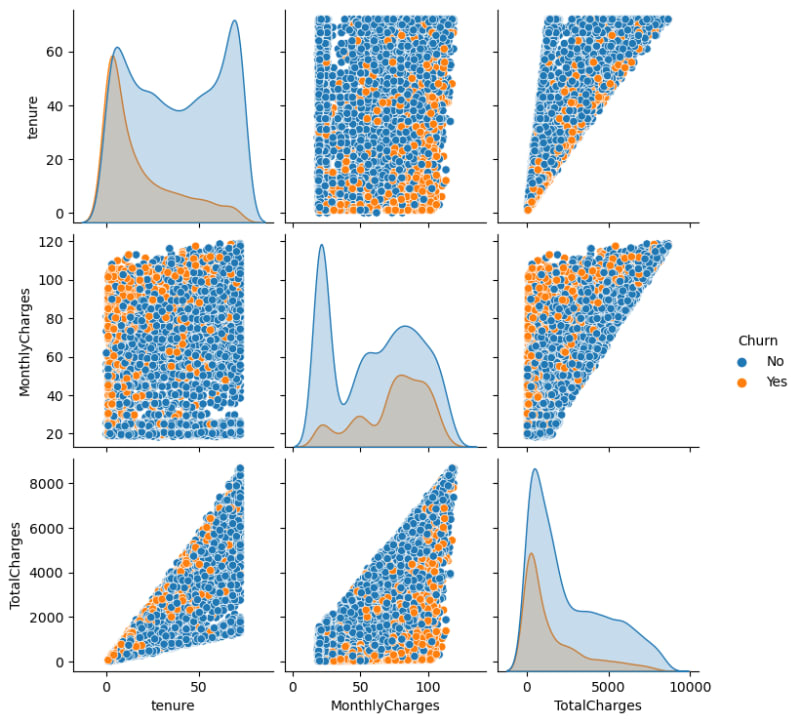
Observations:
Customers who have a shorter time to subscribe to the service (smaller tenure) are most likely to churn.
Customer with lower MonthlyCharges is most likely to stay, and those with higher Monthly Charges is most likely to churn.
Interestingly, customers with lower TotalCharges are most likely to churn.
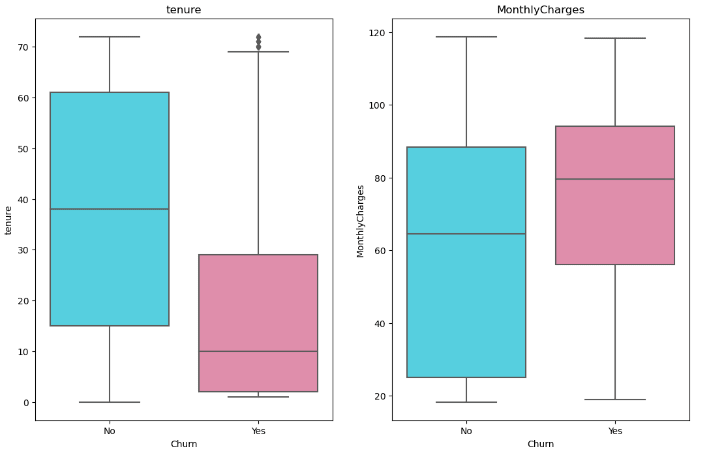
Churning customers have a much lower tenure median compared to the median of non-churners
Churning customers have higher monthly median charges and a much lower interquartile range compared to that non-churners
3.0 Data Preparation and Processing
At this stage, we organize the data to make it fit for analysis. Cleanliness and consistency of data are the objectives here.
3.1 Issues with the data
1. Some of the columns are irrelevant.
2. some of the columns are not in their respective data types.
3. The data values in the column payments method needs is not good for readability.
4. The data has missing values
3.2 Cleaning the Data
Given that this article is to present a summary, I will focus on the major activities performed on the DataFrames. The detailed functions will be found in the notebook, a link to which will be attached at the end of the article.
1. Drop irrelevant columns
2. Replace the correct data types in their respective columns
3. Rename the data values for better readability.
4.0 Answering the Questions
Here, I combine the “Analyse” and “Share” stages of the data analysis process through the code and visualisations.
4.1. Does longer tenure increase churn?
No, customers with longer tenure have less churn rate.

