
This content originally appeared on Level Up Coding - Medium and was authored by Pragnakalp Techlabs

PaliGemma stands out as a lightweight vision-language model (VLM) that’s freely available. It goes beyond generating simple captions for your images, offering deeper understanding through insightful analysis. Inspired by the PaLI-3 VLM, PaliGemma is built on open-source components like the SigLIP vision model (SigLIP-So400m/14) and the Gemma 2B language model.
PaliGemma’s architecture combines a powerful vision encoder for image analysis with a robust language model for text comprehension. This allows it to take images and text as inputs and deliver detailed answers about the image content.
How It Works
Pre-training on Diverse Datasets: PaliGemma’s knowledge is built upon datasets like WebLI, CC3M-35L, VQ²A-CC3M-35L/VQG-CC3M-35L, OpenImages, and WIT. These datasets equip it with the ability to understand visual concepts, object location, text within images, and even multiple languages!
The Strength of Two Models: PaliGemma leverages the power of two open-source models: SigLIP, a vision model adept at processing images and extracting visual features, and Gemma, a language model that excels at understanding word meaning and relationships.
Fusing Vision and Language: Once SigLIP processes the image and Gemma analyzes the text, PaliGemma merges this information. Its pre-training then takes center stage, allowing it to comprehend the connection between the visual and textual data.
Generating Meaningful Outputs: Finally, PaliGemma utilizes this combined understanding to generate an answer tailored to the task. It can create detailed image descriptions, answer your questions about the image’s content, or identify objects within the picture.
Use Cases
PaliGemma has been trained on a wide range of practical and academic computer vision tasks, showcasing its flexibility and foundational knowledge in adapting to these tasks. Multi-modal VLMs offer versatility in extracting and understanding data from both textual and visual sources, which is essential for most industrial data categories. Here are examples of PaliGemma performing specific tasks:
- Image Captioning: Generating descriptive captions for images.
- Visual Question Answering: Answering specific questions about details in an image.
- Object Detection: Providing bounding box coordinates for objects described in a prompt.
- Object Segmentation: Providing polygon coordinates to segment objects described in a prompt.
Visual Question Answering with PaliGemma
This script demonstrates how to use the Hugging Face Transformers library for PaliGemma inference.
!pip install transformers==4.41.1
PaliGemma requires users to accept a Gemma license, so make sure to go to the repository and ask for access. If you have previously accepted a Gemma license, you will have access to this model as well. Once you have access, log in to Hugging Face Hub using notebook_login() and pass your access token by running the cell below.
from huggingface_hub import notebook_login
notebook_login()
It will prompt you to add your Hugging Face token like this:
You can load the PaliGemma model and processor as shown below.
from transformers import AutoTokenizer, PaliGemmaForConditionalGeneration, PaliGemmaProcessor
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_id = "google/PaliGemma-3b-mix-224"
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16)
processor = PaliGemmaProcessor.from_pretrained(model_id)
import torch
import numpy as np
from PIL import Image
import requests
input_text = "How many persons sitting on lorry?"
img_url = "https://images.fineartamerica.com/images/artworkimages/mediumlarge/1/busy-indian-street-market-in-new-delhi-india-delhis-populatio-tjeerd-kruse.jpg"
input_image = Image.open(requests.get(img_url, stream=True).raw)
The processor preprocesses both the image and text, so we will pass them.
inputs = processor(text=input_text, images=input_image,
padding="longest", do_convert_rgb=True, return_tensors="pt").to("cuda")
model.to(device)
inputs = inputs.to(dtype=model.dtype)
We can provide our preprocessed data as input.
with torch.no_grad():
output = model.generate(**inputs, max_length=496)
print(processor.decode(output[0], skip_special_tokens=True))
# Output:
How many persons sitting on lorry?
2
You can also use this colab to run the above code:
https://colab.research.google.com/drive/1Te-0mw9_vCGm-46b7BULzGATg2PfjidH
Visual Question Answering: PaliGemma vs GPT-4o vs BLIP-2
We compared PaliGemma, GPT-4o, and BLIP-2 by using the same sample images and asking each model the same questions. This helped us see how well each model answers questions about the images and understand their differences in handling visual information.
