
This content originally appeared on Level Up Coding - Medium and was authored by Vivien Chua
Traditional methods of processing bank statements can be time-consuming, labor-intensive, and prone to errors. However, with the advent of GPT-3.5 Turbo, there is a solution to this problem. GPT-3.5-Turbo is a large language model that can be applied for use in the financial sector. It can help banks and financial institutions to extract and classify data from bank statements with greater accuracy, speed, and efficiency. In this article, we will explore the capabilities of GPT-3.5-Turbo and examine how it can automate bank statement processing, freeing up valuable time and resources for other critical tasks.
Before we begin, you will need to deploy Python on AWS, sign up for an OpenAI API key and install the Python packages.

Import Python Packages
We begin by importing the required libraries and modules, including openai, gradio, chromadb, and langchain.
import os
import platform
import openai
import chromadb
import langchain
import gradio as gr
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import OpenAI
from langchain.chains import ChatVectorDBChain
from langchain.document_loaders import PyPDFLoader
from langchain.prompts.prompt import PromptTemplate
from langchain.chat_models import ChatOpenAI
Set OpenAI API Key
We set the environment variable OPENAI_API_KEY. You will have to replace the placeholder ‘sk-xxxx’ with your unique OpenAI API key.
os.environ["OPENAI_API_KEY"] = 'sk-xxxx'
Load the Bank Statement
We define a function get_data(), which uses PyPDFLoader() to load and split the data from a PDF document.
def get_data():
loader = PyPDFLoader('bankstatement.pdf')
data = loader.load_and_split()
return data
company_data = get_data()
Convert Document to Embedding
Here, we split the company data into smaller segments, generate vector representations of those parts, and build a vector database using the Chroma library.
text_splitter = RecursiveCharacterTextSplitter()
company_doc = text_splitter.split_documents(company_data)
embeddings = OpenAIEmbeddings()
vectordb = Chroma.from_documents(company_doc, embeddings)
Use System Messages for Chat Completions
In order to produce prompts for the OpenAI language model, we define a prompt template. This template generates prompts that will be used to query the OpenAI language model for answering questions about bank statements.
template = """You are an AI assistant for answering questions about bank statements.
Uppercase and lowercase letters are the same.
Use numbered bullets as required.
Question: {question}
=========
{context}
=========
Answer in Markdown:"""
QA_PROMPT = PromptTemplate(template=template, input_variables=["question", "context"])
Call OpenAI API via LangChain
We create a function generate_response() that takes in two arguments, query and chat history.
The function generates responses to user queries by using the ChatVectorDBChain object and OpenAI model “gpt-3.5-turbo” to find the relevant information in the Chroma vector database.
def generate_response(query,chat_history):
if query:
llm = OpenAI(temperature=0, model_name="gpt-3.5-turbo")
company_qa = ChatVectorDBChain.from_llm(llm, vectordb, return_source_documents=True)
result = company_qa({"question": query, "chat_history": chat_history})
return result["answer"]
Integrate with User Interface
The final step involves creating a user-friendly chatbot interface using the gradio module.
The functions my_chatbot() and gr.Blocks() are utilized in this interface, and their detailed explanations can be found in Hands-On Tutorial: Using OpenAI and Gradio to Create a Chatbot on AWS.
def my_chatbot(input, history):
history = history or []
my_history = list(sum(history, ()))
my_history.append(input)
my_input = ' '.join(my_history)
output = generate_response(input,history)
history.append((input, output))
return history, history
with gr.Blocks() as demo:
gr.Markdown("""<h1><center>My Chatbot</center></h1>""")
chatbot = gr.Chatbot()
state = gr.State()
text = gr.Textbox(placeholder="Hello. Ask me a question.")
submit = gr.Button("SEND")
submit.click(my_chatbot, inputs=[text, state], outputs=[chatbot, state])
demo.launch(share = True)
Test the Model
We have successfully developed a system using GPT-3.5-Turbo to extract and classify data from bank statements. The method can be applied to bank statements from different banks with no uniform formats.
Output from trained GPT-3.5-Turbo is shown below:
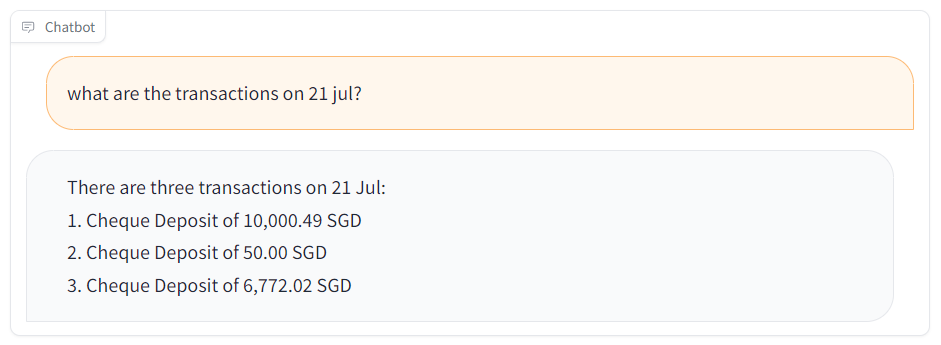
Also read:
- A Beginners Guide to Deploying Python on AWS
- Hands-On Tutorial: Using OpenAI and Gradio to Create a Chatbot on AWS
- Fine-tuning GPT-3 with a Custom Dataset on AWS
Thank you for reading!
If you liked the article and would like to see more, consider following me. I post regularly on topics related to on-chain analysis, artificial intelligence and machine learning. I try to keep my articles simple but precise, providing code, examples and simulations whenever possible.
Level Up Coding
Thanks for being a part of our community! Before you go:
- 👏 Clap for the story and follow the author 👉
- 📰 View more content in the Level Up Coding publication
- 💰 Free coding interview course ⇒ View Course
- 🔔 Follow us: Twitter | LinkedIn | Newsletter
🚀👉 Join the Level Up talent collective and find an amazing job
Bank Statement Processing and Analysis Made Easy with GPT-3.5-Turbo was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Vivien Chua
Vivien Chua | Sciencx (2023-05-16T17:18:56+00:00) Bank Statement Processing and Analysis Made Easy with GPT-3.5-Turbo. Retrieved from https://www.scien.cx/2023/05/16/bank-statement-processing-and-analysis-made-easy-with-gpt-3-5-turbo/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.