4.2. Is there any pattern in Customer Churn based on gender?
The plot below shows that churn for both genders is very similar.
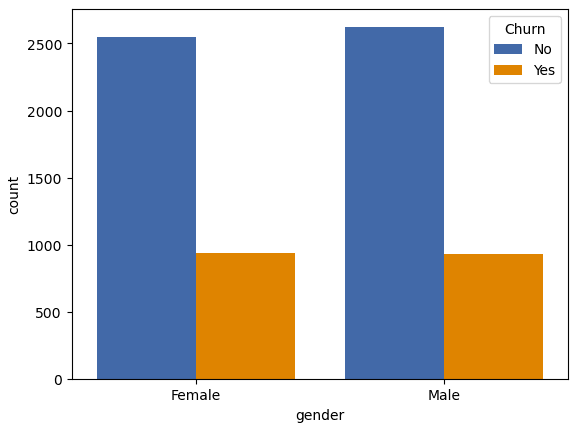
4.3. Which type of contract keeps more customers?
The churn rate for month-to-month contracts is much higher than for other contract durations.

4.4. What’s the most profitable Internet service type
FiberOptic InternetService keeps more customers

5.0 Feature Processing & Engineering
Here is the section to clean, process the dataset and create new features.
5.1 Drop Duplicates

5.2 Creating new features
Some columns are related to each other, so we’ll add them together to avoid having unnecessary features.

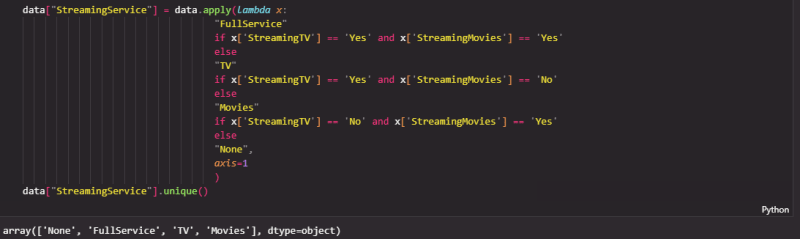

After that, we’ll drop the original colums since we no longer need them.

5.3. Impute Missing Values

5.4 Data Imbalance Check

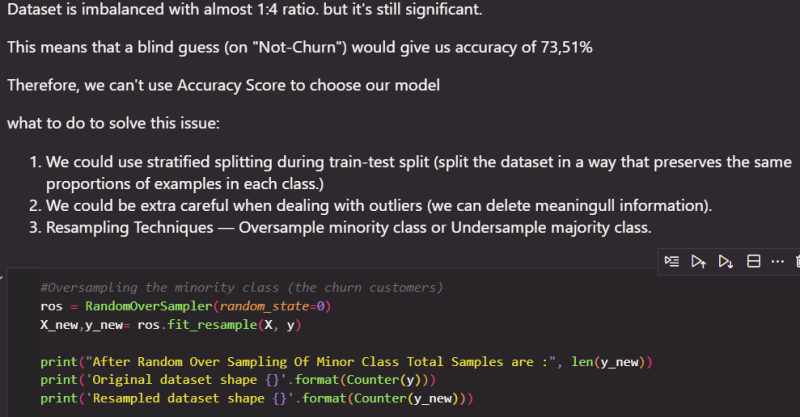

Now our data is balanced
5.5 Dataset Splitting
I split my train data into train and evaluation/test sets.

5.6 Features Encoding & Scaling
I used the LabelEncoder to turn our target column into numbers that ml models can understand.


Do the same encoding for your test set.