In Tests 1, 2, and 3, we used common images like people on the ground, a blind person with a cane, and shoes. Test 4 introduced graphs, while Test 5 included document images (invoice).
Test 1:


Test 1: Observation
In this test, PaliGemma and GPT-4o both provided accurate responses. However, BLIP-2’s incorrect count for the first question suggests potential limitations in object recognition.
Test 2:

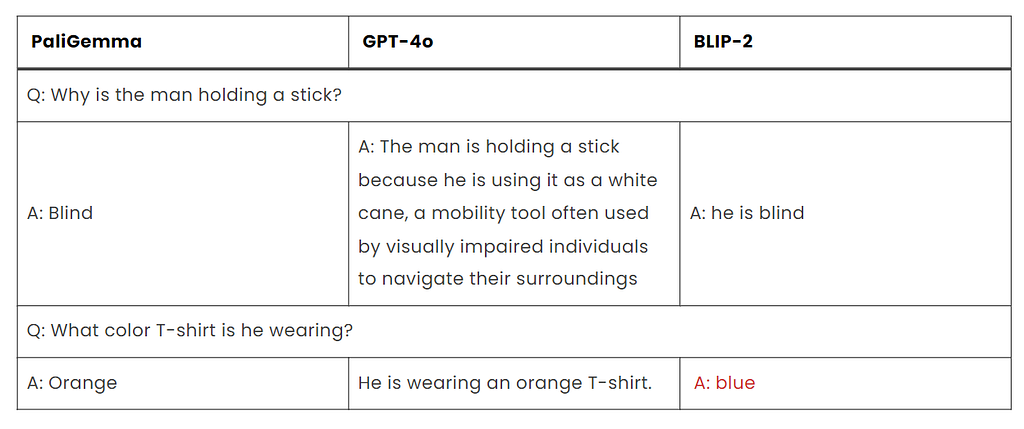
Test 2: Observation
PaliGemma and GPT-4o both provided accurate responses to both questions, with PaliGemma offering concise answers and GPT-4o providing more detailed explanations in some cases.
GPT-4o’s response to the first question stands out for its thoroughness, as it not only answers the question but also provides additional context about the white cane.
BLIP-2’s responses are less accurate, particularly in identifying the color of the T-shirt in the second question, where it provides an incorrect answer.
Test 3:


Test 3: Observation
PaliGemma provides a concise and accurate answer, noting that the shoes are tennis shoes hung to dry. BLIP-2 identifies the shoes as sneakers but does not explain why they are hanging. GPT-4o offers a detailed explanation, identifying the shoes as red sneakers and listing several possible reasons for their hanging, such as cultural practices, pranks, territorial marking, tributes, artistic expression, and urban legends. Overall, PaliGemma gives the most direct and relevant response, BLIP-2 answer is partially complete but lacks detail, and GPT-4o, while thorough, provides more information than necessary.
Test 4:
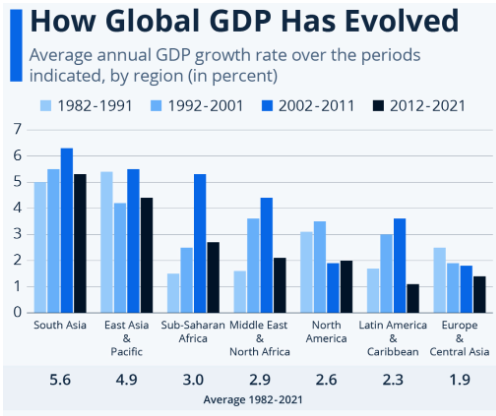
