
This content originally appeared on Level Up Coding - Medium and was authored by Chris Bao
Background
Recently, the engineering team at Amazon Prime Video posted an article that becomes super popular in the software community. Many discussions arose concerning how to design a scalable application in the modern cloud computing era.
Scalability is one critical metric for designing and developing an online application. Technically it is a challenging task, but the cloud made it easy; because the public cloud services providers like AWS and Azure do the job for you. Virtual machine, Container and Serverless, you have so many powerful technologies to scale your application and business.
But the problem is you need to choose the one suitable for your application. So in this article, let’s examine the details of why Aamzon refactors the application and how they do it.
Since Amazon doesn’t expose the code implementation of this project, our analysis is based on the original post and the technical understanding of AWS. All right?

Case study
The product refactored is called Amazon Prime Video Monitoring Service, which monitors the quality of thousands of live video streams. This monitoring tool runs the real-time analysis of the streams and detects quality issues. The entire process consists of 3 steps: media converter, defect detector and real-time notification.
- media converter: converting input audio/video streams to frames.
- defect detector: executing machine learning algorithms that analyze frames to detect defects.
- real-time notification: sending real-time notifications whenever a defect is found.
The old architecture goes as follows:
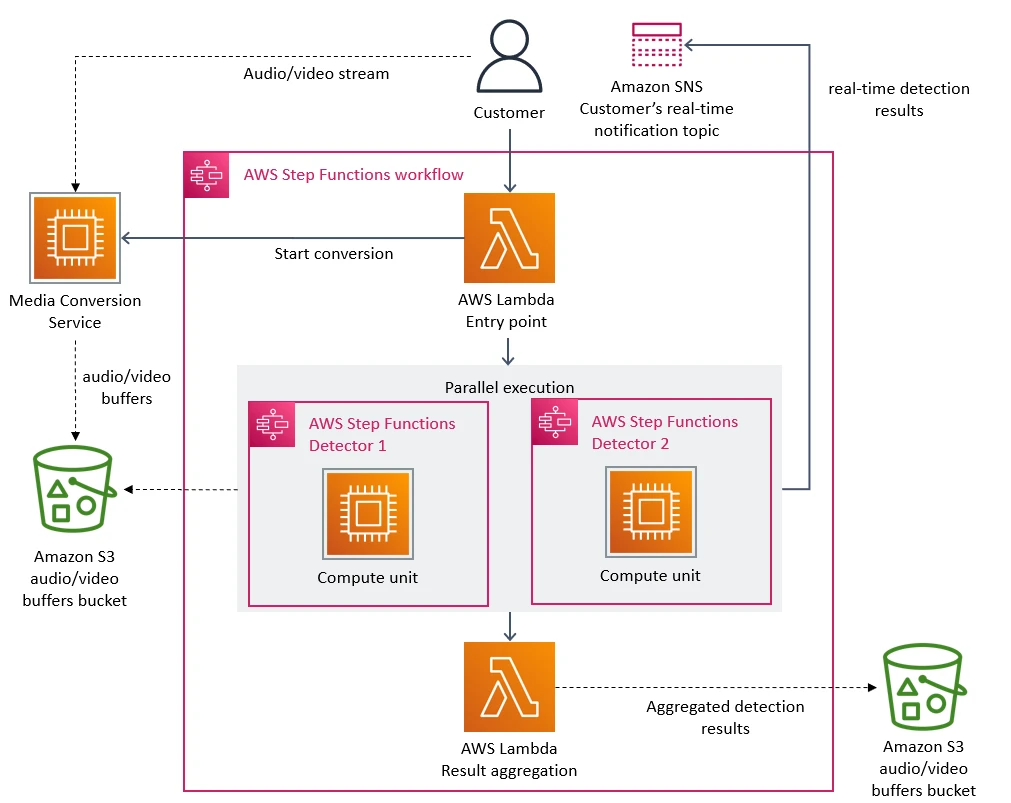
In this microservices architecture, each step was implemented by AWS Lambda serverless service (I assume you already know what is serverless; if not, please refer to other online documents). And the entire workflow was orchestrated by AWS Step Functions, which is a serverless orchestration service.
AWS Step Functions State Transition
The first bottleneck is just coming from AWS Step Functions. But before discussing the issues of this architecture, we need to understand what is AWS Step Functions and how it works basically. This knowledge is very critical to understand the performance bottlenecks later.
AWS Step Functions is a serverless service that allows you to coordinate and orchestrate multiple AWS serverless functions using a state machine. You can define the workflow of serverless applications as a state machine, which represents the different states and transitions of the application’s execution.
The State machine can be thought of as a directed graph, where each node represents a state, and each edge represents a transition between states, which is used to model complex systems. The topic of state machine isn’t in the scope of this article, I will write a post about it in the future. So far, you only need to know each state in the state machine represents a specific step in the workflow, while transitions represent the events that trigger the transition from one step to another. You can find many examples of AWS Step Functions in this repo, please take a look at what problems you can solve with it.