6.0 Machine Learning Modeling
Algorithm selection is a key challenge in any machine learning project since no algorithm is the best across all projects.
Generally, we need to evaluate a set of potential candidates and select those that provide better performance for further evaluation.
In this project, we compare 6 different algorithms, all already implemented in Scikit-Learn.
- Logistic Regression
- RandomForest Classifier
- XGBoost Classifier
- K Nearest Neighbors
- Support Vector Machines
- DecisionTreeClassifier
6.1. Models Comparison
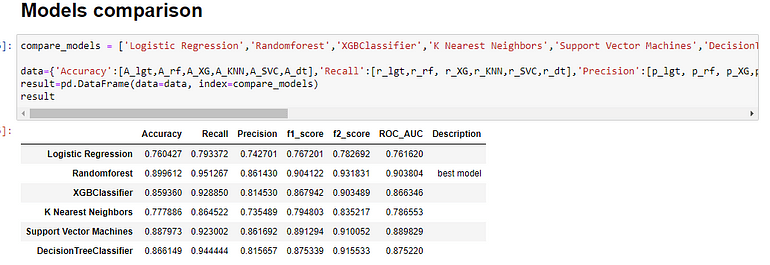
We must train all the algorithms using the default hyperparameters. The F1 score of many machine learning algorithms is highly sensitive to the hyperparameters chosen for training the model.
A more in-depth analysis will include evaluating a wider range of hyperparameters (not only default values) before choosing a model (or models) for hyperparameter tuning. Nonetheless, this is out of the scope of this article.
In this example, we will only further evaluate the model with a higher F1 score using the default hyperparameters. As shown above, this corresponds to the RandomForest Classifier, which shows an F1 score of 90%.
6.2. Evaluation of the Chosen Model
k-Fold Cross-Validation
Cross-validation is a resampling procedure used to evaluate machine learning models on a limited data sample.
The procedure has a single parameter called k, which refers to the number of groups a given data sample will be split into.
As such, the procedure is often called k-fold cross-validation. When a specific value for k is chosen, it may be used instead of k about the model, such as k=5 becoming 5-fold cross-validation.
Cross-validation is primarily used in applied machine learning to estimate the skill of a machine learning model on unseen data.
That is, to use a limited sample to estimate how the model is expected to perform in general when used to make predictions on data not used during the model's training.
It is a popular method because it is simple to understand. It generally results in a less biased or less optimistic estimate of the model skill than other methods, such as a simple train/test split.