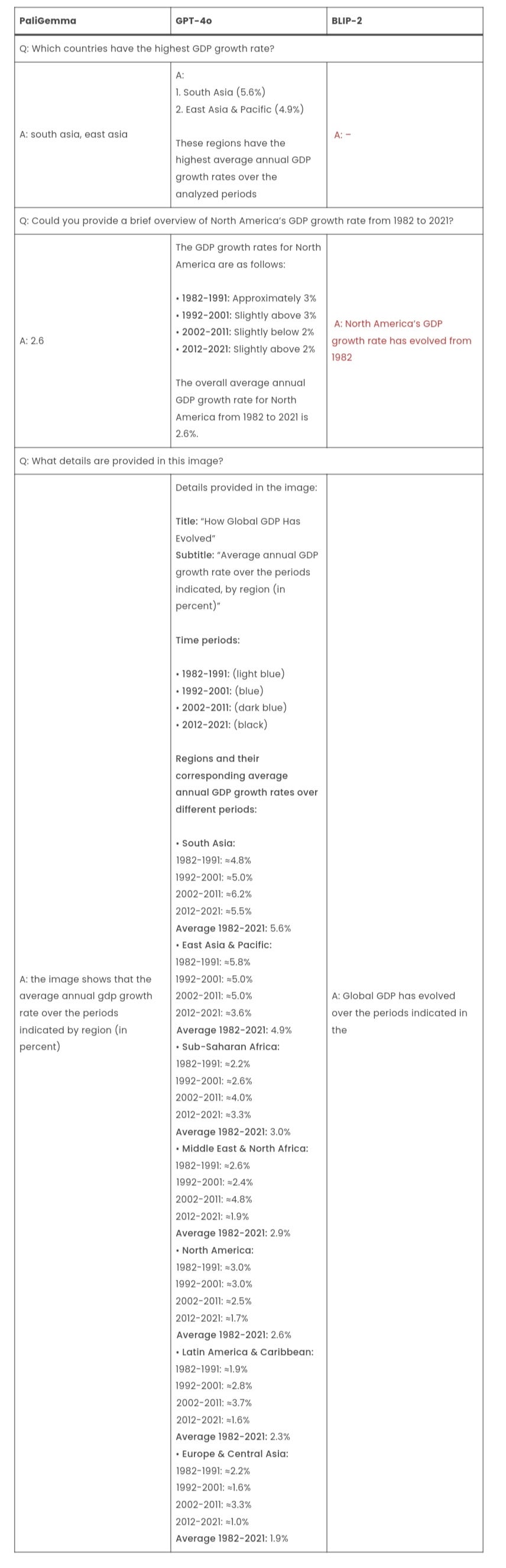
Test 4: Observation
PaliGemma accurately identifies South Asia and East Asia as regions with the highest GDP growth rates. GPT-4o provides a detailed response, including percentages, while BLIP-2 does not provide an answer.
Regarding North America’s GDP growth rate from 1982 to 2021, PaliGemma correctly states it as 2.6% but lacks detail. BLIP-2 is vague, whereas GPT-4o offers a detailed decade-by-decade breakdown, also concluding with an average of 2.6%.
For the last question, PaliGemma accurately summarizes the image content, highlighting the average GDP growth rate by region over time. BLIP-2 provides an incomplete answer, while GPT-4o offers an extensive and detailed description of the image’s contents.
Test 5:
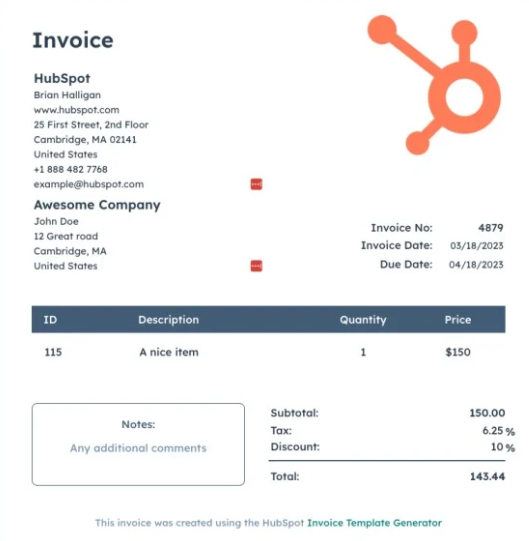
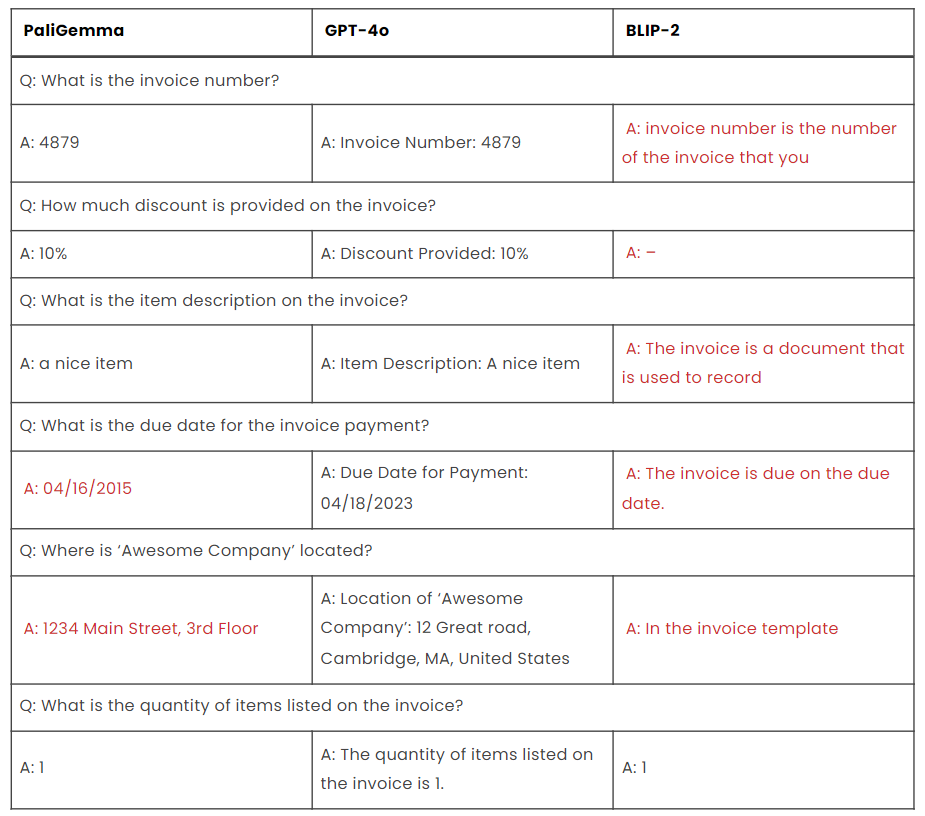
Test 5: Observation
- PaliGemma provides accurate answers for the invoice number, discount percentage, item description, and quantity of items listed on the invoice. However, it provides an incorrect due date for the invoice payment and a wrong address for ‘Awesome Company.’
- GPT 4o consistently provides accurate answers for all questions, including the invoice number, discount percentage, item description, due date for payment, location of ‘Awesome Company,’ and quantity of items listed on the invoice.
- BLIP-2 fails to provide an answer for the discount percentage. It offers vague or irrelevant responses for the item description, due date for payment, and location of ‘Awesome Company.’ However, it correctly identifies the quantity of items listed on the invoice.
