
This content originally appeared on DEV Community and was authored by Benjamen Pyle
I've been following along the past couple of weeks in the "wake" of the article by the Prime Video Team. I've seen a lot of rebuttal-type articles by some folks that I respect so I didn't want to continue to add more of the same opinions in that direction. I think people that have spoken up in support of Serverless architecture have done a fantastic job of articulating why and when not to. What I wanted to write was something in my more official day-to-day title as CTO and why I support Serverless design choices for my teams and customers. So consider this, Why Serverless, a CTO Perspective.
Who am I
If this is the first article you've ever read by me, give me just a sentence or four to share who I am. First and foremost I'm a builder and developer. I've been shipping value to customers for over 25 years in a bunch of different industries. I've written C++ with MFC, was an early adopter of Perl's CGI library, went through the early days of C# (Webforms), Java Beans and navigated the challenges of AJAX in the 2000s and early 2010s. I started leading teams around 2005 and have been working with developers, architects, product people and executives pretty much ever since. I say all this to do nothing more than set the backdrop of my thinking and again reinforce why serverless from a CTO's perspective.
Software Foundations
When building any new software, I feel strongly that it needs to satisfy one of two conditions. It must either be Useful or it must be Fun. If you take any piece of software or tool that you use, it's going to fall into one of those two categories at a high level. And it doesn't matter if you have 1 user or 1B users. You need to deliver on the promise or premise that you set out to do. Customers will expect you to do that if you want to keep them happy. And they will care very little about "how" you do that. Except that what you choose to build your software on will shape their perspective as to some key questions of delivery
- How quickly can I introduce new value?
- How safely can I introduce new value?
- How does this new value affect pricing?
Siding with Serverless
First and foremost I think there is a balance here. The "it depends" answer is the most appropriate for a lot of answers to questions such as "Which x should I choose to build y?". Take for instance the early start-up.
Growing the Team
There are usually only a few employees. Perhaps 3 - 5 develoepers. Maybe 1? I've been there before. Do I go containers? Do I use functions? Do I use a single MySQL or Postgres or venture into running MongoDB? Do I just go with DynamoDB or CosmosDB? So many choices. And you haven't even gotten into the language or frameworks that might run your value on top of these architecture decisions.
Now take a slightly larger software engagement. You've got multiple teams. Ideally, each team is working on its own set of features. Do you standardize that they can only use a certain Database? Do you agree that you'll be event-driven? Do you even agree on the technology and languages that you'll be using?
When faced with all of these potential decisions, especially early on, as a Technology Leader, I'm going to go with the approach that gives me the most flexibility as we scale relative to cost. Let that sink in just a little bit. I'm not picking a side at all, I'm simply saying that I want a design that allows me to adapt to the needs of my customers. That's what I mean by flexibility.
Making some Choices
I've been subconsciously using this quadrant to make decisions for many years but up until I became a CTO, I hadn't codified it.
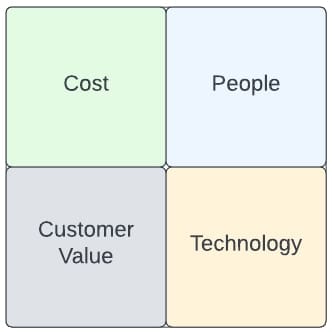
I want to spend the balance of the article now walking through as a CTO how I look at each of these when working with my teams and how we ended up with Serverless.
Quick Definition
Before I go any further, when I say Serverless I mean: A technology service that provides some function without the provisioning of individual compute blocks. The knobs to tune are more parameters of the service vs components of the hardware. And each of the Serverless components that I choose should be interoperable so that I can compose them together to complete a feature.
For instance, I can use AWS Serverless components such as Simple Queue Service and Lambda to batch events and process them with some form of computing. With SQS I worry not about redundancy or server size, but more about batch sizes, encryption and failure. For Lambda, I don't mind the CPU or the host Virtual Machine or even the container, but I do set the memory needed, environment variables and the inputs and outputs that my function code requires.
As many others have stated, it's not the absence of servers that makes it serverless, it's the place in your problem-solving and deployment that makes it so.
Serverless Cost
From a "how much does it cost to run serverless?" point of view, that really depends. And the depends is on so many factors. First and foremost, you MUST understand your serverless component's cost model. For instance:
- Lambda is memory choice / 1ms increments
- DynamoDB is by storage and how you read. Go read Alex's article for something more in-depth
- SQS is by type of queue and the number of pulls. Make sure to use long polling to maximize
- And so on ...
Once you understand how your architecture is coming together, you can understand how to manage its costs. There are so many great stories of people who didn't abandon serverless, only tweaked how they were using a component and reduced their bill or increased their efficiency.
Please make no mistake, if you are just looking at dollars for dollars is serverless cheaper than running bare metal yourself. The answer is almost always no. Again, never with absolutes. You could build your clusters, drop in a messaging solution and run your own Opensource NoSQL datastore and it'll be cheaper as you grow in terms of cost most of the time. Serverless pricing has overhead. On purpose. The entity that runs all this serverless stuff has to make a profit too :)
Serverless People
So why would a CTO choose serverless from a people perspective? For me it's simple. With serverless I spend less time running infrastructure and more time building applications. My customers don't pay for us to run infrastructure by they do pay us for the value we ship. And if I've got 50 people that I can have in a department, I think 5 could be dedicated to Cloud Operations and the other 45 could be leveraged in delivery.