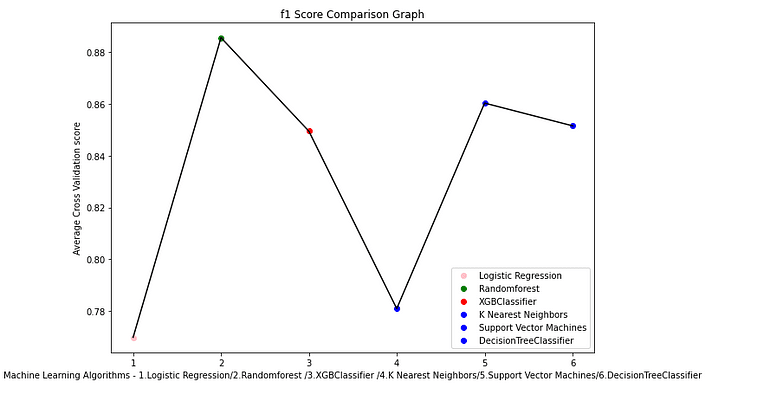
From the graph, Randomforest is the best average cross-validation score and also the best-performing model.
6.3. Hyperparameter tuning
The three best models was selected for hyperparameter tuning
a. RandomForest Classifier
b. Support Vector Machines
c. DecisionTree Classifier
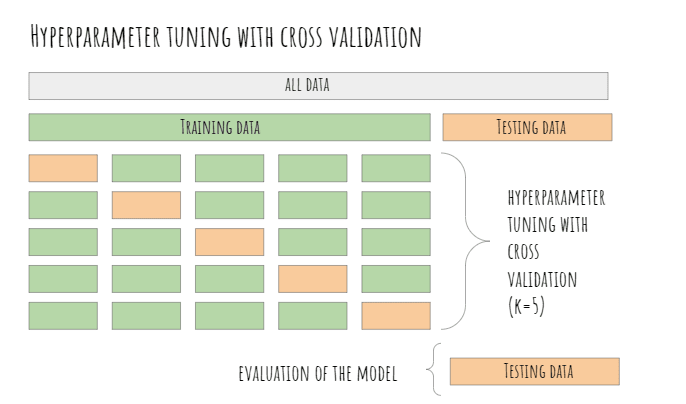
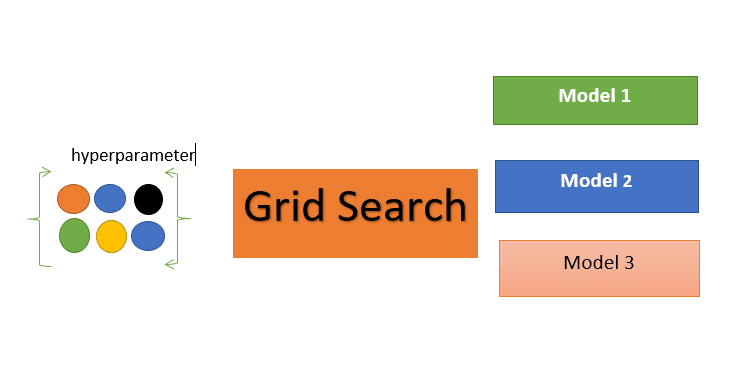
Thus far, we have split our data into a training set for learning the model's parameters and a testing set for evaluating its performance. The next step in the machine learning process is to perform hyperparameter tuning.
The selection of hyperparameters consists of testing the model's performance against different combinations of hyperparameters, selecting those that perform best according to a chosen metric and a validation method.
For hyperparameter tuning, we need to split our training data again into a set for training and testing the hyperparameters (often called validation sets). It is a very common practice to use k-fold cross-validation for hyperparameter tuning.
The training set is divided again into k equal-sized samples, 1 sample is used for testing, and the remaining k-1 samples are used for training the model, repeating the process k times.
Then, the k evaluation metrics (in this case, the accuracy) are averaged to produce a single estimator.
It is important to stress that the validation set is used for hyperparameter selection and not for evaluating the final performance of our model, as shown in the image below.
a. RandomForest Classifier

There is not much difference in the model performance after hyperparameter tuning
b. Support Vector Machines

There is not much difference in the model performance after hyperparameter tuning
c. DecisionTree Classifier
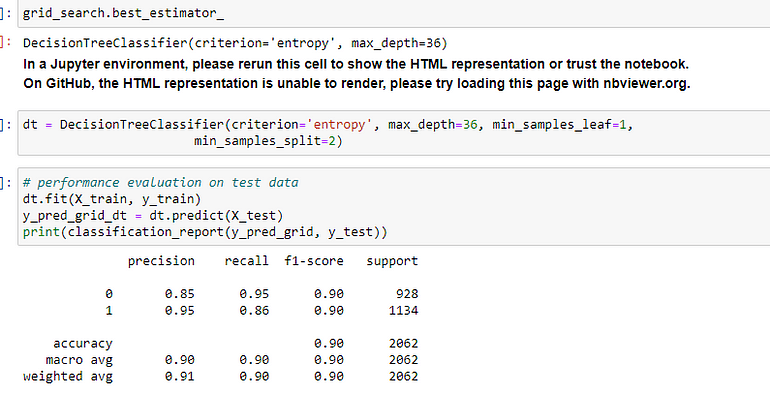
There is a difference in the model performance after hyperparameter tuning. The model F1 score increased after tuning
6.4. Future predictions
Check the model's performance (best hyperparameters ) using the confusion matrix and some evaluation metrics.
RandomForest Classifier

