
This content originally appeared on Level Up Coding - Medium and was authored by Kamini Kamal
State management is an important aspect of building stream processing applications using Apache Kafka. In Kafka, the state can refer to any kind of mutable data that is maintained by a stream processing application, such as aggregated metrics, running counts, or join state.
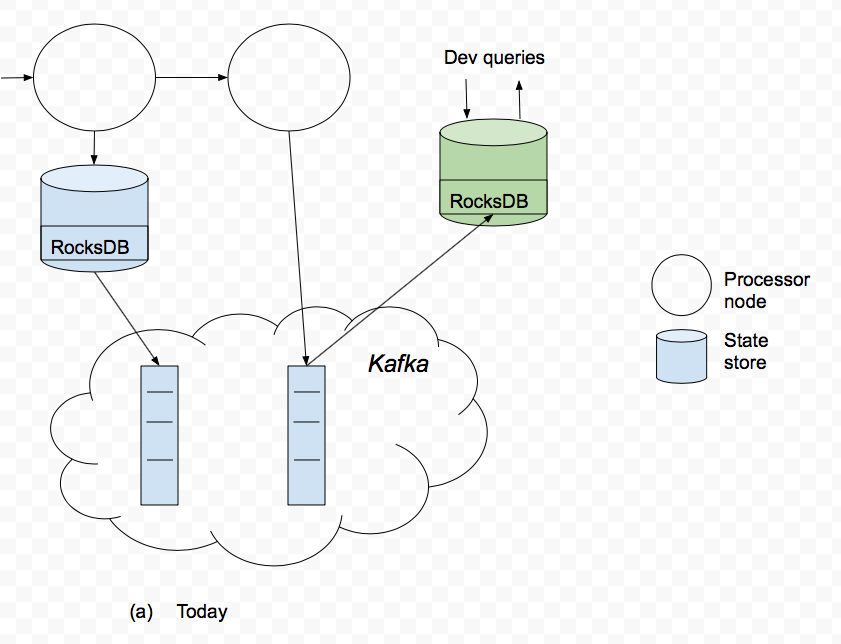
To manage the state in Kafka, stream processing applications typically use the Kafka Streams library, which provides a number of abstractions for working with the state. Specifically, Kafka Streams provides a key-value store abstraction, which can be used to maintain an arbitrary state for a stream processing application.
The key-value store in Kafka Streams is partitioned and distributed across the Kafka cluster, allowing it to scale horizontally as the application’s load and data volumes increase. In addition, Kafka Streams provides several built-in state store implementations, such as the RocksDB-based state stores, which provide strong consistency guarantees.
In Kafka Streams, the state is typically managed through the use of windowed aggregates, which group related events together based on a time window or other criteria. For example, a stream processing application might maintain a running count of events over the past 10 minutes, or compute an average value for a specific field over the past hour.
To update the state in Kafka Streams, applications typically use the Processor API, which provides low-level access to the underlying Kafka Streams state stores. Applications can also use the DSL API, which provides higher-level abstractions for working with streams and windows.
State stores are an important component of stream processing applications built using Apache Kafka, and they can be used for a wide range of use cases. Here are some common use cases for state stores in Kafka:
- Aggregation and filtering: Stream processing applications often need to aggregate or filter data based on certain criteria. For example, an application might need to compute the average value of a field across all incoming events or filter out events that do not meet certain conditions. A state store can be used to maintain the current state of the computation, allowing the application to efficiently process incoming events in real time.
- Joins: Stream processing applications often need to join multiple streams of data together. For example, an application might need to join a stream of customer orders with a stream of customer information in order to compute a report. A state store can be used to maintain the current state of the join, allowing the application to efficiently perform the join in real time.
- Machine learning: Stream processing applications often need to use machine learning models to make predictions or perform classification tasks. A state store can be used to maintain the current state of the model, allowing the application to efficiently make predictions on incoming events in real time.
- Anomaly detection: Stream processing applications often need to detect anomalies or outliers in incoming data. A state store can be used to maintain a statistical model of the data, allowing the application to detect when incoming events deviate from the expected distribution.
- Complex event processing: Stream processing applications often need to detect complex patterns in incoming data, such as sequences of events or temporal patterns. A state store can be used to maintain the current state of the pattern-matching algorithm, allowing the application to efficiently process incoming events in real time.
Overall, state stores are a critical component of stream processing applications built using Apache Kafka, and they can be used for a wide range of use cases. By maintaining the current state of computation or analysis, state stores allow applications to process incoming events in real-time, providing powerful capabilities for real-time data processing and analysis.
How to configure the store for state management in Kafka?
In Apache Kafka, state management is typically done through the use of the Kafka Streams library, which provides abstractions for managing and querying stateful data. To configure a store for state management in Kafka Streams, you can use the StreamsConfig class to specify the relevant configuration options.
Here is an example of how to configure a RocksDB state store in Kafka Streams:
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "my-streams-app");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.STATE_DIR_CONFIG, "/tmp/kafka-streams");
// Configure the RocksDB state store
props.put(StreamsConfig.STATE_STORES_CONFIG,
Arrays.asList(
new KeyValueStoreSupplier() {
@Override
public String name() {
return "my-state-store";
}
@Override
public KeyValueStore<Bytes, byte[]> get() {
return new RocksDBStore(name, ...);
}
@Override
public String metricsScope() {
return "my-state-store-metrics";
}
}
));
KafkaStreams streams = new KafkaStreams(topology, props);
In this example, we are configuring a RocksDB state store with the name “my-state-store”. The STATE_DIR_CONFIG property specifies the directory where Kafka Streams should store the state data on disk. The STATE_STORES_CONFIG property specifies a list of state stores that should be created when the stream processing application starts up.
Note that in order to use a RocksDB state store, you will also need to include the RocksDB library in your application’s classpath. The Kafka Streams documentation provides more information on how to do this.
What other state store options are available for Kafka?
While Kafka provides its own state store called RocksDB, there are other state store options available that can be used with Kafka as well. Some of the popular state store options for Kafka are:
- Apache Cassandra: Cassandra is a distributed NoSQL database that can be used as a state store for Kafka. It provides high availability, fault tolerance, and scalability, making it a popular choice for stateful stream processing applications.
- Apache HBase: HBase is another distributed NoSQL database that can be used as a state store for Kafka. It provides low latency, high throughput, and strong consistency, making it a good choice for real-time data processing applications.
- Redis: Redis is an in-memory key-value store that can be used as a state store for Kafka. It provides high performance, low latency, and scalability, making it a popular choice for real-time data processing applications.
- Apache Ignite: Ignite is a distributed in-memory computing platform that can be used as a state store for Kafka. It provides high performance, fault tolerance, and scalability, making it a good choice for real-time data processing and machine-learning applications.
- Google Cloud Spanner: Spanner is a distributed relational database that can be used as a state store for Kafka. It provides strong consistency, high availability, and global scalability, making it a good choice for applications that require global access to data.
Overall, there are many state store options available for Kafka, each with its own strengths and weaknesses. The choice of state store depends on the specific requirements of the application, such as performance, scalability, fault tolerance, and consistency.
References
State store in Kafka was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Kamini Kamal
Kamini Kamal | Sciencx (2023-05-09T13:03:28+00:00) State store in Kafka. Retrieved from https://www.scien.cx/2023/05/09/state-store-in-kafka/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.