That above breakdown is how I see the beauty of DevOps coming together. Most developers I've ever worked with can't build a network from scratch. They can't rack a server. They can't provision a switch. And why should they? That's not what they've spent their life getting good at. So with Serverless, I don't ask them to. What I ask them to do is learn how to construct these building blocks in a way that delivers their feature. If you've been following me for the past little bit, you know how much I like CDK. Teach your engineers to construct these blocks with the help of the 4 or 5 cloud engineers that can help navigate the complexity and off you go.
What this ends up doing is the money you think you'd save by running your gear, you get to reinvest into your product. I know this to be true because I've gone through several large migrations to serverless that have yielded the redeploying of these former system administrators into roles that helped support product delivery with some of them pivoting into software development on teams.
And lastly, from a people standpoint, I can start to waterline the base set of skills and building blocks that people need to deploy while giving them the freedom to use the tech stack that best fits their problem. For instance, if the base building blocks for an application are DynamoDB, Lambda, EventBridge, Step Functions, SQS then the team can choose to use Go, Node, Python or whatever best suits their problem without being forced into choices because everything is built and deployed in one unit. I find that freedom in this way leads to creativity and innovation. And the isolation of the deployable units decreases the risk. For an example of developers working together, I wrote this article a while back about Event-Driven Serverless Data Architecture
Serverless Customer Value
As a CTO, I spend a lot of time talking to customers and potential customers. And as much as I love technology, most of them don't care too much about what we are built upon. Sure, some get it, and they want to geek out on the latest and greatest. But most really just care about the following things which expands upon the original list at the top:
- How quickly can I introduce new value?
- How safely can I introduce new value?
- How does this new value affect pricing?
- How available are you?
- Do you work on a tablet?
- What software do we need to install?
Here are the things that I've specifically seen with serverless from the perspective of a CTO.
- Scaling to meet demand both up and down
- Time to market on new features
- The resiliency of the platform by being decoupled
- Innovation increased by the isolation of the new features
- Management of cost due to just-in-time sizing of infrastructure.
When addressing customer value, I want to give my teams the building blocks to be able to rapidly build out features while also being able to adapt to scaling changes. I tend to book serverless components in two categories. I have the bedrock components that I know I won't need to outgrow such as SQS, DyanmoDB and EventBridge. And then I have the components that get me going the quickest and will last a long time but might be replaced. Step Functions and Lambdas fall into the this category. I've not reached a scale that requires this in a few places but the upgrade path is easy enough. I lean into Fargate on ECS which gives me plenty of horizontal scale to deal with load that might be more consistent.
So from a team standpoint, they have these robust building blocks and patterns to deploy software and things to monitor that might cause them to jump into a new category of scale. What I want my teams focused on is solving customer problems and shipping customer value, not focused on how they are going to run or deploy. Or trying to hold the mental model of 40 + aggregate roots in a DDD mindsight in their local or brains at one time.
Serverless Technology
Many years ago Jeff Bezos said that AWS seeks to handle 85% of the undifferentiated heavy lifting for its customers. I tend to look at serverless as the next iteration of that statement. Microsoft and Google look to do the same things, so you should be expecting this if you are choosing serverless.
From a technology standpoint, I want to give my teams the ability to pick the right tool for the right job. This doesn't mean to say you CAN'T build a valuable customer product in a Monolith. Because you absolutely can. I spent a lot of years doing this. And then SOA came along and we connected Monotliths together. We haven't changed patterns we've just decreased the size of the feature and the deployment while increasing flexibility and speed.
I mentioned above that it's important to understand the knobs of the piece of tech you are putting in your architecture. Understand how it reads, or pulls, and how it does transactions. Mind the cost and what the overhead is. Also, know what its limits are. When do you go from Lamdba to a container? Or when you might use Step Functions vs crafting your workflow? This goes back to the "it depends" as it always does.
But from a CTO's perspective, why choose serverless continues to boil down to flexibility and speed. I want my teams to be able to be free to make choices that positively impact my customers. And that this technology gives them a delightful experience so that they are spending time working on problems and not working on things that don't add value.
Note on Complexity
So I've highlighted many different opinions on why choose serverless from a CTO's perspective but I would be purely one-sided if I didn't highlight the flip-side of what happens when you choose this style of build. Complexity will increase. Cloud tech in general increases complexity. When your code runs in one executable on 2 servers behind one load balancer with one domain, things are simple. When your transaction runs in the same memory space as the web request, things are simple.
Distributed software is complex. Feel free to read up on that. There are many articles and stories of the pitfalls, and perils but also the successes. Please, with anything you read, find all sides to the point. Then make your own decision based on the quadrant I showed above. Or perhaps you have your criteria which is great too!
Wrap Up
As with anything, there is no one size fits all approach. And when building products or games for customers, it feels like there are too many choices. And sometimes it can feel overwhelming when you hear voices strongly in two camps. I say read those. Don't shy away from them. But then evaluate. With anything, find those that have been cutting the path ahead of you and draft off that success and veer from those failures. Take in all sides and make your own decision. That's honestly as builders what we get paid for. You don't hire a carpenter to build you a fantastic piece of furniture only to tell them how to do it. You let them build and create and use their experience as that's what you are paying them for. If I'm the first to tell you that software development is a similar trade in this day and age, ponder that for a bit.
Thanks so much for reading along. I hope you've taken my perspective as a CTO and have a better understanding as to why I choose Serverless when designing solutions and shipping value.
This content originally appeared on DEV Community and was authored by Benjamen Pyle
Benjamen Pyle | Sciencx (2023-05-13T15:26:47+00:00) Serverless, a CTO’s Perspective. Retrieved from https://www.scien.cx/2023/05/13/serverless-a-ctos-perspective/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.