PaliGemma is generally good at detecting objects accurately. We have tested it quite a bit, and it usually gets things right, making it useful for identifying the contents of a picture.
Tests conducted for object detection using PaliGemma
- Detecting dogs.

- Detecting Cars.

Conclusion
In summary, PaliGemma stands out for its swift and precise object recognition, which is particularly beneficial for tasks requiring rapid processing. However, it lacks depth in providing detailed explanations for complex queries. Fine-tuning could enhance its performance overall. GPT-4o provides a thorough explanation and a wealth of background information. This is fantastic if you want to learn a lot about something, but occasionally it may give you more irrelevant information than you actually need. BLIP-2 is your go-to for simple questions, but if you have something more challenging, it might stumble and give you inaccurate answers.
Notably, PaliGemma holds an advantage in accurately detecting object locations, a capability lacking in the other two models.
Originally published at PaliGemma: A Lightweight Open-Source VLM For Image Analysis And Understanding on June 5, 2024.
PaliGemma: A Lightweight Open-Source VLM for Image Analysis and Understanding was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Pragnakalp Techlabs
Pragnakalp Techlabs | Sciencx (2024-06-13T20:25:45+00:00) PaliGemma: A Lightweight Open-Source VLM for Image Analysis and Understanding. Retrieved from https://www.scien.cx/2024/06/13/paligemma-a-lightweight-open-source-vlm-for-image-analysis-and-understanding/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.