In theory, this serverless-based microservices architecture can scale out easily. However, as the original post mentioned it “hit a hard scaling limit at around 5% of the expected load. Also, the overall cost of all the building blocks was too high to accept the solution at a large scale.“
So the bottleneck is the cost! Because AWS Step Functions charges users per state transition, and in this monitoring service case, it performed multiple state transitions for every second of the video stream, it quickly hit the account limits!
As a software engineer working in a team, maybe you can just focus on writing great code, but when you need to select the tech stack, you have to consider the cost, especially when your application is running on the cloud.
AWS S3 Buckets Tier-1 requests
As mentioned above, the media converter service splits videos into frames, and the defect detector service loads and analyzes the frames later. So in the original architect, the frame images are stored in the Amazon S3 bucket. As the original post mentioned “Defect detectors then download images and processed it concurrently using AWS Lambda. However, the high number of Tier-1 calls to the S3 bucket was expensive.”
So the second bottleneck is also a cost issue. But what is a Tier-1 call or request in the context of AWS S3?
A Tier-1 request refers to an API request that retrieves or lists objects in an S3 bucket, and is charged at a higher rate than other types of API requests. AWS S3 API requests are classified into two categories: standard requests and Tier-1 requests.
- standard requests: including API requests such as PUT, COPY, DELETE and HEAD requests.
- Tier-1 requests: including API requests such as GET and LIST requests.
Tier-1 requests are expensive because they involve retrieving and listing objects in an AWS S3 bucket, which is more resource-intensive. Because when you retrieve or list objects, S3 needs to scan through the entire bucket to find the targets. Additionally, S3 needs to transfer the data for each retrieved object over the network. So basically, it consumes more storage and network resources on the cloud.
Monolith Architecture
Based on these two bottlenecks, they refactored this monitoring tool and returned to the monolith architecture as follows:
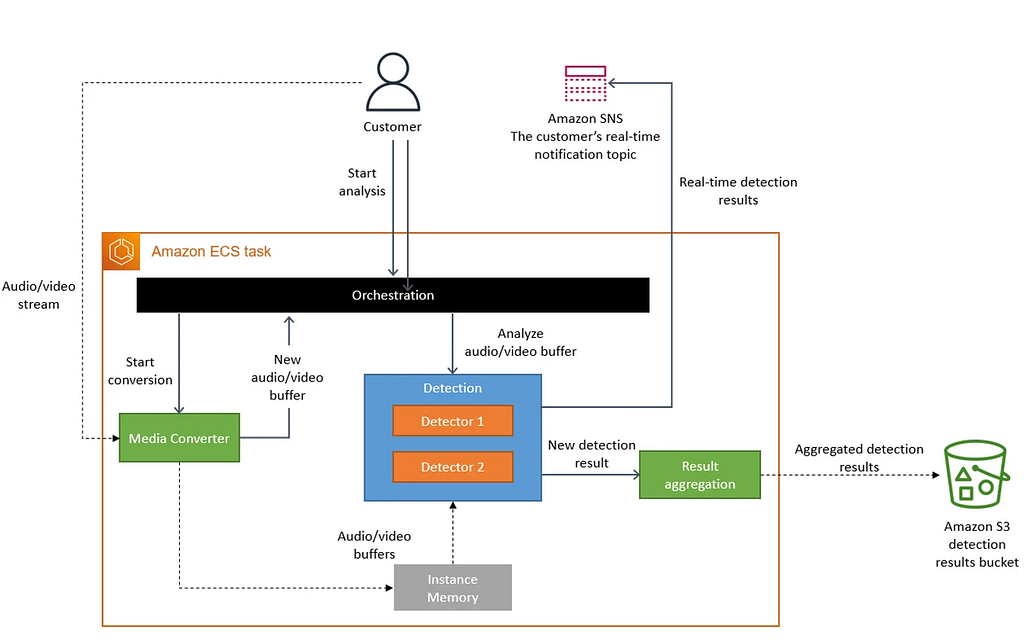
In the new design, everything is running inside a single process host in Amazon Elastic Container Service(ECS). In this monolith architecture, the frames are stored in the memory instead of S3 buckets. It doesn’t need serverless orchestration service either.
How does this new architecture run at a high scale? They directly scale out and partition the Amazon ECS cluster. In this way, they get a scalable monitoring application with a 90% cost reduction.
Summary
There is no perfect application architecture that can fit all cases. In the cloud computing era, you need to understand the service you used better than before and make a wise decision.
Level Up Coding
Thanks for being a part of our community! Before you go:
- 👏 Clap for the story and follow the author 👉
- 📰 View more content in the Level Up Coding publication
- 💰 Free coding interview course ⇒ View Course
- 🔔 Follow us: Twitter | LinkedIn | Newsletter
🚀👉 Join the Level Up talent collective and find an amazing job
Scalability Lessons Learned from Amazon Return to The Monolith was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Chris Bao
Chris Bao | Sciencx (2023-05-12T17:19:57+00:00) Scalability Lessons Learned from Amazon Return to The Monolith. Retrieved from https://www.scien.cx/2023/05/12/scalability-lessons-learned-from-amazon-return-to-the-monolith/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.