Based on the confusion matrix:
- We successfully predicted 869 customers who don’t churn and 976 who churn
- 167 customers are predicted to churn when they actually won’t
- 50 customers are predicted not to churn when they churn
Support Vector Machines

Based on the confusion matrix:
- We successfully predicted 881 customers who don’t churn and 947 who churn
- 155 customers are predicted to churn when they actually won’t
- 79 customers are predicted not to churn when they churn
DecisionTree Classifier

Based on confusion matrix:
- We successfully predicted 801 customers who don’t churn and 962 who churn
- 235 customers are predicted to churn when they actually won’t
- 64 customers are predicted not to churn when they churn
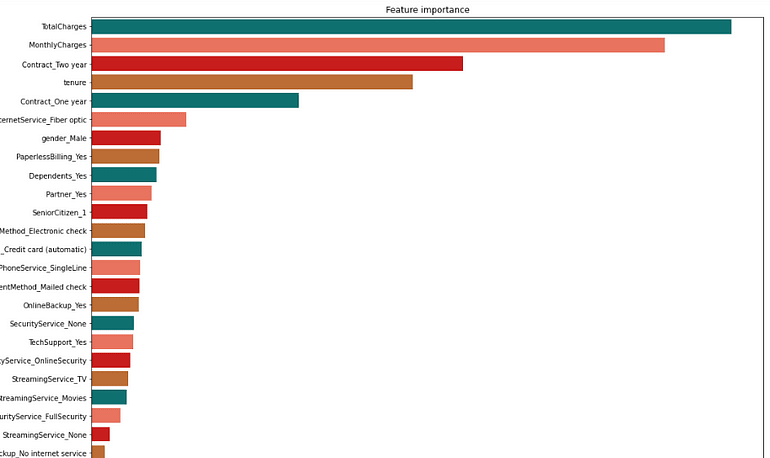
6.5. Model Feature Importance
RandomForest Classifier

DecisionTree Classifier
7.0. Conclusions and Recommendations.
We have walked through a complete end-to-end machine learning project using the Telco customer Churn dataset. We started by cleaning the data and analyzing it with visualization.
Then, to build a machine learning model, we transformed the categorical data into numeric variables (feature engineering). After transforming the data, we tried 6 different machine-learning algorithms using default parameters.
Looking at model results, the best Precision on the test set is achieved by RandomForest Classifier with 0.89.
Given the high data imbalance towards non-churners, comparing F1 scores to get the model with the best score on joint precision and recall makes sense. This would also be the RandomForest Classifier with an F1 score of 0.90.
Given the scores of the best-performing models, it can be observed that F1 scores are not much above 90%. Further optimization efforts should be carried out to achieve a higher score and increase prediction power for more business value.
When we consider the Exploratory Data Analysis we did, it is clear that this company has some issues with their Month-to-month customers.
What kind of incentives can this company offer customers to sign one- or Two-year contracts?
What adjustments can be made to Month-to-Month contracts that would be more favourable to customers without taking away the appeal of a One-year or Two-year contract?
For RandomForest Classifier, you can see TotalCharges positively influences the data. Some features like InternetService_fibreoptics,contract_one year, etc., should be examined critically since it has a negative impact on the target column.
Recommendation and Request
We should pay more attention to customers who meet the criteria below.
- Contract: Month-to-month
- Tenure: Short tenure
- Internet service: Fiber optic
- Payment method: Electronic check7.0 Conclusion
Find below a link to all the code on GitHub.
To read more exciting content on AI and Data Science, follow LearnHub Blog, subscribe to our newsletter and get the most updated tech news and How-To every day.
This article was written by Emmanuel Ikogho; Emmanuel is a Data Scientist currently training with Azubi Africa to advance his Data Career.
This content originally appeared on DEV Community and was authored by Scofield Idehen
Scofield Idehen | Sciencx (2023-05-07T08:01:49+00:00) How to Predict Customer Churn with Machine Learning. Retrieved from https://www.scien.cx/2023/05/07/how-to-predict-customer-churn-with-machine-learning/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.